Als Software-Entwickler ist man es gewohnt, Probleme durch das Schreiben von Code zu lösen. Man plant Architekturen, liest Spezifikationen und tippt Zeile für Zeile den Code um die Anforderungen in ein Produkt zu übersetzen. Doch seit letztem geistert ein neuer Begriff durch die KI-Tech-Bubble: „Vibe-Coding“. Die Idee dahinter? Anstatt den Code selbst zu schreiben, „dirigiert“ man eine KI durch natürliche Sprache. Man gibt den „Vibe“, die Richtung und die Anforderungen vor, und die KI generiert den Code. Eigentlich ist es nicht viel anders als heute. Man entwickelt den Code in einer Programmiersprache wie C, Java, Go, Python etc. und der Compiler bzw. Interpreter übersetzt den Code in Maschinencode. Der Unterschied ist. dass der „Übersetzer“ kein deterministischer Compiler mehr ist, sondern ein…
Kommentare geschlossenKategorie: Allgemein

Ausgangspunkt war das YouTube-Video, in dem gezeigt wurde, wie man einen Shader nicht nur als Echtzeiteffekt betrachtet, sondern ihn gezielt so umbaut, dass daraus ein Video entsteht. Frame für Frame, mit kontrollierter Zeit. Das Ergebnis: fließende Gegensätze Das entstandene Video lebt von Bewegung, nicht von Formen. · · · · · · Es gibt keine klaren Objekte, keine Kanten, nichts Greifbares. Stattdessen fließen Licht und Farbe ineinander, als würden zwei Strömungen umeinander kreisen. Warme, rötliche Bereiche und kühle, blaue Zonen stehen sich gegenüber, ohne sich jemals wirklich zu trennen. · · · · · · Sie schieben sich ineinander, ziehen sich zurück, verdichten sich kurz und lösen sich wieder auf. Genau dieser ständige Übergang erinnert mich an Yin und Yang.…
Kommentare geschlossen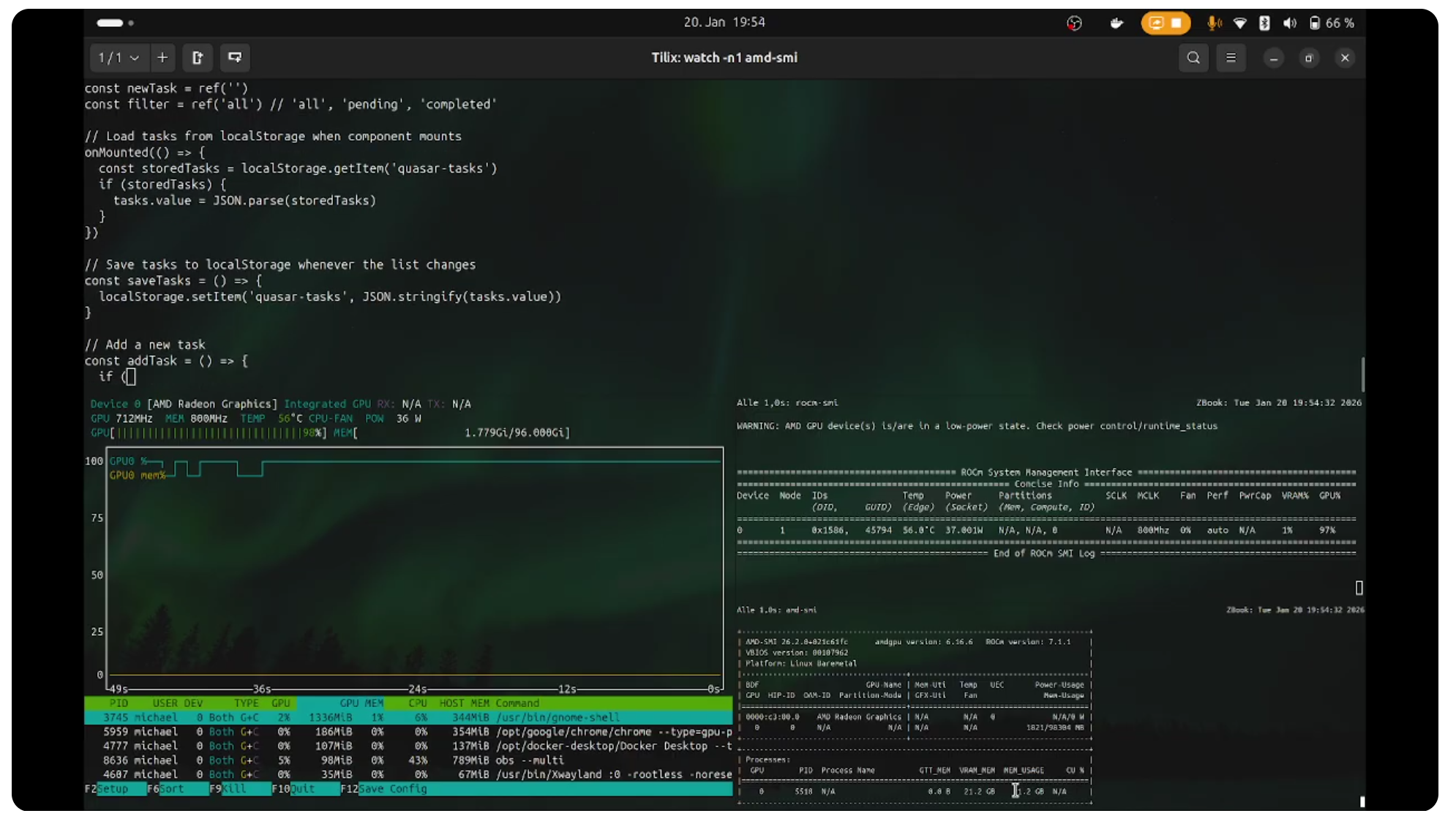
GLM-4.7-Flash ist ein kompaktes Large Language Model, das auf niedrige Latenz und moderate Hardwareanforderungen ausgelegt ist. In Kombination mit Ollama eignet es sich für lokale Inferenzszenarien, bei denen keine Cloud-Anbindung gewünscht oder möglich ist. Ziel dieses Beitrags ist es, die Ausführung von GLM-4.7-Flash auf einer mobilen Workstation objektiv zu dokumentieren und die gemessenen Leistungskennzahlen technisch einzuordnen. Als Testplattform dient ein HP ZBook Ultra G1a mit AMD Ryzen AI Max+ PRO 395. Der Fokus liegt auf der reinen Inferenzleistung, nicht auf Fine-Tuning oder Training. Erforderliche Ollama-Version für GLM-4.7-Flash Für die Ausführung von GLM-4.7-Flash ist eine spezielle Ollama-Version erforderlich. Das Modell nutzt Funktionalitäten, die in stabilen Releases zum Zeitpunkt des Tests noch nicht vollständig verfügbar sind. Aus diesem Grund muss eine Release-Candidate-Version…
Kommentare geschlossen
Quelle: Leviathan et al., Google Research (arXiv:2512.14982) Im Dezember 2025 veröffentlichte Google Research das Paper „Prompt Repetition Improves Non-Reasoning LLMs“. Das Dokument beschreibt eine überraschend triviale Methode, um die Leistung von Large Language Models (LLMs) zu steigern: die einfache Wiederholung des Eingabe-Prompts. Diese Technik erfordert keine Anpassung der Modellarchitektur und kein Fine-Tuning, liefert jedoch messbare Verbesserungen in der Genauigkeit bei Standard-Modellen wie GPT-4, Gemini, Claude und DeepSeek. Kausale Attention und das „Re-Reading“-Phänomen Um die Wirksamkeit von Prompt Repetition zu verstehen, ist ein Blick auf die Architektur moderner LLMs notwendig. Die meisten aktuellen Modelle basieren auf einer „Decoder-only“ Transformer-Architektur mit kausaler Attention (Causal Masking). In einem kausalen Modell darf ein Token bei der Verarbeitung nur auf vorangegangene Token zugreifen (Links-nach-Rechts-Verarbeitung). Das…
Kommentare geschlossen
In den Tagen 27 bis 29 wurde ein System entwickelt, das natürlichsprachliche Fragen in syntaktisch korrekte SQL-Abfragen übersetzt. Das System basiert auf der Architektur ChainOfThought, die das Sprachmodell anleitet, vor der Generierung des SQL-Codes eine logische Herleitung (Reasoning) durchzuführen. Die Kernkomponenten waren: Signatur (TextToSQL)Definition der Eingabefelder (context für das Datenbankschema, question) und des Ausgabefeldes (sql_query). Modul (SQLGenerator)Kapselung der dspy.ChainOfThought-Logik. Optimierung (BootstrapFewShot)Automatisierte Selektion und Generierung von Few-Shot-Beispielen (Demonstrationen) zur Verbesserung der Genauigkeit. Die Implementierung zeigte, dass die Wahl der Validierungsmetrik entscheidend für den Erfolg des BootstrapFewShot-Optimizers ist. Eine reine String-Match-Metrik (answer_exact_match) erwies sich als zu restriktiv, da semantisch korrekte, aber syntaktisch abweichende SQL-Queries (z. B. durch unterschiedliche Alias-Namen oder Formatierungen) als Fehler gewertet wurden. Dies erforderte die Implementierung einer benutzerdefinierten Metrik.…
Kommentare geschlossen
Kennen Sie das? Sie haben die perfekte Prompt im Kopf. Sie sitzen vor dem Bildschirm, die Finger schweben erwartungsvoll über der Tastatur, bereit, die nächste Welle der Produktivität auszulösen. Sie drücken Enter und dann… Nichts. Oder besser gesagt: Ein kleiner, unscheinbarer orangefarbener Punkt und der Satz, der zum Mantra des modernen KI-Nutzers geworden ist: „Dauert länger als gewöhnlich. Versuche es gleich erneut (Versuch 10 von 10)“ Das Warten auf Sonnet 4.5 Ein genauerer Blick auf den Screenshot verrät uns vielleicht, warum die Server gerade schwitzen. Unten rechts blitzt uns verheißungsvoll „Sonnet 4.5“ entgegen. Die digitale Warteschlange ist lang. Die Server glühen. Und ich? Ich starren auf den Zähler. Die Psychologie des Countdowns Es gibt kaum etwas Spannenderes (und Frustrierenderes) als…
Kommentare geschlossen
Die Tage 27 bis 29 der 30-Tage-DSPy-Challenge widmen ich mich der praktischen Anwendung der erlernten Konzepte in einem Abschlussprojekt. In diesem Beitrag werde ich die Umsetzung des SQL-Query-Generators umsetzen. Ziel des Systems ist es, natürlichsprachliche Fragen unter Berücksichtigung eines definierten Datenbankschemas automatisch in syntaktisch korrekte SQL-Abfragen zu übersetzen. Konfiguration der Umgebung Zu Beginn wird die Laufzeitumgebung eingerichtet. Für dieses Projekt kommt ein lokales Sprachmodell (gemma-3-4b-it) zum Einsatz, welches über eine lokale API angesprochen wird. Das Modell läuft in einem llama.cpp Server und kann über localhost Port 8080 mit der OpenAI API angesprochen werden. Definition der Signatur Die Kernkomponente der semantischen Verarbeitung bildet die Signatur TextToSQL. Sie definiert die Schnittstelle zwischen der unstrukturierten Eingabe und der strukturierten Ausgabe. Implementierung des Moduls…
Kommentare geschlossen
Die Entwicklung von spezialisierten Large Language Models (LLMs) für die Softwareentwicklung hat in den letzten Jahren beeindruckende Fortschritte gemacht. Ein neuer Player in dem Spiel ist das Modell NousResearch/NousCoder-14B. Dieses Modell wurde gezielt für die Lösung Programmieraufgaben und die Teilnahme an Programmierwettbewerben (Olympiad Programming) optimiert. Als Open-Source-Alternative bietet es Entwicklern und Unternehmen eine leistungsstarke Basis für automatisierte Code-Generierung und algorithmische Problemlösungen. Einführung in NousResearch/NousCoder-14B Bei NousResearch/NousCoder-14B handelt es sich um ein spezialisiertes Sprachmodell, das auf der Architektur von Qwen2.5-Coder-14B-Instruct basiert. Das primäre Ziel der Entwicklung bestand darin, die Fähigkeiten im Bereich des logischen Schlussfolgerns und der algorithmischen Effizienz zu steigern. Während viele Modelle die Syntax von vielen Programmiersprachen beherrschen, liegt der Fokus hier auf der Bewältigung von Aufgaben, die normalerweise…
Kommentare geschlossenIn den vorangegangenen Tagen lag der Fokus auf der Konstruktion von Modulen, der Integration von Retrieval-Systemen und der Optimierung durch Teleprompter. An Tag 25 und 26 wird der entscheidende Schritt zum Produkt behandelt: Die Kompilierung des DSPy-Programms in ein statisches Artefakt und dessen Speicherung. Ziel dieses Beitrags ist es, den compile-Prozess theoretisch einzuordnen und praktisch anhand eines RAG-Systems (Retrieval Augmented Generation) umzusetzen. Dabei wird demonstriert, wie ein optimierter Zustand gespeichert und in einer neuen Umgebung wiederhergestellt wird. Der Kompilierungsprozess in DSPy In der klassischen Softwareentwicklung übersetzt ein Compiler menschenlesbaren Code in maschinenlesbare Anweisungen. In DSPy bezieht sich der Begriff „Kompilierung“ auf den Prozess, bei dem ein deklaratives Modul (z. B. dspy.ChainOfThought) mithilfe des Teleprompters und eines Trainingsdatensatzes in eine optimierte…
Kommentare geschlossen
In der Entwicklung von Anwendungen auf Basis von Large Language Models (LLMs) stellt die Konsistenz der Ausgaben eine zentrale Herausforderung dar. Während LLMs kreativ und flexibel Text generieren, erfordern Software-Schnittstellen strikte Datenformate und logische Konsistenz. Tag 24 der DSPy-Challenge widme ich mich dem Konzept der Assertions und Validierungen. Ich werde prüfen, wie durch definierte Constraints (Einschränkungen) und Validierungslogik sichergestellt wird, dass extrahierte Daten – wie beispielsweise Preise – den formalen Anforderungen entsprechen. Theorie: Assertions und Selbstkorrektur Der Begriff „Assertion“ beschreibt in der Programmierung eine Aussage, die zu einem bestimmten Zeitpunkt wahr sein muss. Im Kontext von DSPy und LLMs dienen Assertions dazu, Annahmen über die Modellausgabe zu überprüfen. Erfüllt eine Ausgabe die definierten Kriterien nicht (z. B. „Der Preis muss…
Kommentare geschlossen