
Am 13. Tag der Challenge werden die bisher erlernten Konzepte in einem praxisnahen Projekt zusammengeführt. Ziel ist die Entwicklung, Optimierung und Evaluierung eines Text-Klassifikators für Kundenfeedback. Anstatt manuell Prompts zu iterieren, kommt eine vollständige DSPy-Pipeline zum Einsatz, die einen Datensatz, eine definierte Signatur, eine Metrik und den BootstrapFewShot-Optimizer integriert. Dieses Vorgehen ermöglicht eine systematische Steigerung der Modellgenauigkeit. Eigentlich nichts, was ich nicht schon in den letzten Tagen durchgespielt habe. Aber mal sehen, ob ich dabei noch was neues in DSPy entdecke 🙂
Die Qualität der Optimierung in DSPy hängt maßgeblich von der Qualität und Diversität der Trainingsdaten ab. Ein dspy.Example-Objekt verknüpft Eingabedaten (hier: Kundenfeedback) mit den erwarteten Labels (hier: Sentiment). Die Trennung in Trainings- (trainset) und Evaluationsdaten (devset) ist notwendig, um Overfitting zu vermeiden und die Generalisierungsfähigkeit zu messen.
Um es etwas interessanter zu gestalten wähle ich dieses mal den Datensatz bitext/Bitext-customer-support-llm-chatbot-training-dataset. Der Datensatz enthält 26872 Kundensupport-Chatbot Nachrichten. Den Datensatz kann man mit folgendem Befehl laden und die Daten nach Kategorie filtern. Ich wähle hier die Kategorie „ACCOUNT“, die insgesamt 6 Intents hat (‚recover_password‘, ’switch_account‘, ‚create_account‘, ‚delete_account‘, ‚registration_problems‘, ‚edit_account‘).
from datasets import Dataset, load_dataset
dataset = load_dataset("bitext/Bitext-customer-support-llm-chatbot-training-dataset", split="train")
dataset = dataset.filter(lambda x: x["category"] == "ACCOUNT")
dataset = dataset.shuffle(seed=42)Mite den folgenden Zeilen werden die DSPy Examples erstellt. Dabei werden1000 Einträge gewählt und aus ‚instruction‘ und ‚intent‘ das „trainset“ erstellt. Das gleiche passiert mit 100 Einträgen für das ‚devset‘.
import dspy
train_samples = dataset.select(range(1000))
dev_samples = dataset.select(range(1000, 1100))
trainset = [dspy.Example(instruction=ex['instruction'], intent=ex['intent']).with_inputs('instruction') for ex in train_samples]
devset = [dspy.Example(instruction=ex['instruction'], intent=ex['intent']).with_inputs('instruction') for ex in dev_samples]
print(f"Anzahl der Beispiele im Trainingsset: {len(trainset)}")
print(f"Anzahl der Beispiele im Evaluationsset: {len(devset)}")Die Signatur (dspy.Signature) fungiert als Schnittstellenvertrag. Sie definiert semantisch, was das Modell tun soll, sowie die Ein- und Ausgabeformate. Das Modul kapselt die Logik. Für Klassifizierungsaufgaben ist das Standardmodul dspy.Predict oft ausreichend, da es die Signatur direkt in einen Prompt übersetzt.
Es wird eine Klasse für die Signatur und eine Klasse für das Modul implementiert. Dabei übernehme ich die möglichen Werte für den Intent in den Docstring der IntentSignature um dem Modell später eine Orientierung zu geben.
class IntentSignature(dspy.Signature):
"""
Identify the intent of the customer instruction.
Possible values are recover_password, switch_account, create_account, delete_account, registration_problems, edit_account.
"""
instruction = dspy.InputField(desc="Instruction: a user request from the Customer Service domain.")
intent = dspy.OutputField(desc="Intent: the intent corresponding to the user instruction.")
class IntentClassifier(dspy.Module):
def __init__(self):
super().__init__()
self.predictor = dspy.Predict(IntentSignature)
def forward(self, instruction):
return self.predictor(instruction=instruction)Eine Metrik quantifiziert den Erfolg einer Vorhersage. Für Klassifikationsaufgaben eignet sich „Exact Match“ (exakte Übereinstimmung). Die Metrik vergleicht das vorhergesagte Label mit dem Gold-Label aus dem Datensatz. Der Optimizer nutzt diese Metrik, um zu entscheiden, welche Kombinationen von Beispielen (Demonstrationen) im Prompt die besten Ergebnisse liefern
Mit den folgenden Zeilen wird dann das LLM konfiguriert das als Backend für DSPy verwendet wird.
# Konfiguration des lokalen Sprachmodells
local_llm = dspy.LM(
"openai/gemma-3-4b-it-Q4_K_M.gguf",
api_base="http://localhost:8080/v1",
api_key="no_key_needed",
temperature=0.1,
cache=False
)
dspy.configure(lm=local_llm)Definition der Metrik und initiale Messung des unoptimierten Modells.
from dspy.evaluate import Evaluate
# Metrik-Funktion: Vergleicht Vorhersage und Label (case-insensitive)
def exact_match_metric(gold, pred, trace=None):
return gold.intent.lower() == pred.intent.lower()
# Evaluator instanziieren
evaluator = Evaluate(devset=devset, metric=exact_match_metric, num_threads=1, display_progress=True)
# Test des unoptimierten Modells (Zero-Shot)
print("Evaluation vor Optimierung:")
unoptimized_program = IntentClassifier()
evaluator(unoptimized_program, display_table=0)Das unoptimierte Programm („Zero-Shot“) verlässt sich allein auf die semantische Beschreibung in der Signatur. Die Genauigkeit (Accuracy) hängt hier stark von den pre-trainierten Fähigkeiten des Basismodells ab. Das Gemma 3 Modell ist hier scheinbar recht stark, da ohne die Optimierung mit dem ZeroShot Programm schon eine hohe Genauigkeit von 89% erreicht werden kann.
Evaluation vor Optimierung:
Average Metric: 89.00 / 100 (89.0%): 100%| 100/100 [00:45<00:00, 2.21it/s]
Optimierung mit BootstrapFewShot
Der BootstrapFewShot-Optimizer automatisiert das Prompt Engineering. Er durchsucht das trainset und generiert für jeden Datenpunkt Vorhersagen. Wenn eine Vorhersage gemäß der Metrik korrekt ist, wird dieses Paar (Eingabe + korrekte Ausgabe) als potenzielle Demonstration für den Prompt gespeichert. Der Optimizer konstruiert daraus einen „Few-Shot“-Prompt, der dem Modell anhand von Beispielen zeigt, wie die Aufgabe zu lösen ist.
from dspy.teleprompt import BootstrapFewShot
# Konfiguration des Optimizers
# max_bootstrapped_demos: Maximale Anzahl an generierten Beispielen im Prompt
optimizer = BootstrapFewShot(metric=exact_match_metric, max_bootstrapped_demos=4)
# Kompilierung (Optimierung) des Programms mit den Trainingsdaten
print("\nStarte Optimierung...")
optimized_program = optimizer.compile(IntentClassifier(), trainset=trainset)Abschließende Evaluation und Vergleich
Nach der Kompilierung wird das optimierte Programm unter identischen Bedingungen auf dem devset evaluiert.
print("\nEvaluation nach Optimierung:")
evaluator(optimized_program, display_table=0)
# Optional: Inspektion des optimierten Prompts (zeigt die ausgewählten Beispiele)
# dspy.settings.lm.inspect_history(n=1)Die Evaluation liefert einen Score von 96%. Damit ist der Score des optimized_program 7% höher als der des unoptimized_program.
Evaluation nach Optimierung:
Average Metric: 96.00 / 100 (96.0%): 100%| 100/100 [00:39<00:00, 2.50it/s]
INFO dspy.evaluate.evaluate: Average Metric: 96 / 100 (96.0%)
Der Leistungsanstieg resultiert aus dem In-Context Learning. Durch die vom Optimizer eingefügten Demonstrationen (Few-Shot) versteht das Modell die Nuancen der Kategorien (z. B. der Unterschied zwischen „edit_account“ und „create_account“) besser als durch die reine Aufgabenbeschreibung.
Ergänzung
Um etwas detailliertere Insights zu bekommen, welche 4% denn hier zu Problemen geführt haben, kann man sich die Ergebnisse der Evaluation als Confusion-Matrix anzeigen lassen. Dazu müssen noch 2 Python Pakete installiert werden.
pip install matplotlib scikit-learnDas Pakete matplotlib kümmert sich um die Darstellung des Diagramms und scikit-learn um die Erstellung der Confusion Matrix.
Der Code zum Ausführen des Evaluators und zur Ausgabe der Confusion-Matrix ist der folgende.
from dspy.evaluate import Evaluate
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# Evaluator instanziieren
evaluator = Evaluate(devset=devset, metric=exact_match_metric, num_threads=1, display_progress=True)
# Evaluation starten
results = evaluator(optimized_program, display_table=0)
# Confusion-Matrix erzeugen
labels = ['recover_password', 'switch_account', 'create_account',
'delete_account', 'registration_problems', 'edit_account']
cm = confusion_matrix(y_true, y_pred, labels=labels)
# Confusion-Matrix anzeigen
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap=plt.cm.Blues, xticks_rotation=45)
plt.show()Das Ergebnis sieht dann wie folgt aus:
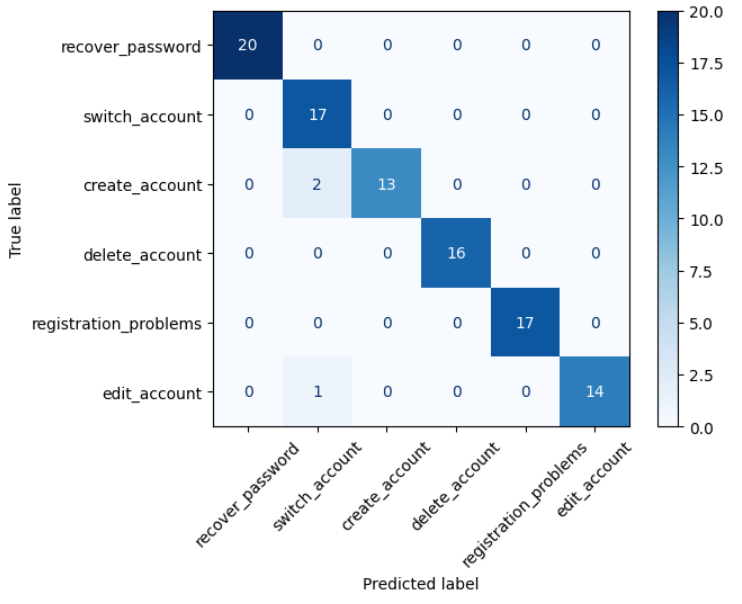
Die Matrix zeigt die Leistung des Modells bei der Vorhersage der Intents. Die Zahlen in der Matrix geben die Anzahl der Beispiele an, die tatsächlich (True label) einem Intent angehören und vom Modell einem bestimmten Intent (Predicted label) zugeordnet wurden. Einige Verwechslungen treten zwischen create_account und switch_account sowie edit_account und switch_account auf. Dies deutet darauf hin, dass das Modell Schwierigkeiten hat, Intents zu unterscheiden, die sich auf Kontoverwaltung beziehen und ähnliche sprachliche Muster enthalten. Alle anderen Intents werden perfekt erkannt.