
To-Do für heute
- scikit-learn installieren und Installation testen
- Überblick über die Struktur der Bibliothek gewinnen
- Beispiel-Datensatz laden und Daten inspizieren
Was ist scikit-learn?
- scikit-learn ist eine freie Python-Bibliothek für maschinelles Lernen.
- Sie bietet einfach zu benutzende Tools für Klassifikation, Regression, Clustering, Dimensionalitätsreduktion und viele weitere ML-Aufgaben.
- scikit-learn ist auf Numpy und SciPy aufgebaut und deshalb sehr effizient.
- Ideal für Einsteiger und Fortgeschrittene dank klarer API.
Voraussetzungen
- Python (idealerweise Version 3.7+)
- pip (Python Paketmanager)
Installation
pip install scikit-learn
# Optional
pip install jupyterlabJupyterLab
JupyterLab vereinfacht die Arbeit mit scikit-learn, weil es eine interaktive Umgebung bietet, in der man Code, Visualisierungen und Dokumentation nahtlos kombinieren kann. Man kann Datensätze schrittweise untersuchen, Modelle direkt trainieren und evaluieren, und die Ergebnisse sofort visualisieren – alles in einer übersichtlichen Oberfläche.
JupyterLab starten
jupyter labNache dem Start wird JupyterLab im Broser geöffnet.

Alternativ kann man auch mit PyCharm oder einem anderen Editor arbeiten, aber ich bevorzuge Jupyter-Lab wegen dem Komfort.
Installation überprüfen
Zum überprüfen der Installation kann man ein neues Jupyter-Notebook öffnen und folgenden Python Code ausführen.
import sklearn
print(sklearn.__version__)
Wie man sieht habe ich die Version 1.7.dev0 installiert.
Die wichtigsten scikit-learn Module
scikit-learn bietet viele Module, hier eine Auswahl der wichtigsten.
| Modul | Funktion | Link |
|---|---|---|
datasets | Eingebaute Beispiel-Datensätze (z.B. Iris, Digits) | https://scikit-learn.org/stable/api/sklearn.datasets.html |
model_selection | Datenaufteilung, Cross-Validation, Hyperparameter tuning | https://scikit-learn.org/stable/api/sklearn.preprocessing.html |
preprocessing | Datenvorverarbeitung: Skalierung, Encoding, Imputation | https://scikit-learn.org/stable/api/sklearn.preprocessing.html |
linear_model | Lineare Modelle: Regression, Klassifikation | https://scikit-learn.org/stable/api/sklearn.linear_model.html |
tree | Entscheidungsbäume | https://scikit-learn.org/stable/api/sklearn.tree.html |
ensemble | Ensemble-Verfahren: Random Forest, Gradient Boosting | https://scikit-learn.org/stable/api/sklearn.ensemble.html |
svm | Support Vector Machines | https://scikit-learn.org/stable/api/sklearn.svm.html |
metrics | Bewertungsmethoden (Accuracy, Precision, Recall, usw.) | https://scikit-learn.org/stable/api/sklearn.metrics.html |
Beispiel: Iris-Datensatz laden und anschauen
Der Iris-Datensatz ist ein klassischer Datensatz in der Statistik und im Maschine Learning. Er enthält 150 Messungen von Iris-Blumen, jeweils mit vier Merkmalen: Kelchblattlänge, Kelchblattbreite, Kronblattlänge und Kronblattbreite. Ziel ist es, die jeweilige Art der Blume vorherzusagen – Iris setosa, Iris versicolor oder Iris virginica. Der Datensatz ist ideal für erste Klassifikationsmodelle, da er klein, gut strukturiert und leicht verständlich ist.
https://www.kaggle.com/datasets/uciml/iris
from sklearn import datasets
iris = datasets.load_iris()
print(iris.DESCR) # Beschreibung des Datensatzes
print("Feature-Namen:", iris.feature_names)
print("Zielnamen:", iris.target_names)
print("Feature-Daten:\n", iris.data[:5]) # die ersten 5 Zeilen der Features
print("Zielwerte:\n", iris.target[:5]) # die zugehörigen Labels
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. dropdown:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
Feature-Namen: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Zielnamen: ['setosa' 'versicolor' 'virginica']
Feature-Daten:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
Zielwerte:
[0 0 0 0 0]
Ein Bild aus dem Iris Datensatz anzeigen
Ein paar zusätzliche Python Bibliotheken installieren. Dazu im Jupyter-Lab folgenden Code ausführen. Die Zeile sorgt dafür, dass man im Notebook mit Daten arbeiten und sie anschaulich visualisieren kann – ein typischer erster Schritt in einem Data-Science-Notebook.
Wenn die Pakete schon installiert sind, wird einfach nichts oder nur eine kurze Meldung ausgegeben. Wenn die Installation durchgeführt wird, lädt pip sie aus dem Internet herunter und installiert sie in deiner aktuellen Umgebung.
!pip install pandas seaborn matplotlibDer folgende Python Code zeigt die Informationen des Iris Datensatzes an.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import datasets
# Iris-Datensatz laden
iris = datasets.load_iris()
# In ein DataFrame umwandeln
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df['target_name'] = df['target'].apply(lambda i: iris.target_names[i])
# Pairplot erzeugen
sns.pairplot(df, hue='target_name', diag_kind='hist')
plt.suptitle("Streudiagramm-Matrix des Iris-Datensatzes", y=1.02)
plt.show()Damit wird folgendes Bild erzeigt.
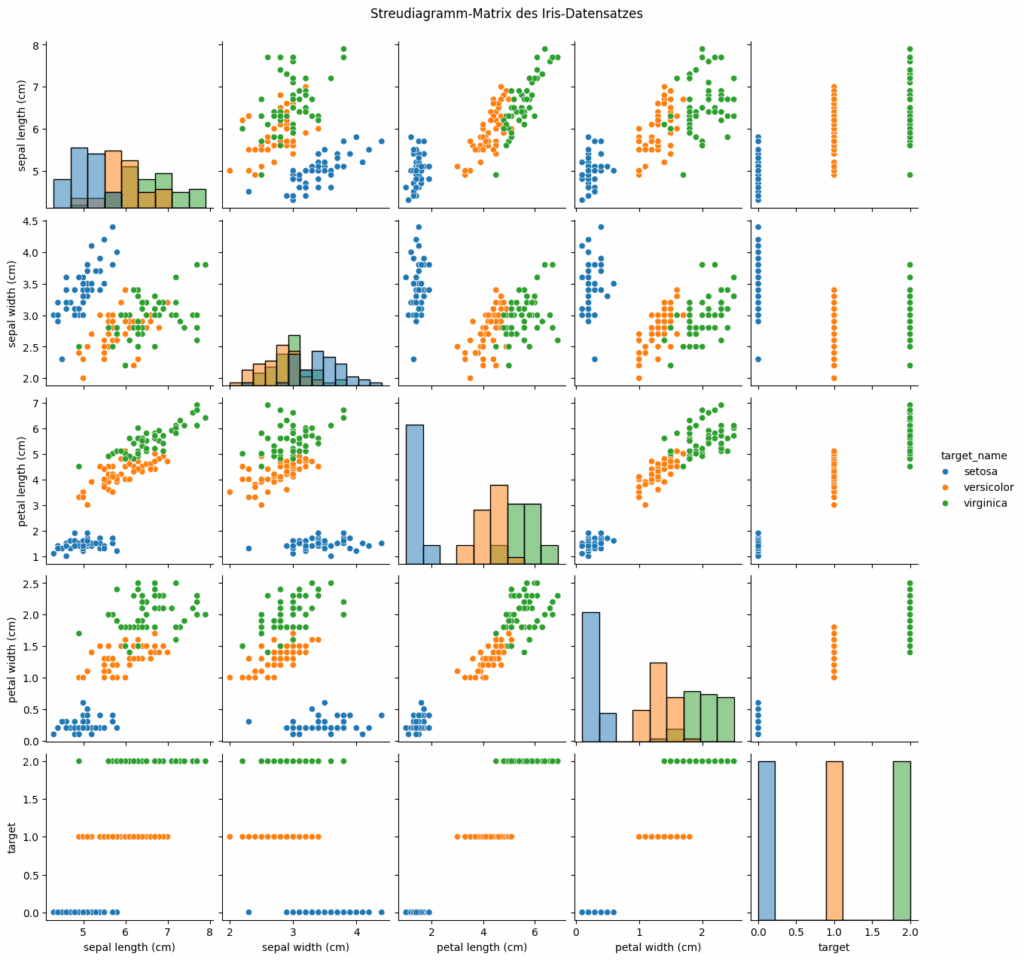
Das Bild zeigt eine Streudiagramm-Matrix des Iris-Datensatzes, erzeugt mit Seaborn.
Hier ist, was dargestellt wird:
Achsen und Merkmale
Jede Zeile und Spalte stellt eines der vier Merkmale dar:
sepal length (cm) = Kelchblattlänge
sepal width (cm) = Kelchblattbreite
petal length (cm) = Kronblattlänge
petal width (cm) = Kronblattbreite
Die letzte Zeile/Spalte „target“ zeigt die Zielklasse (Blumenart).
Diagramme in den Zellen
Die Diagonale enthält Histogramme zur Verteilung der einzelnen Merkmale.
Die anderen Zellen zeigen Scatterplots zwischen je zwei Merkmalen.
Jeder Punkt steht für eine einzelne Blume im Datensatz.
Farbkodierung nach Klasse
Blau: Iris setosa
Orange: Iris versicolor
Grün: Iris virginica
Erkenntnis
Setosa ist klar von den anderen beiden trennbar.
Versicolor und Virginica überlappen sich teilweise, aber zeigen Unterschiede z. B. bei „petal length“ und „petal width“.
Das Diagramm ist ein Klassiker zur Datenexploration, um zu verstehen, wie gut sich die Klassen visuell trennen lassen und welche Merkmale dafür am aussagekräftigsten sind.
