
Das Buch „Websites entwickeln mit KI: Konzeption, Umsetzung und Optimierung“ von Jens Jacobsen aus dem Rheinwerk Verlag, ist ein umfassender Leitfaden für alle, die moderne KI-Tools nutzen möchten, um professionelle Websites zu erstellen. Jens Jacobsen führt die Leser durch einen strukturierten 7-Schritte-Prozess, der von der Konzeption bis zur Vermarktung einer Website reicht. Dabei legt er besonderen Wert auf die praktische Anwendung von KI, ohne dass technische Vorkenntnisse erforderlich sind. Mit einer klaren Sprache, praxisnahen Beispielen und einer Vielzahl von praktischen Prompts bietet das Buch sowohl Anfängern als auch erfahrenen Webentwicklern wertvolle Einblicke in die Möglichkeiten der KI-gestützten Webentwicklung. Das Buch ist in sieben Hauptkapitel gegliedert, die jeweils einen Schritt im Prozess der Website-Erstellung abdecken. In diesen Kapiteln wird theoretisches Wissen…
Kommentare sind geschlossenjentsch.io Beiträge

Seit jeher strebt der Mensch danach, die Grenzen des Machbaren zu verschieben. In früheren Jahrhunderten versuchten Alchemisten, das Unmögliche zu erreichen: die Umwandlung von unedlen Metallen wie Blei in Gold oder die Entdeckung des Steins der Weisen – einer Substanz, die ewiges Leben und universelles Wissen versprach. Diese Forschung wirkt aus heutiger Sicht eher esoterisch, doch sie war Ausdruck eines tief verankerten menschlichen Drangs, die Kontrolle über grundlegende Prinzipien der Natur zu erlangen. In gewisser Weise zeigt sich dieser Drang heute erneut in der Forschung rund um allgemeine künstliche Intelligenz, kurz AGI. Die Idee, eine Maschine zu schaffen, die nicht nur spezifische Aufgaben erledigt, sondern über ein umfassendes Verständnis der Welt verfügt, wirkt in ihrer Tragweite vergleichbar mit dem alchemistischen…
Kommentare sind geschlossen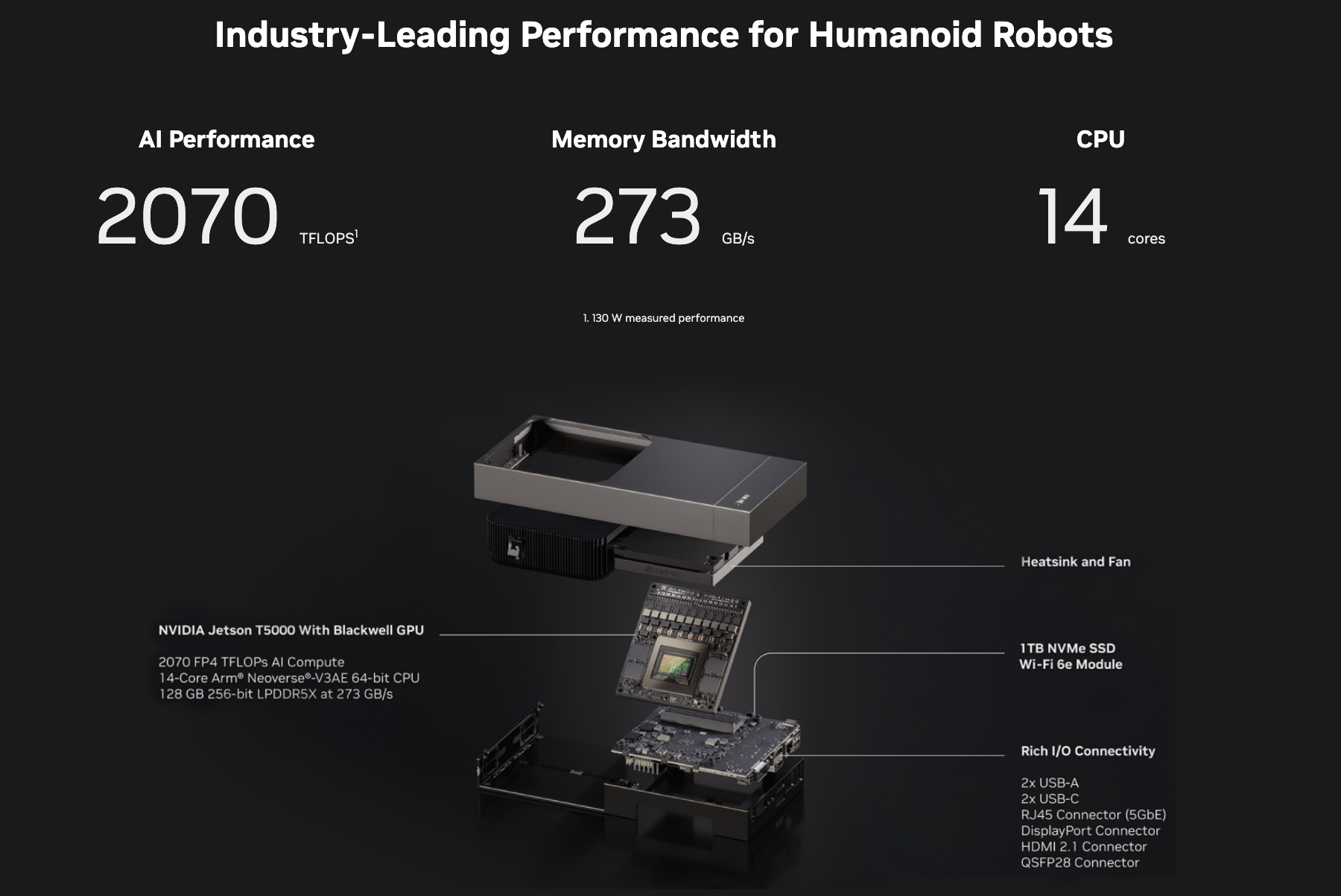
NVIDIA hat mit dem Jetson AGX Thor Developer Kit eine Plattform angekändigt, die verspricht, die Entwicklung von humanoiden Robotern und physikalischer KI neu zu definieren. Das NVIDIA® Jetson AGX Thor™ Developer Kit ist ein gewaltiger Sprung nach vorne der das NVIDIA Jetson AGX Orin 64GB Developer Kit bei weitem übertrifft. Das Herzstück des Jetson AGX Thor hat eine unglaubliche KI-Leistung. Mit bis zu 2070 FP4 TFLOPS (Tera-Floating-Point-Operations-Per-Second) bietet das Kit eine Rechenleistung, die speziell für die neuesten generativen KI-Modelle ausgelegt ist. Diese enorme Leistung wird durch die neue NVIDIA Blackwell-Architektur ermöglicht, die im Jetson T5000-Modul mit 2560 Kernen und 96 Tensor Cores der fünften Generation zum Einsatz kommt. Im Vergleich zum bereits leistungsstarken Vorgänger, dem Jetson AGX Orin, liefert Thor…
Kommentare sind geschlossen
Pocket – ursprünglich „Read It Later“ – wurde im August 2007 von Nate Weiner als Browser-Erweiterung gestartet, um gespeicherte Artikel später zu lesen. 2017 übernahm Mozilla den Dienst, mit dem Ziel, ihn als integralen Teil seiner Content-Empfehlungen weiterzuentwickeln. Über die Jahre wuchs Pocket zu einer Plattform mit Millionen Nutzern und wurde sowohl wegen seiner Reader-Funktion als auch seiner kuratierten Empfehlungen geschätzt. Doch nun ist der Dienst abgeschaltet und es bleibt nur eine Export Funktion mit der man die gespeicherten URLs als CSV Datei exportieren kann. Ich habe Read It Later und GetPocket eigentlich täglich genutzt und immer wieder Artikel mit der Browser-Erweiterung oder der Android App gespeichert und später offline gelesen. Meist in der Bahn auf dem Weg zur Arbeit…
Kommentare sind geschlossen
Tag 30 ist erreicht! Die vergangenen Wochen waren eine spannende Reise durch die Welt des maschinellen Lernens mit scikit-learn. Die heutige Aufgabe ist es, möglichst viel von dem gelernten in einem eigenen Projekt zu bündeln. Für das Projekt greife ich auf einen alten Datensatz zurück. Dabei handelt es sich um die IMU-Daten (Inertial Measurement Unit) eines Projektes das leider nicht erfolgreich beendet wurde. Gemeinsam mit zwei Freunden haben wir versucht, mittels des 6-Achsen-Sensors von Google Wear-OS Watches verschiedene Fitnessübungen (Liegestützen, Bizeps Curls, etc.) in Echtzeit auf dem Handy zu erkennen, Wiederholungen zu zählen und Nutzern Tipps zur Erreichung der Trainingsziele zu geben. Auch wenn das Projekt leider nicht den erhofften Erfolg hatte, leben die Daten und die Idee weiter. Für das…
Kommentare sind geschlossenTODO für Tag 29 Einführung in Multi-Output Methoden Beim Maschine Learning ist es oft die Aufgaben, eine einzelne Zielvariable vorherzusagen. Es gibt jedoch Szenarien, in denen es notwendig ist, mehrere Zielvariablen gleichzeitig aus denselben Eingabemerkmalen zu prognostizieren. Diese Art von Problemstellung wird als Multi-Output-Vorhersage bezeichnet und kann sowohl Regressions- als auch Klassifikationsaufgaben umfassen. Anstatt für jede Multi-Output-Aufgabe völlig neue Algorithmen zu implementieren, verfolgt scikit-learn einen flexiblen Ansatz. In scikit-learn kann man dies mit den Meta-Estimators oder Wrappern ermöglichen. Einige der Single-Output-Estimators kann man für Multi-Output-Szenarien anpassen. Ein simple Alternative besteht darin, für jede Zielvariable ein eigenes, unabhängiges Modell zu trainieren und die Vorhersagen dann zu aggregieren. Darüber hinaus unterstützen einige Algorithmen in scikit-learn von Hause aus die Vorhersage mehrerer Ausgaben.…
Kommentare sind geschlossenTODO für Tag 28 Komplexere Pipelines mit Preprocessing-Schritten Das Preprocessing in scikit-learn habe ich in den vorherigen Übungen (Tag 13, Tag 15, Tag 19, Tag 21, etc.) schon ausreichend behandelt und das Prinzip sollte klar sein. Aber die Datenvorbereitung kann vielfältige Formen annehmen. Neben den üblichen Verdächtigen wie Imputationsstrategien zum Umgang mit fehlenden Daten, dem TfidfVectorizer zum Extrahieren gewichteter Textmerkmale oder der Skalierung Numerische Features um sicherzustellen, dass Modelle nicht durch unterschiedliche Wertebereiche beeinflusst werden, gibt es noch viele andere Preprocessing-Schritte die man anwenden kann. Für kategorische Daten ist z.B. eine Umwandlung in ein numerisches Format notwendig (One-Hot-Encoding). Hierfür wird für jede Kategorie eine neue binäre Spalte erstellt. Ein Thema, dass ich aber im Zusammenhang mit dem Preprocessing in einer…
Kommentare sind geschlossenTODO für Tag 27 ROC-Kurve plotten und AUC berechnen (roc_auc_score) Die ROC Kurve (Receiver Operating Characteristic Kurve), ist ein grafisches Werkzeug, das die Leistungsfähigkeit eines binären Klassifikationsmodells über verschiedene Schwellenwerte hinweg visualisiert. Auf der y Achse wird die Sensitivität oder Trefferquote abgetragen, während die x Achse die False-Positiv-Rate darstellt. Eine Diagonale von links unten nach rechts oben repräsentiert die Leistung eines Zufallsklassifikators. Die Fläche unter dieser Kurve, bekannt als AUC (Area Under the Curve), dient als zusammenfassendes Maß für die Modellgüte über alle Schwellenwerte hinweg; ein höherer AUC Wert, idealerweise nahe 1, deutet auf eine bessere Unterscheidungsfähigkeit des Modells hin. Um eine solche Kurve mit der Python Bibliothek scikit learn zu erstellen, benötigt man zunächst die wahren Zielwerte und die…
Kommentare sind geschlossen
Die Entwicklung von Webapplikationen mit Spring Boot und Thymeleaf in IntelliJ kann zu einer frustrierenden Erfahrung werden, wenn man bei jeder kleinen Änderung an den Templates oder statischen Ressourcen wie CSS- und JavaScript-Dateien die Anwendung neu starten muss. Dieser Prozess verlangsamt die Entwicklung erheblich. Daher habe ich mich mal nach einer Lösung für das Problem umgesehen und glücklicherweise gibt es eine Reihe von Konfigurationseinstellungen in der application.properties-Datei, die dieses Problem lösen und einen nahtlosen Live-Reload der statischen Ressourcen und Templates ermöglichen. Standardmäßig ist Spring Boot für die Produktionsumgebung optimiert. Das bedeutet, dass Thymeleaf-Templates und statische Ressourcen aus Effizienzgründen zwischengespeichert werden. Während dies in der Produktion die Performance verbessert, führt es in der Entwicklung dazu, dass Änderungen an den Dateien nicht sofort…
Kommentare sind geschlossenTODO für Tag 26 Umgang mit unbalancierten Klassen (class_weight) In scikit-learn wird der Parameter class_weight in vielen Klassifikationsalgorithmen (wie z.B. LogisticRegression, SVC, DecisionTreeClassifier, RandomForestClassifier) verwendet, um mit unbalancierten Klassen umzugehen. Die Grundidee ist, den Loss beim Training des Modells für die unterrepräsentierte(n) Klasse(n) höher zu gewichten. Wenn z.B. eine Klasse deutlich mehr Instanzen hat als andere (z.B. 90% Klasse A, 10% Klasse B), neigen viele Algorithmen dazu, die Mehrheitsklasse übermäßig gut zu lernen und die Minderheitsklasse zu ignorieren. Das liegt daran, dass der Standard-Loss-Funktion jeder Fehler gleich viel „kostet“. Ein Modell, das einfach immer die Mehrheitsklasse vorhersagt, hätte bereits eine hohe Accuracy, aber eine schlechte Leistung für die Minderheitsklasse. Um dem Problem zu begegnen, gibt es den Parameter class_weight. Er…
Kommentare sind geschlossen