
Heute starte ich die 30-Tage-DSPy-Challenge. Die Idee ist, jeden Tag ein Stück tiefer in das DSPy-Framework einzutauchen, um am Ende nicht nur zu verstehen, was es kann, sondern es auch wirklich anwenden zu können. Ich möchte herausfinden, ob DSPy wirklich die Art und Weise verändert, wie ich mit großen Sprachmodellen (LLMs) arbeite.
Die Theorie: Warum ich das hier überhaupt mache
Bisher fühlt sich die Arbeit mit LLMs oft wie ein unstrukturiertes Herumprobieren an. Ich habe viel Zeit damit verbracht, Prompts in f-strings zu verpacken, mit Formulierungen zu jonglieren und zu hoffen, dass das Modell das gewünschte Ergebnis liefert. Das ist nicht nur mühsam, sondern auch extrem fragil. Ändert sich das Modell, kann die ganze Arbeit umsonst gewesen sein. Genau hier setze ich meine Hoffnung auf DSPy und seine Kernidee:
„Programming, not Prompting“.
Anstatt Prompts manuell zu optimieren, definiere ich die Bausteine meiner Anwendung programmatisch. Das bedeutet, ich beschreibe die Aufgabe, die das LLM lösen soll – also die Inputs und die gewünschten Outputs – in einer sogenannten Signatur. Anschließend kombiniere ich diese Signaturen in Modulen, um komplexe Abläufe zu erstellen. Das klingt doch einfach – bin schon gespannt ob das auch funktioniert …
Der eigentliche Clou scheint aber der Optimizer (oder „Teleprompter“) zu sein. Dieser kann, mit ein paar Beispieldaten gefüttert, die eigentlichen Prompts für die Module automatisch generieren und optimieren. Das ist fast wie ein Compiler für KI-Anwendungen und DSPy verspricht, die manuelle, fehleranfällige Prompt-Bastelei überflüssig zu machen. Ich erhoffe mir davon robustere und vor allem besser wartbare Systeme.
Die Praxis: Lokales Setup mit Qwen und Llama.cpp
Für den Start möchte ich bewusst nicht auf eine externe API wie die von OpenAI setzen, damit ich auch offline experimentieren kann. Außerdem interessiert mich, ob diese Technik auch mit lokalen LLMs funktioniert. Ich starte erst mal mit dem Qwen3-VL-8B-Instruct-GGUF-Modell. Es ist klein genug, um auf meiner RTX 3080 zu laufen und das GGUF-Format macht es perfekt für die Verwendung mit llama.cpp. Momentan benötige ich die Visual-Fähigkeiten des Modells nicht. Aber evtl. kann ich später auch Bilder in DSPy nutzen?
Projekt und virtuelle Umgebung einrichten
Zuerst schaffe ich mir eine Arbeitsumgebung. Dazu setze ich mit venv eine virtuelle Umgebung auf.
mkdir dspy-challenge
cd dspy-challenge
python -m venv .venv
.\.venv\Scripts\Activate.ps1
DSPy und Llama.cpp installieren
Jetzt kommen die eigentlichen Werkzeuge dran. Ich installiere dspy und llama.cpp. Bei llama.cpp ist es achte ich darauf, die CUDA Version „llama-b6989-bin-win-cuda-12.4-x64.zip“ und die „cudart-llama-bin-win-cuda-12.4-x64.zip“ herunterzuladen um die Leistung meiner RTX 3080 voll auszuschöpfen.
pip install dspyOptional installiere ich mir auch noch jupyterlab. Damit lässt sich deutlich schneller entwickeln als mit einem einfachen Editor und für kleinere Programme und Tutorials ist es eigentlich unverzichtbar.
pip install jupyterlabDas Sprachmodell herunterladen
Ich lade mir das Qwen-Modell von Hugging Face herunter. Ich habe mich für die 4-Bit-Quantisierung entschieden, ein guter Kompromiss zwischen Leistung und Speicherbedarf.
LLama.cpp server starten
Nachdem ich die Zip Dateien entpackt und das die gguf Datei kopiert habe kann ich mit dem folgenden Befehl den llama.cpp Server starten:
llama-b6989-bin-win-cuda-12.4-x64\llama-server -m Qwen3-VL-8B-Instruct-Q4_K_M.gguf
Der llama.cpp Server läuft nun auf Port 8080 und man kann im Browser http://localhost:8080/ eingeben und sollte folgende Seite sehen.
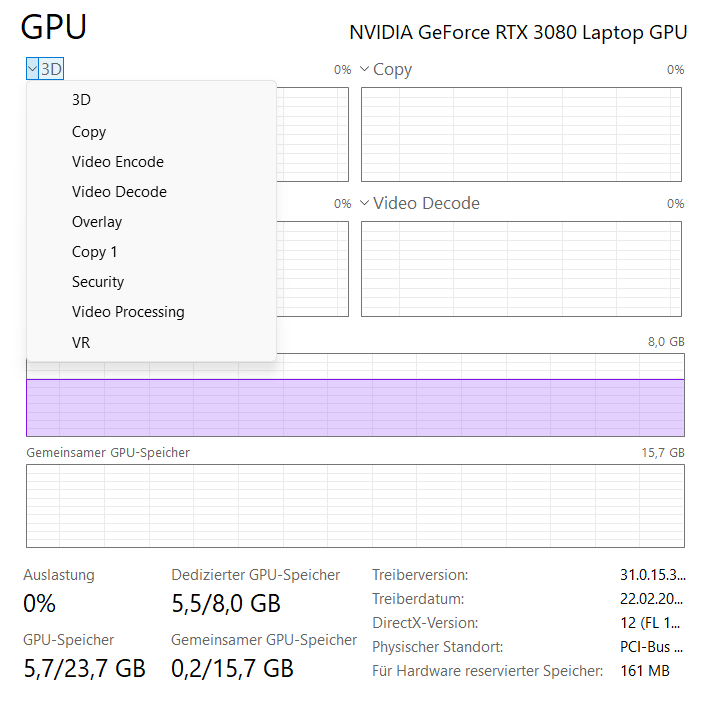
Im Taskmanager kann man sehen, dass etwas 5,5 GB von 8GB VRAM für das Modell benötigt werden. Wie erwartet passt das Qwen Modell gut in den VRAM der RTX 3080.
DSPy mit dem lokalen Modell verbinden
Jetzt kommt der spannendste Teil: Ich schreibe mein erstes kleines Skript, um DSPy mit meinem lokalen Qwen-Modell zu verbinden und zu testen, ob alles funktioniert. Das ist zwar erst morgen dran, aber für einen ersten Test kann es ja nicht schaden 🙂 …
import dspy
local_llm = dspy.LM(
"openai/Qwen3-VL-8B-Instruct-Q4_K_M.gguf",
api_base="http://localhost:8080/v1",
api_key="no_key_needed"
)
dspy.configure(lm=local_llm)# 1. Eine einfache Frage-Antwort-Signatur definieren
class FrageAntwortSignatur(dspy.Signature):
"""Beantworte die gestellte Frage."""
frage = dspy.InputField(desc="eine Frage an das Modell")
antwort = dspy.OutputField(desc="oft zwischen 1 und 5 Wörter")
# 2. Ein Predict-Modul erstellen, das sich Fragen beantworten kann
basic_qa_modul = dspy.Predict(FrageAntwortSignatur)
# 3. Das Modul ausführen
question_to_model = "Wer ist der berühmteste Skateboard Fahrer weltweit?"
ergebnis = basic_qa_modul(frage=question_to_model)
print(f"Question: {question_to_model}")
print(f"Answer: {ergebnis.antwort}")
Question: Wer ist der berühmteste Skateboard Fahrer weltweit?
Answer: Tony HawkDa das Modell nicht extra geladen werden muss und nur über die OpenAI API des llama.cpp Servers angesprochen wird ist das Ergebnis sehr schnell da. So weit funktioniert also alles.
Fazit des ersten Tages
Heute habe ich das theoretische Fundament von DSPy „Programming, not Prompting“ verstanden, eine funktionsfähige, lokale Entwicklungsumgebung aufgesetzt und ein erstes DSPy Programm geschrieben.