
TODO für Tag 10
- Einführung in GradientBoostingClassifier
- Unterschied zu Random Forest
Einführung in GradientBoostingClassifier
Der GradientBoostingClassifier in scikit-learn ist ein Klassifikator (Es gibt für die Regression auch einen GradientBoostingRegressor), der auf dem Prinzip des Gradientenboostings basiert. Dabei handelt es sich um eine Methode des Ensemble-Lernens, bei der eine Sequenz von Modellen schrittweise trainiert werden. Jedes neue Modell versucht, die Fehler der vorherigen Modelle zu korrigieren, indem es auf die Residuen (Die Residuen geben an, wie stark das Modell an einer bestimmten Stelle „danebenliegt“) der bisherigen Vorhersagen angepasst wird. Im Laufe der Iterationen entsteht ein zusammengesetztes Modell, das komplexe Zusammenhänge in den Daten erfassen kann.
Beispiel:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score, classification_report
# Synthetische Daten erzeugen (binary classification)
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=15,
n_redundant=5,
random_state=42
)
# Trainings- und Testdaten aufteilen
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3,
random_state=42
)
# Modell erstellen
gbc = GradientBoostingClassifier(
n_estimators=100, # Anzahl Basis-Modelle (Bäume)
learning_rate=0.1, # Lernrate
max_depth=3, # maximale Tiefe der Einzelbäume
random_state=42
)
# Modell trainieren
gbc.fit(X_train, y_train)
# Vorhersagen machen
y_pred = gbc.predict(X_test)
# Ergebnisse auswerten
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))In dem Beispiel wird zuerst wird ein künstlicher Datensatz mit make_classification generiert und dieser anschließend mithilfe von train_test_split in Trainings- und Testdaten aufgeteilt. Danach wird der GradientBoostingClassifier mit spezifischen Hyperparametern initialisiert und auf den Trainingsdaten trainiert.
Nach dem Training macht das Modell Vorhersagen auf den Testdaten. Abschließend werden die Ergebnisse ausgewertet, indem die Gesamt-Accuracy berechnet und ausgegeben wird, sowie ein detaillierter Klassifikationsbericht (mit Precision, Recall, F1-Score pro Klasse) generiert und auf der Konsole ausgegeben wird.
Accuracy: 0.8866666666666667
Classification Report:
precision recall f1-score support
0 0.91 0.87 0.89 160
1 0.86 0.91 0.88 140
accuracy 0.89 300
macro avg 0.89 0.89 0.89 300
weighted avg 0.89 0.89 0.89 300
Die Accuracy beträgt 89%. Dies ist eine gute Leistung und zeigt an, dass der GradientBoostingClassifier die Daten im Allgemeinen gut klassifiziert.
Precision misst die Qualität der Vorhersagen, indem sie den Prozentsatz der korrekt klassifizierten Instanzen innerhalb einer bestimmten Klassenvorhersage misst. Für Klasse 0 beträgt die Precision 0,91, was bedeutet, dass 91 % der Vorhersagen für Klasse 0 richtig waren. Für Klasse 1 beträgt die Precision 0,86, was bedeutet, dass 86 % der Vorhersagen für Klasse 1 richtig waren.
Recall misst die Fähigkeit des Algorithmus, alle Instanzen einer bestimmten Klasse zu erkennen. Für Klasse 0 beträgt der Recall 0,87, was bedeutet, dass 87 % aller tatsächlichen Instanzen von Klasse 0 korrekt klassifiziert wurden. Für Klasse 1 beträgt der Recall 0,91, was bedeutet, dass 91 % aller tatsächlichen Instanzen von Klasse 1 korrekt klassifiziert wurden.
Der F1-Score ist ein Mitelwert zwischen Precision und Recall. Er misst die Balance zwischen den beiden Metriken. Für Klasse 0 beträgt der F1-Score 0,89. -Für Klasse 1 beträgt der F1-Score 0,88.
Der Support gibt die Anzahl an Beispielen jeder Klasse im Datensatz an. In dem Beispiel hat Klasse 0 160 Beispiele und Klasse 1 hat 140 Beispiele im Test-Datensatz. (30% von 1000)
Der Macro Avg berechnet den Durchschnitt der Metriken (Precision, Recall, F1-Score) für jede Klasse und der Weighted Avg berücksichtigt die Verteilung der Klassen im Datensatz.
Man kann den Classifiaction Report mit der folgenden Funktion auch grafisch darstellen.
def plot_classification_report(y_true, y_pred, target_names=None, title='Classification Report'):
# Klassifikationsbericht als Dictionary generieren
report_dict = classification_report(y_true, y_pred, target_names=target_names, output_dict=True)
# Nur die Hauptklassen extrahieren (ohne 'accuracy', 'macro avg', 'weighted avg')
classes = [key for key in report_dict.keys() if key not in ('accuracy', 'macro avg', 'weighted avg')]
metrics = ['precision', 'recall', 'f1-score']
data = []
for cls in classes:
data.append([report_dict[cls][metric] for metric in metrics])
data = np.array(data)
# Plot
fig, ax = plt.subplots(figsize=(8, len(classes) * 1.5))
sns.heatmap(data, annot=True, fmt=".2f", cmap="Blues", cbar=False, ax=ax,
xticklabels=metrics, yticklabels=classes)
ax.set_title(title, fontsize=14)
plt.ylabel('Classes')
plt.xlabel('Metrics')
plt.tight_layout()
plt.show()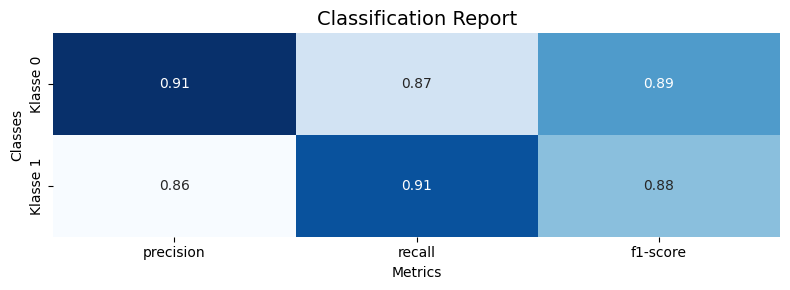
Der GradientBoostingClassifier unterstützt auch Grid-Search (GridSearchCV) und Randomized-Search (RandomizedSearchCV) für Hyperparameter-Optimierung und kann mit Funktionen wie cross_val_score einfach validiert werden.
Hier ein Beispiel, wie man den GradientBoostingClassifier mit RandomizedSearchCV optimieren kann und ihn anschließend mit cross_val_score bewertet.
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, RandomizedSearchCV, cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from scipy.stats import randint, uniform
# Beispiel-Datensatz erzeugen
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=15,
n_redundant=5,
random_state=42
)
# Trainings- und Testdaten splitten
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3,
random_state=42
)
# Modell erstellen
gbc = GradientBoostingClassifier(random_state=42)
# Suchraum für Hyperparameter
param_dist = {
'n_estimators': randint(50, 300),
'learning_rate': uniform(0.01, 0.3),
'max_depth': randint(2, 6),
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 10),
'subsample': uniform(0.6, 0.4)
}
# RandomizedSearchCV Setup
random_search = RandomizedSearchCV(
estimator=gbc,
param_distributions=param_dist,
n_iter=30, # 30 zufällige Kombinationen testen
cv=5, # 5-fache Cross-Validation
verbose=1,
random_state=42,
n_jobs=-1 # alle CPUs verwenden
)
# Hyperparameter-Tuning durchführen
random_search.fit(X_train, y_train)
# Bestes Modell & Report
best_model = random_search.best_estimator_
y_pred = best_model.predict(X_test)
print("Beste Hyperparameter:\n", random_search.best_params_)
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# Modell mit cross_val_score bewerten (auf Gesamt-Daten)
cv_scores = cross_val_score(best_model, X, y, cv=5)
print("Cross-Validation Accuracy (mean):", cv_scores.mean())
print("Cross-Validation Accuracy (std):", cv_scores.std())Dieses Beispiel erzeugt wieder einen synthetischen Datensatz mit 1.000 Samples und 20 Merkmalen, wovon 15 informativ und 5 redundant sind, und teilt diesen anschließend in Trainings- und Testdaten auf. Danach wird ein GradientBoostingClassifier als Basis-Modell definiert und es wird ein Hyperparameter-Suchraum festgelegt, der unter anderem die Anzahl der Entscheidungsbäume, die Lernrate, die maximale Baumtiefe sowie weitere Parameter umfasst, wobei Zufallsverteilungen verwendet werden. Mit RandomizedSearchCV wird dann eine stichprobenartige Suche über 30 zufällige Parameterkombinationen durchgeführt, wobei jedes Modell mit einer 5-fachen Cross-Validation bewertet wird, um die besten Hyperparameter zu finden. Das resultierende, optimierte Modell wird anschließend auf dem Testdatensatz evaluiert, und die Vorhersagequalität wird mit einem Klassifikationsbericht ausgegeben. Abschließend wird das beste Modell nochmals mithilfe einer 5-fachen Cross-Validation über den gesamten Datensatz validiert, um eine robuste Einschätzung der durchschnittlichen Genauigkeit und deren Streuung zu erhalten.
Die Ausgabe des Beispiel-Skripts sieht dann wie folgt aus:
Fitting 5 folds for each of 30 candidates, totalling 150 fits
Beste Hyperparameter:
{'learning_rate': np.float64(0.28279612062363463), 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 9, 'n_estimators': 181, 'subsample': np.float64(0.7246844304357644)}
Classification Report:
precision recall f1-score support
0 0.94 0.91 0.93 160
1 0.90 0.94 0.92 140
accuracy 0.92 300
macro avg 0.92 0.92 0.92 300
weighted avg 0.92 0.92 0.92 300
Cross-Validation Accuracy (mean): 0.929
Cross-Validation Accuracy (std): 0.022226110770892843
Zusätzlich kann man sich auch die Feature Importance anzeigen lassen. Dazu kann man den folgenden Code verwenden:
import matplotlib.pyplot as plt
feature_importance = gbc.feature_importances_
sorted_idx = np.argsort(feature_importance)
plt.barh(range(len(sorted_idx)), feature_importance[sorted_idx])
plt.yticks(range(len(sorted_idx)), sorted_idx)
plt.xlabel("Feature Importance")
plt.title("Gradient Boosting Feature Importances")
plt.show()Der matplotlib Plot dazu seiet wie folgt aus:
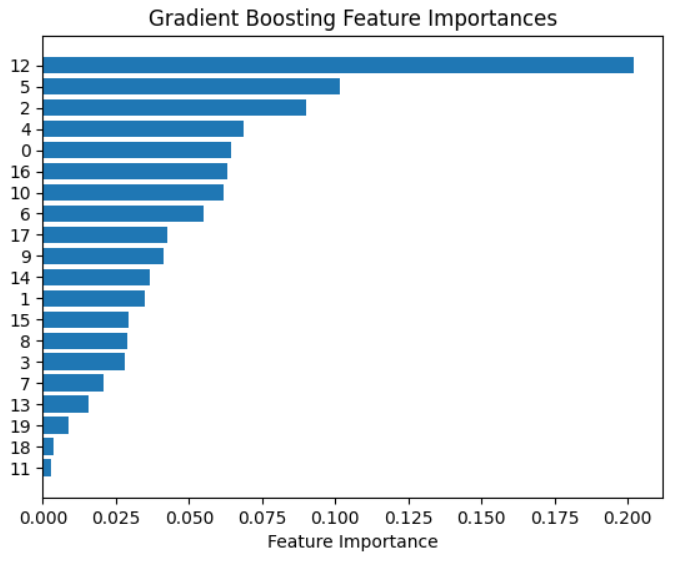
Der Plot zeigt die „Gradient Boosting Feature Importances“. In dem Diagramm wird die relative Bedeutung einzelner Merkmale für das Gradient-Boosting-Modell gbc darstellt. Auf der y-Achse sind die Merkmale durch ihre numerischen Indizes von 0 bis 19 gekennzeichnet, während die x-Achse die jeweilige Feature-Wichtigkeit angibt. Die Balken sind nach ihrer Bedeutung sortiert, wobei das Feature mit der Nummer 12 mit großem Abstand am wichtigsten ist und einen deutlich höheren Wert als alle anderen aufweist. Es folgen die Merkmale 5 und 2 mit mittlerer Wichtigkeit, während viele andere Features nur eine geringe oder nahezu vernachlässigbare Bedeutung haben.
Mit dieser Visualisierung kann man auf einen Blick eine Einschätzung darüber erhalten, welche Features für das Modell am einflussreichsten sind und welche eventuell verzichtbar wären.
Unterschied zu Random Forest
Der Unterschied zwischen dem GradientBoostingClassifier und dem RandomForestClassifier liegt im grundsätzlichen Trainingsprinzip: Random Forest ist ein sogenanntes Bagging-Verfahren, während Gradient Boosting ein Boosting-Verfahren ist.
Beim Random Forest Classifier werden viele Entscheidungsbäume unabhängig voneinander auf einer zufälligen Teilmengen der Daten trainiert und per Mehrheitsentscheid kombiniert. Dadurch reduziert sich die Varianz des Modells erheblich, was zu einer robusten Vorhersage führt. Das Training kann parallelisiert werden, weil die Bäume unabhängig sind, was in der Praxis zu guter Skalierbarkeit führt.
Im Gegensatz dazu baut der GradientBoostingClassifier die Entscheidungsbäume sequenziell auf. Jeder neue Baum wird auf den Fehlern des vorherigen trainiert und korrigiert gezielt die Schwächen der bestehenden Vorhersage. Dadurch entsteht ein stärker fokussiertes Modell mit oft höherer Genauigkeit, allerdings zu höheren Kosten: das Training ist langsamer, schwieriger zu parallelisieren und das Modell ist anfälliger für Overfitting.
In der Praxis bedeutet das: Random Forest ist einfacher zu benutzen, stabiler bei schlechten Hyperparametern und liefert schnell brauchbare Ergebnisse, während Gradient Boosting mehr Feintuning verlangt, dafür aber oft die bessere Genauigkeit liefert, insbesondere bei komplexen Zusammenhängen.
Hier eine Beispiel, dass die beiden Classifier miteinander vergleicht.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# Datensatz erzeugen
X, y = make_classification(n_samples=10000, n_features=20, n_informative=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Random Forest trainieren
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
rf_preds = rf.predict(X_test)
# Gradient Boosting trainieren
gb = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
gb.fit(X_train, y_train)
gb_preds = gb.predict(X_test)
# Ergebnisse vergleichen
print("Random Forest Accuracy:", accuracy_score(y_test, rf_preds))
print("Gradient Boosting Accuracy:", accuracy_score(y_test, gb_preds))In dem Beispiel erreicht der Random Forest eine Accuracy von 92.46% und
Gradient Boosting eine Accuracy von 90.13%. Je nach Datensatz kann es sein, dass Gradient Boosting eine etwas höhere Genauigkeit erreicht, aber das auf Kosten höherer Rechenzeit und größerer Sensibilität gegenüber Parameterwahl. Benötigt man ein schnelles, robustes Modell, ist Random Forest oft die bessere Wahl für einen ersten Wurf. Benötigt man maximale Genauigkeit ist Gradient Boosting meist das Mittel der Wahl. Aber am besten checkt man das mit den eigenen Daten, da das immer abhängig von den Use-Cases und den Daten ist.