
TODO für Tag 17
- Confusion Matrix, Precision, Recall, F1-Score
- classification_report verstehen
Confusion Matrix
Beim Training eines Klassifikationsmodells, das zum Beispiel E-Mails als Spam oder Nicht-Spam einordnet, möchte man visualisieren, wie gut es funktioniert. Eine einfache Prozentzahl der korrekt zugeordneten E-Mails (die Gesamtgenauigkeit) reicht dabei oft nicht aus, denn es gibt verschiedene Arten von Fehlern und richtigen Vorhersagen. Dabei kann die Confusion Matrix helfen.
Die Confusion Matrix ist in den letzten Tagen schon öfter zum Einsatz gekommen. Sie zeigt, wie oft ein Modell eine positive Klasse (z. B. Spam) korrekt als positiv identifiziert hat (True Positives), wie oft es eine negative Klasse (z. B. Nicht-Spam) korrekt als negativ erkannt hat (True Negatives). Aber sie zeigt auch, wie oft das Modell etwas als positiv vorhergesagt hat, obwohl es tatsächlich negativ war (False Positive), und wie oft es etwas als negativ vorhergesagt hat, obwohl es tatsächlich positiv war (False Negative). Die Confusion Matrix zählt einfach die Anzahl der Fälle in jeder dieser vier Kategorien und liefert so einen detaillierten Überblick über das Verhalten des Modells. Scikit-learn bietet eine einfache Funktion, um diese Matrix aus den tatsächlichen Werten und den Vorhersagen Ihres Modells zu berechnen.
Beispiel:
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Dummy-Daten generieren
# 1000 Datenpunkte mit 20 Merkmalen für eine binäre Klassifikation (Spam/Nicht-Spam).
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10,
n_redundant=5, n_clusters_per_class=1,
flip_y=0.25, random_state=42) # random_state sorgt für Reproduzierbarkeit
# Daten in Trainings- und Testsets aufteilen. 25% der Daten zum Testen und 75% zum Trainieren.
# stratify=y stellt sicher, dass das Verhältnis von Klasse 0 zu Klasse 1 in beiden Sets ähnlich ist.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25,
random_state=42, stratify=y)
# Modell auswählen und trainieren
model = LogisticRegression()
model.fit(X_train, y_train)
# Vorhersagen auf dem Testset machen
y_pred = model.predict(X_test)
# Confusion Matrix berechnen
# confusion_matrix vergleicht die tatsächlichen Werte (y_test) mit den vorhergesagten Werten (y_pred).
# Die Reihenfolge der Klassen ist standardmäßig aufsteigend, also 0 (Nicht-Spam), dann 1 (Spam).
cm = confusion_matrix(y_test, y_pred)
# Confusion Matrix darstellen (visualisieren)
class_labels = ['Nicht-Spam', 'Spam'] # Klasse 0 ist Nicht-Spam, Klasse 1 ist Spam
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=class_labels)
# Plotten der Matrix
disp.plot(cmap=plt.cm.Blues) # Wir verwenden eine blaue Farbkarte
plt.title('Confusion Matrix für Spam-Detektor') # Titel hinzufügen
plt.xlabel('Vom Modell vorhergesagte Klasse')
plt.ylabel('Tatsächliche Klasse')
plt.show()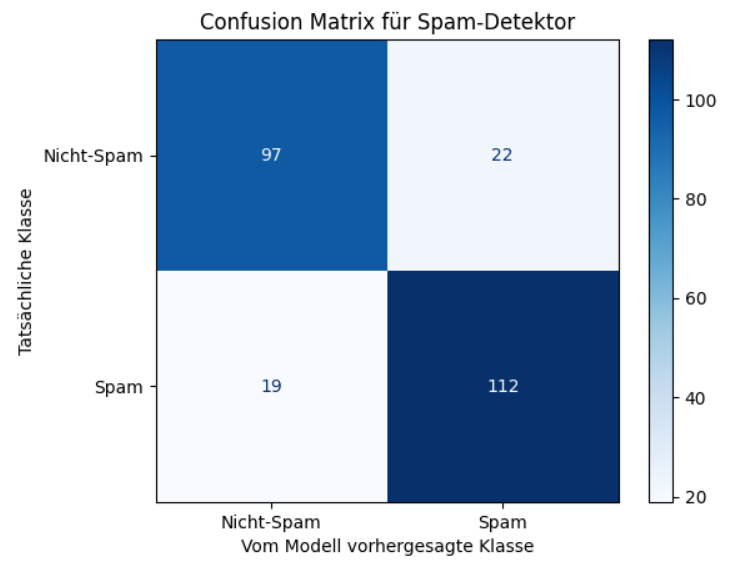
Diese Confusion Matrix visualisiert die Leistung eines Spam-Detektors auf einem Testdatensatz. Sie vergleicht die tatsächlichen Klassen der E-Mails mit den Klassen, die das Modell vorhergesagt hat. Im Detail zeigt die Matrix Folgendes:
- Oben links (97)
Dies sind die True Negatives (TN). Es waren 97 E-Mails, die tatsächlich Nicht-Spam waren und vom Modell korrekt als Nicht-Spam vorhergesagt wurden. - Oben rechts (22)
Dies sind die False Positives (FP). Es waren 22 E-Mails, die tatsächlich Nicht-Spam waren, aber vom Modell fälschlicherweise als Spam vorhergesagt wurden (ein „falscher Alarm“). - Unten links (19)
Dies sind die False Negatives (FN). Es waren 19 E-Mails, die tatsächlich Spam waren, aber vom Modell fälschlicherweise als Nicht-Spam vorhergesagt wurden (Spam, der nicht erkannt wurde). - Unten rechts (112)
Dies sind die True Positives (TP). Es waren 112 E-Mails, die tatsächlich Spam waren und vom Modell korrekt als Spam vorhergesagt wurden.
Die Confusion Matrix zeigt genau auf, wie oft das Modell bei jeder Art von E-Mail (Spam und Nicht-Spam) richtig oder falsch lag und welche Art von Fehlern (falscher Alarm oder übersehener Spam) es gemacht hat.
Precision
Die Precision (Präzision oder Positiver Prädiktiver Wert) beantwortet die Frage: „Wenn mein Modell sagt, etwas ist positiv, wie oft liegt es dann tatsächlich richtig?“ Sie misst also die Genauigkeit der positiven Vorhersagen. Eine hohe Precision ist wichtig, wenn es teuer oder problematisch ist, fälschlicherweise etwas als positiv einzustufen – denken Sie an das fälschliche Blockieren einer wichtigen E-Mail als Spam.
Beispiel:
from sklearn.metrics import precision_score
import numpy as np
# Dummy-Daten erstellen
# 0 = Nicht-Spam (Negative Klasse)
# 1 = Spam (Positive Klasse - die Klasse, für die wir die Precision berechnen wollen)
# Angenommen, die Ergebnisse für 10 E-Mails:
# Tatsächliche Labels: [0, 1, 0, 1, 0, 0, 1, 1, 0, 0]
# Vorhergesagte Labels: [0, 1, 1, 1, 0, 0, 0, 1, 0, 0]
y_true = np.array([0, 1, 0, 1, 0, 0, 1, 1, 0, 0])
y_pred = np.array([0, 1, 1, 1, 0, 0, 0, 1, 0, 0])
print("Tatsächliche Labels (0=Nicht-Spam, 1=Spam):", y_true)
print("Vorhergesagte Labels:", y_pred)
# Precision berechnen mit der Funktion precision_score.
# Der Parameter 'pos_label=1' gibt an, dass die Klasse '1' (Spam) die positive Klasse ist,
# für die wir die Precision berechnen wollen.
# Der Parameter 'average='binary'' ist Standard für binäre Klassifikation, ich gebe ihn der Klarheit halber an.
precision = precision_score(y_true, y_pred, pos_label=1, average='binary')
# Ergebnis ausgeben und interpretieren
print(f"Berechnete Precision (für Klasse 'Spam'): {precision:.4f}")
# Interpretation:
# Laut unseren Dummy-Daten und Vorhersagen:
# Das Modell hat 4 E-Mails als Spam vorhergesagt (die 1en in y_pred).
# Von diesen 4 vorhergesagten Spam-Mails waren tatsächlich 3 Spam (TP = 3).
# Eine E-Mail wurde als Spam vorhergesagt, war aber Nicht-Spam (FP = 1).
# Precision = TP / (TP + FP) = 3 / (3 + 1) = 3 / 4 = 0.75
print(f"\nInterpretation: Von allen E-Mails, die das Modell als 'Spam' vorhergesagt hat ({np.sum(y_pred == 1)} Fälle),")
print(f"waren tatsächlich {np.sum((y_true == 1) & (y_pred == 1))} auch 'Spam'.")
print(f"Die Precision von {precision:.4f} bedeutet, dass 75.00% der als Spam markierten E-Mails tatsächlich Spam waren.")Ausgabe:
Tatsächliche Labels (0=Nicht-Spam, 1=Spam): [0 1 0 1 0 0 1 1 0 0]
Vorhergesagte Labels: [0 1 1 1 0 0 0 1 0 0]
Berechnete Precision (für Klasse 'Spam'): 0.7500
Interpretation: Von allen E-Mails, die das Modell als 'Spam' vorhergesagt hat (4 Fälle),
waren tatsächlich 3 auch 'Spam'.
Die Precision von 0.7500 bedeutet, dass 75.00% der als Spam markierten E-Mails tatsächlich Spam waren.
Recall
Die Recall (auch Sensitivity oder Trefferquote) beantwortet eine andere wichtige Frage: „Von allen tatsächlich positiven Fällen, wie viele hat mein Modell erfolgreich gefunden?“ Sie misst die Fähigkeit des Modells, alle relevanten positiven Instanzen zu erkennen. Ein hoher Recall ist entscheidend, wenn es kritisch ist, keinen positiven Fall zu übersehen – beispielsweise bei der Erkennung von Krankheiten oder Betrugsfällen.
Beispiel:
from sklearn.metrics import recall_score
import numpy as np
# Dummy-Daten
y_true = np.array([0, 1, 0, 1, 0, 0, 1, 1, 0, 0])
y_pred = np.array([0, 1, 1, 1, 0, 0, 0, 1, 0, 0])
# Recall berechnen mit der Funktion recall_score.
# Der Parameter 'pos_label=1' gibt an, dass die Klasse '1' (Spam) die positive Klasse ist
# Der Parameter 'average='binary'' ist Standard für binäre Klassifikation.
recall = recall_score(y_true, y_pred, pos_label=1, average='binary')
# Ergebnis ausgeben und interpretieren
print(f"Berechneter Recall (für Klasse 'Spam'): {recall:.4f}")
# Interpretation:
# Laut der Daten und tatsächlichen Labels:
# Es gab insgesamt 4 E-Mails, die tatsächlich Spam waren
# Von diesen 4 tatsächlichen Spam-Mails hat das Modell 3 korrekt als Spam erkannt (TP = 3).
# Eine tatsächliche Spam-Mail wurde fälschlicherweise als Nicht-Spam vorhergesagt (FN = 1).
# Recall = TP / (TP + FN) = 3 / (3 + 1) = 3 / 4 = 0.75
print(f"\nInterpretation: Von allen E-Mails, die tatsächlich 'Spam' waren ({np.sum(y_true == 1)} Fälle),")
print(f"hat das Modell {np.sum((y_true == 1) & (y_pred == 1))} korrekt als 'Spam' erkannt.")
print(f"Der Recall von {recall:.4f} bedeutet, dass 75.00% des tatsächlichen Spams vom Modell gefunden wurden.")Ausgabe:
Berechneter Recall (für Klasse 'Spam'): 0.7500
Interpretation: Von allen E-Mails, die tatsächlich 'Spam' waren (4 Fälle),
hat das Modell 3 korrekt als 'Spam' erkannt.
Der Recall von 0.7500 bedeutet, dass 75.00% des tatsächlichen Spams vom Modell gefunden wurden.
F1-Score
Oft ist es sowohl wichtig, nicht unnötig „falsch positiv“ zu warnen (Precision) als auch möglichst viele positive Fälle zu finden (Recall). Der F1-Score kombiniert diese beiden Kennzahlen zu einem einzigen Wert. Er ist das harmonische Mittel aus Precision und Recall und bietet somit eine ausgewogene Bewertung, die beide Aspekte berücksichtigt. Ein hoher F1-Score deutet darauf hin, dass das Modell sowohl eine gute Precision als auch einen guten Recall hat. Scikit-learn stellt auch für Precision, Recall und F1-Score direkt nutzbare Funktionen bereit, die diese Werte aus Ihren Vorhersagen und den wahren Labels berechnen, oft sogar für jede Klasse einzeln bei mehr als zwei Kategorien. Diese Metriken zeigt die Leistung eines Klassifikationsmodells als nur eine einzige Genauigkeitszahl.
Beispiel:
from sklearn.metrics import f1_score
import numpy as np
# Dummy-Daten
y_true = np.array([0, 1, 0, 1, 0, 0, 1, 1, 0, 0])
y_pred = np.array([0, 1, 1, 1, 0, 0, 0, 1, 0, 1])
# F1-Score mit der Funktion f1_score berechnen
# pos_label=1 gibt an, dass Klasse '1' (Spam) die positive Klasse ist.
# average='binary' ist für binäre Klassifikation Standard.
f1 = f1_score(y_true, y_pred, pos_label=1, average='binary')
# Ergebnis ausgeben und interpretieren
print(f"Berechneter F1-Score (für Klasse 'Spam'): {f1:.4f}")
# Zum Vergleich Precision und Recall für dieses Beispiel:
precision = precision_score(y_true, y_pred, pos_label=1, average='binary')
recall = recall_score(y_true, y_pred, pos_label=1, average='binary')
print(f"Precision (für Klasse 'Spam'): {precision:.4f}")
print(f"Recall (für Klasse 'Spam'): {recall:.4f}")Ausgabe:
Berechneter F1-Score (für Klasse 'Spam'): 0.6667
Precision (für Klasse 'Spam'): 0.6000
Recall (für Klasse 'Spam'): 0.7500
classification_report verstehen
Der classification_report aus sklearn.metrics ist ein sehr nützliches Werkzeug, um die Leistung eines Klassifikationsmodells zu bewerten. Er gibt eine textbasierte Zusammenfassung der wichtigsten Klassifikationsmetriken für jede Klasse im Datensatz aus. Der Report zeigt Precision, Recall, F1-Score und Support für jede einzelne Klasse an. Außerdem liefert er Durchschnittswerte (macro avg, weighted avg) und die Gesamtgenauigkeit (accuracy) des Modells.
Die Funktion benötigt folgende Hauptargumente:
y_true: Die wahren (korrekten) Labels der Daten.
y_pred: Die vom Modell vorhergesagten Labels.
Optional kann man target_names angeben, um den numerischen Labels aussagekräftige Namen zuzuordnen.
Output (Struktur eines typischen Reports):
precision recall f1-score support
Klasse A 0.80 0.85 0.82 100
Klasse B 0.70 0.65 0.67 80
Klasse C 0.90 0.92 0.91 120
accuracy 0.83 300
macro avg 0.80 0.81 0.80 300
weighted avg 0.81 0.83 0.82 300Precision (Präzision) von allen Instanzen, die das Modell als zu einer bestimmten Klasse vorhergesagt hat, wie viele gehörten tatsächlich zu dieser Klasse? Ein hoher Wert für Klasse A bedeutet, dass wenn das Modell etwas als Klasse A vorhersagt, es sehr wahrscheinlich auch wirklich Klasse A ist (wenige False Positives).
Recall (Sensitivität, True Positive Rate) von allen Instanzen, die tatsächlich zu einer bestimmten Klasse gehören, wie viele hat das Modell korrekt erkannt? Ein hoher Wert für Klasse A bedeutet, dass das Modell die meisten Instanzen der Klasse A auch als solche erkennt (wenige False Negatives).
F1-Score ist das harmonische Mittel von Precision und Recall. Er ist ein guter Gesamtindikator für die Leistung einer Klasse, besonders wenn ein Gleichgewicht zwischen Precision und Recall gesucht wird oder wenn die Klassenverteilung unausgewogen ist. Ein hoher F1-Score (nahe 1) ist gut, ein niedriger (nahe 0) ist schlecht.
Support ist die Anzahl der tatsächlichen Vorkommen jeder Klasse im y_true Datensatz. Dies gibt Kontext zu den anderen Metriken. Wenn eine Klasse nur sehr wenige Samples hat, können die Metriken für diese Klasse weniger zuverlässig sein oder stark schwanken.
Accuracy (Genauigkeit) ist der Anteil der korrekt klassifizierten Instanzen über alle Klassen hinweg. Dies ist die globalste Metrik.
Macro Avg (Macro Average) berechnet die Metrik (Precision, Recall, F1-Score) unabhängig für jede Klasse und bildet dann den ungewichteten Durchschnitt. Jede Klasse trägt also gleich viel zum Durchschnitt bei, unabhängig von ihrem Support. Nützlich, wenn man die Leistung über alle Klassen hinweg gleichmäßig bewerten möchte.
Weighted Avg (Weighted Average) berechnet die Metrik für jede Klasse und bildet dann den Durchschnitt, gewichtet nach dem Support jeder Klasse. Klassen mit mehr Instanzen haben einen größeren Einfluss auf den Durchschnitt. Dies ist oft ein besserer Indikator für die Gesamtleistung bei unausgewogenen Datensätzen.
Wenn eine Klasse viel mehr Beispiele hat als andere, kann die accuracy irreführend sein. Dann konzentriert ,an sich mehr auf die macro avg oder die einzelnen Klassenmetriken. Der weighted avg F1-Score ist oft ein guter Gesamtindikator. Man kann alle Klassen identifizieren, bei denen das Modell schlecht abschneidet (niedrige Precision, Recall oder F1-Score). Dies kann auf Probleme mit diesen spezifischen Klassen hindeuten (z.B. zu wenige Daten, schwer zu unterscheidende Merkmale).
Wenn es sehr wichtig ist, False Positives zu vermeiden (z.B. Spam-Filter: eine normale E-Mail fälschlicherweise als Spam markieren), ist eine hohe Precision wichtiger. Wenn es sehr wichtig ist, False Negatives zu vermeiden (z.B. medizinische Diagnose: eine Krankheit übersehen), ist ein hoher Recall wichtiger. Der F1-Score versucht, beide Aspekte auszubalancieren.
Python-Beispiel:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# Beispieldaten generieren und Train Test Split
X, y = make_classification(n_samples=1000, n_features=20, n_classes=3,
n_informative=5, random_state=42, n_redundant=5, n_clusters_per_class=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# LogisticRegression Modell erstellen und trainieren
model = LogisticRegression(solver='liblinear', multi_class='ovr', random_state=42)
model.fit(X_train, y_train)
# Vorhersagen über den Testdantensatz machen
y_pred = model.predict(X_test)
# Klassifikationsreport erstellen
# target_names sind optional, aber hilfreich für die Lesbarkeit
class_names = ['Klasse Alpha', 'Klasse Beta', 'Klasse Gamma']
report_str = classification_report(y_test, y_pred, target_names=class_names)
print("Classification Report (Text):\n", report_str)
# Klassifikationsreport als Dictionary für die Visualisierung
report_dict = classification_report(y_test, y_pred, target_names=class_names, output_dict=True)
# DataFrame für die Visualisierung erstellen.
# Extrahieren von Precision, Recall und F1-Score für jede Klasse (ohne die Durchschnittswerte)
metrics_data = []
for class_name in class_names:
metrics_data.append([
report_dict[class_name]['precision'],
report_dict[class_name]['recall'],
report_dict[class_name]['f1-score']
])
# Umwandlung in ein Pandas DataFrame
metrics_df = pd.DataFrame(metrics_data, columns=['Precision', 'Recall', 'F1-Score'], index=class_names)
# Visualisierung des Classification Reports als Heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(metrics_df, annot=True, cmap="viridis", fmt=".2f", linewidths=.5)
plt.title('Classification Report Metriken pro Klasse')
plt.ylabel('Klassen')
plt.xlabel('Metriken')
plt.xticks(rotation=45)
plt.yticks(rotation=0)
plt.tight_layout()
plt.show()
# Bar-Chart für einen besseren Vergleich der Metriken pro Klasse
metrics_df_for_barplot = metrics_df.reset_index().melt(id_vars='index', var_name='Metrik', value_name='Wert')
metrics_df_for_barplot.rename(columns={'index': 'Klasse'}, inplace=True)
plt.figure(figsize=(12, 7))
sns.barplot(x='Klasse', y='Wert', hue='Metrik', data=metrics_df_for_barplot, palette='viridis')
plt.title('Vergleich der Klassifikationsmetriken pro Klasse')
plt.ylabel('Score')
plt.xlabel('Klasse')
plt.ylim(0, 1.05) # Y-Achse von 0 bis 1.05 für bessere Darstellung
plt.legend(title='Metrik')
plt.tight_layout()
plt.show()
# Zusätzliche Informationen aus dem Report, die man auch visualisieren könnte:
# - Support pro Klasse (z.B. als Teil des Bar-Charts oder separate Darstellung)
# - Accuracy, Macro Avg, Weighted Avg (könnten in einer Tabelle neben dem Plot oder als separate kleinere Plots dargestellt werden)
# Beispiel für die Darstellung der Support-Werte zusammen mit dem F1-Score
f1_scores = [report_dict[cn]['f1-score'] for cn in class_names]
supports = [report_dict[cn]['support'] for cn in class_names]
fig, ax1 = plt.subplots(figsize=(10, 6))
# Bar-Chart für F1-Scores
color = 'tab:blue'
ax1.set_xlabel('Klasse')
ax1.set_ylabel('F1-Score', color=color)
ax1.bar(class_names, f1_scores, color=color, alpha=0.6, label='F1-Score')
ax1.tick_params(axis='y', labelcolor=color)
ax1.set_ylim(0, 1.05)
# Zweite Y-Achse für Support-Werte
ax2 = ax1.twinx()
color = 'tab:red'
ax2.set_ylabel('Support (Anzahl Samples)', color=color)
ax2.plot(class_names, supports, color=color, marker='o', linestyle='--', label='Support')
ax2.tick_params(axis='y', labelcolor=color)
fig.tight_layout()
plt.title('F1-Score und Support pro Klasse')
# Legenden kombinieren (etwas umständlich in matplotlib für twin axes)
lines, labels = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines + lines2, labels + labels2, loc='upper center')
plt.show()Dieses Python-Beispiel zeigt einen vollständigen Workflow zur Bewertung eines Klassifikationsmodells, beginnend mit der Generierung synthetischer Daten mittels make_classification incl. Aufteilung in Trainings- und Testsets. Anschließend wird ein logistisches Regressionsmodell trainiert, und es werden Vorhersagen auf den Testdaten gemacht, um dann den classification_report zu erstellen.
Die Metriken Precision, Recall und F1-Score werden zur Erstellung von verschiedenen Visualisierungen ermittelt.
- Einer Heatmap, die diese Metriken pro Klasse darstellt
- Ein gruppiertes Balkendiagramm zum Vergleich derselben Metriken
- Ein kombiniertes Diagramm, das F1-Scores als Balken und die Support-Werte als Linienplot mit zwei Y-Achsen anzeigt Damit wird die Modellleistung anschaulich visualisiert.
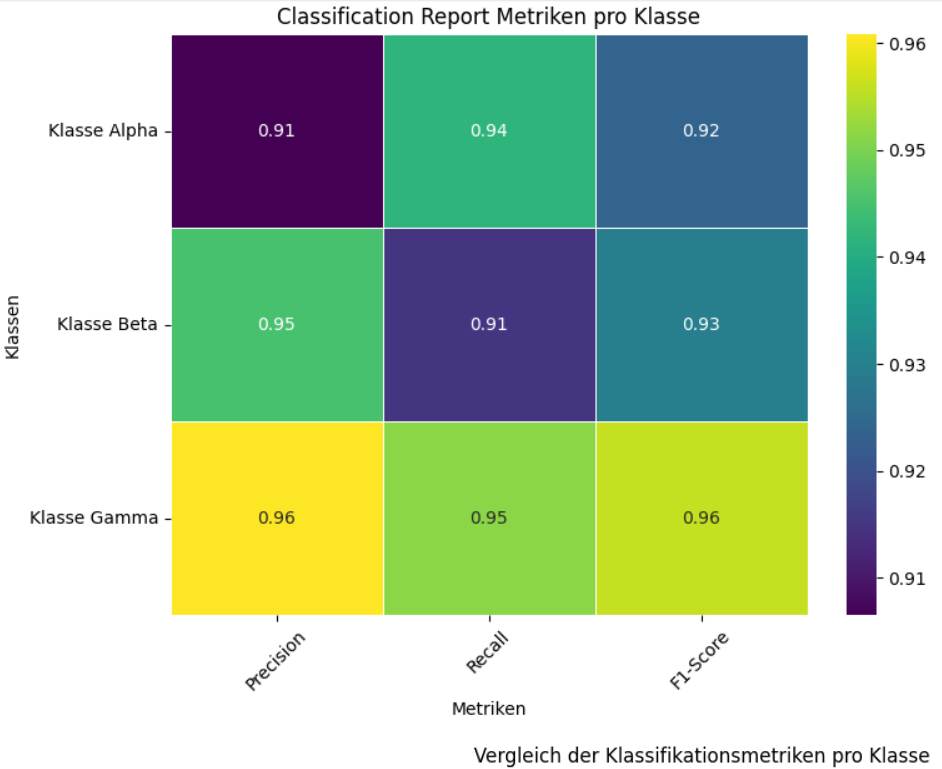
Das folgende Bild zeigt die Heatmap, die die Leistung eines Klassifikationsmodells für drei verschiedene Klassen – „Klasse Alpha“, „Klasse Beta“ und „Klasse Gamma“ – anhand der Metriken Precision, Recall und F1-Score visualisiert. Die Werte in den Zellen, die durch unterschiedliche Farben von tiefem Violett bis hin zu leuchtendem Gelb dargestellt werden, reichen von 0.91 bis 0.96, was auf eine allgemein hohe Leistung des Modells über alle Klassen und Metriken hinweg hindeutet. Beispielsweise erzielt „Klasse Alpha“ eine Precision von 0.91, einen Recall von 0.94 und einen F1-Score von 0.92, während „Klasse Gamma“ durchweg hohe Werte um 0.95-0.96 in allen drei Metriken aufweist.
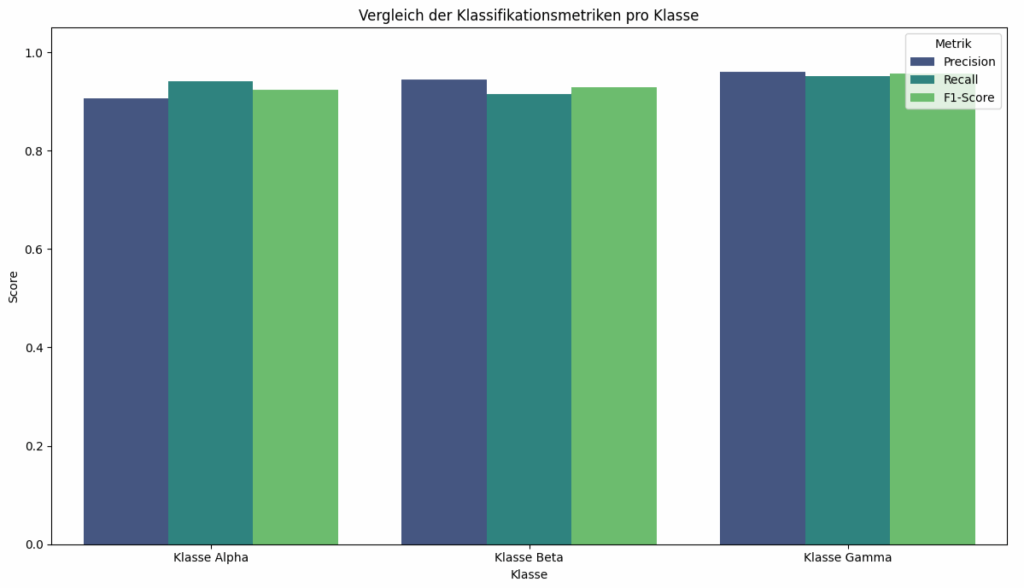
Das Balkendiagramm stellt die Leistungskennzahlen Precision, Recall und F1-Score für drei verschiedene Klassen – „Klasse Alpha“, „Klasse Beta“ und „Klasse Gamma“ – dar, wobei jede Metrik durch eine eigene Farbe repräsentiert wird. Alle dargestellten Scores liegen im oberen Bereich der Skala, was auf eine hohe Modellleistung hindeutet. Das Balkendiagramm ermögliche einen direkten visuellen Vergleich der Metriken zwischen den Klassen.
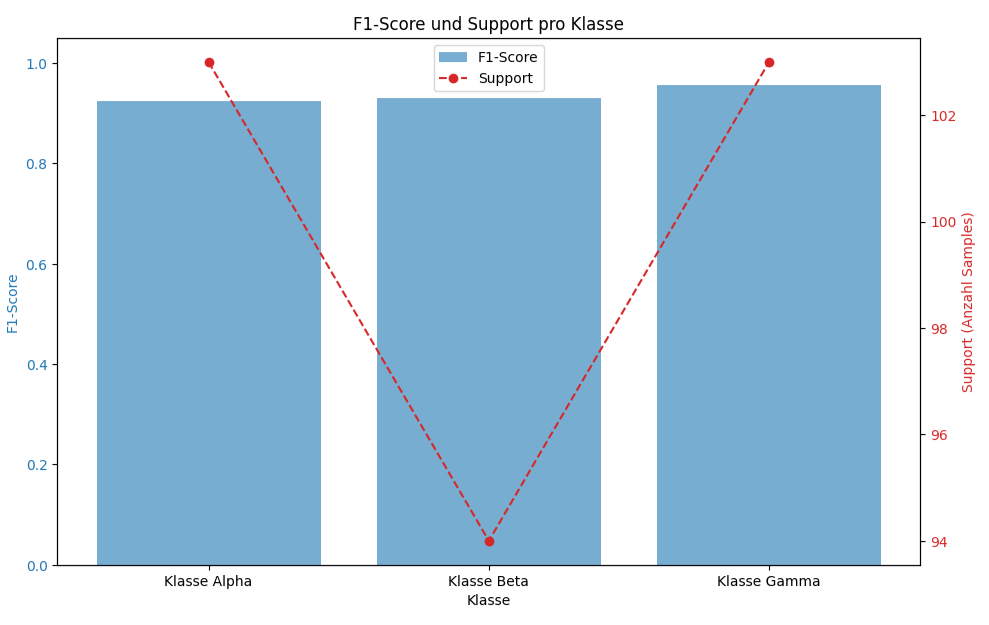
Das letzte Diagramm visualisiert zwei Metriken für die Klassen „Alpha“, „Beta“ und „Gamma“ mithilfe einer kombinierten Darstellung. Die F1-Scores werden als hellblaue Balken dargestellt und auf der linken Y-Achse abgetragen, während der Support als rote, gestrichelte Linie mit Punkten auf der rechten Y-Achse angezeigt wird. Alle drei Klassen weisen hohe F1-Scores von über 0.9 auf, wobei „Alpha“ einen F1-Score von etwa 0.92 und einen Support von ca. 102 hat, „Beta“ den niedrigsten F1-Score von ungefähr 0.93 bei dem geringsten Support von 94 aufweist, und „Gamma“ den höchsten F1-Score von circa 0.95 sowie den höchsten Support von rund 103 zeigt, was eine mögliche Korrelation zwischen der Anzahl der Samples und der Modellleistung andeutet, obwohl alle F1-Scores generell hoch sind.
Der classification_report ist ein Werkzeug, mit dem man eine umfassende Zusammenfassung der Leistungsfähigkeit eines Klassifikationsmodells erstellen kann, indem es wichtige Metriken wie Precision, Recall, F1-Score und Support für jede einzelne Klasse sowie wichtige Durchschnittswerte und die Gesamtgenauigkeit darstellt. So ermöglicht es eine detaillierte Analyse, die über die reine Genauigkeit hinausgeht und hilft bei der Identifizierung von Stärken und Schwächen des Modells bezüglich spezifischer Klassen und bildet somit eine solide Grundlage für fundierte Entscheidungen zur Modellauswahl und Hyperparameter-Optimierung.