
TODO für Tag 25
- Stratifikation bei Klassifikationsproblemen anwenden
Stratifikation bei Klassifikationsproblemen anwenden
Stratified K-Fold Cross-Validation ist eine Variante der K-Fold Cross-Validation, die besonders nützlich ist, wenn man mit imbalancierten Datensätzen in Klassifikationsproblemen arbeiten. Ziel ist es, eine robustere Schätzung der Leistungsfähigkeit eines Modells auf unbekannten Daten zu erhalten und Overfitting zu vermeiden.
Standard K-Fold teilt den Datensatz in K gleiche Teile (Folds). Mit den Daten wird das Modell dann K-mal trainiert. Jedes Mal wird ein anderer Fold als Testset verwendet und die restlichen K-1 Folds als Trainingsset. Die Genauigkeit der K Durchläufe werden dann gemittelt. Standard K-Fold hat aber ein Problem mit imbalancierten Daten. Das ist der Fall, wenn die verschiedenen Klassen nicht annähernd gleich häufig vorkommen (z.B. 90% Klasse A, 10% Klasse B).
Bei einer zufälligen Aufteilung durch Standard K-Fold kann es passieren, dass manche Folds (insbesondere die Test-Folds) sehr wenige oder sogar gar keine Instanzen der Minderheitsklasse(n) enthalten. Dies führt zu irreführenden oder instabilen Leistungsschätzungen. Das Modell könnte auf einem Fold gut abschneiden, weil zufällig keine schwierigen Minderheitsfälle im Testset waren, oder schlecht, weil es im Trainingsset zu wenige Beispiele der Minderheitsklasse zum Lernen gab.
Die Lösung für dieses Problem ist Stratified (geschichtet) K-Fold. Anstatt die Daten zufällig aufzuteilen, stellt Stratified K-Fold sicher, dass jede der K Teile annähernd den gleichen Prozentsatz an Stichproben jeder Zielklasse enthält, wie er im Gesamtdatensatz vorhanden ist. Wenn ein Datensatz also 70% Klasse A und 30% Klasse B enthält, wird Stratified K-Fold versuchen, jeden Fold so zu erstellen, dass er ebenfalls ungefähr 70% Klasse A und 30% Klasse B enthält. Dies führt zu zuverlässigeren und realistischeren Leistungsschätzungen, da jede Iteration der Kreuzvalidierung sowohl im Trainings- als auch im Testset eine repräsentative Verteilung der Klassen hat. Das Modell wird gezwungen, auch von den Minderheitsklassen zu lernen und auf ihnen zu testen.
StratifiedKFold ist eine gute Wahl, um verschiedene Machine-Learning-Modelle miteinander zu vergleichen, insbesondere wenn die Daten unausgewogen wind (was z.B. bei Spam-Nachrichten oft der Fall ist – mehr „ham“ als „spam“).
Folgendes Beispiel nutzt Stratified KFold um verschiedene Klassifikatoren auf dem „SMS Spam Collection“ Datensatz anzuwenden und zu vergleichen. Ich habe das Beispiel gewählt, da der SMS Spam Collection Datensatz sehr unausgewogen ist. Er enthält etwa 87% Ham und 13% Spam. Den verwendeten Datensatz kann man vom UCI Machine Learning Repository herunterladen, entpacken und die entpackte Datei unter dem Namen ‚SMSSpamCollection‘ speichern.
import pandas as pd
import numpy as np
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import make_scorer, f1_score, roc_auc_score, accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns # Für ansprechendere Plots (optional, aber empfohlen)
# Daten laden und vorbereiten
df = pd.read_csv('SMSSpamCollection', sep='\t', header=None, names=['label', 'message'])
df['label_num'] = df['label'].map({'spam': 1, 'ham': 0})
X = df['message']
y = df['label_num']
print(f"Verteilung der Klassen:\n{y.value_counts(normalize=True)}\n")
# Modelle und Pipeline definieren
classifiers = {
"Logistic Regression": LogisticRegression(solver='liblinear', random_state=42, class_weight='balanced'),
"Multinomial NB": MultinomialNB(), # Kürzerer Name für Plots
"SVM (Linear)": SVC(kernel='linear', probability=True, random_state=42, class_weight='balanced'),
"Random Forest": RandomForestClassifier(random_state=42, class_weight='balanced')
}
# Stratified K-Fold Cross-Validation einrichten
N_SPLITS = 5
skf = StratifiedKFold(n_splits=N_SPLITS, shuffle=True, random_state=42)
# Modelle evaluieren und vergleichen
# Verwendet ein Dictionary, um die rohen Cross-Validation-Scores für jede Metrik zu speichern
# Nützlich, wenn man z.B. Boxplots der Fold-Scores erstellen möchte
raw_results_per_metric = {
'accuracy': {},
'roc_auc': {},
'f1_spam': {}
}
# Dictionary für die mittleren Scores, das wir auch für die Tabelle verwenden
mean_results = {}
scoring_definitions = {
'accuracy': ('accuracy', 'Accuracy'),
'roc_auc': ('roc_auc', 'ROC AUC Score'),
'f1_spam': (make_scorer(f1_score, pos_label=1, zero_division=0), 'F1-Score (Spam)') # zero_division für den Fall, dass keine pos_label Instanzen in einem Fold sind
}
print(f"Vergleiche {len(classifiers)} Modelle mit {N_SPLITS}-Fold Stratified Cross-Validation:\n")
for model_name, classifier in classifiers.items():
pipeline = Pipeline([
('tfidf', TfidfVectorizer(stop_words='english', max_features=5000)),
('clf', classifier)
])
print(f"Evaluiere Modell: {model_name}...")
current_model_mean_scores = {}
for metric_key, (scorer_func_or_str, metric_display_name) in scoring_definitions.items():
try:
cv_scores = cross_val_score(pipeline, X, y, cv=skf, scoring=scorer_func_or_str, n_jobs=-1)
raw_results_per_metric[metric_key][model_name] = cv_scores # Speichere alle Fold-Scores
current_model_mean_scores[metric_key] = cv_scores.mean()
print(f" {metric_display_name}: {cv_scores.mean():.4f} (+/- {cv_scores.std() * 2:.4f})")
except Exception as e:
print(f" Konnte {metric_display_name} für {model_name} nicht berechnen: {e}")
raw_results_per_metric[metric_key][model_name] = np.array([np.nan] * N_SPLITS)
current_model_mean_scores[metric_key] = np.nan
mean_results[model_name] = current_model_mean_scores
print("-" * 30)
# Ergebnisse zusammenfassen in DataFrame
results_df = pd.DataFrame(mean_results).T # Transponieren für Modelle als Zeilen
print("\n--- Zusammenfassung der durchschnittlichen Metriken ---")
print(results_df.sort_values(by='f1_spam', ascending=False))
# Ergebnisse visualisieren mit Matplotlib/Seaborn
sns.set_style("whitegrid") # Setzt einen schönen Stil für die Plots
metrics_to_plot = {
'accuracy': 'Accuracy Score',
'roc_auc': 'ROC AUC Score',
'f1_spam': 'F1-Score (Spam Detection)'
}
# Erstellt für jede Metrik ein eigenes Balkendiagramm
for metric_key, plot_title in metrics_to_plot.items():
# Sortiere die Modelle nach der aktuellen Metrik für eine bessere Visualisierung
# (optional, macht den Plot aber oft übersichtlicher)
sorted_models = results_df[metric_key].sort_values(ascending=False)
plt.figure(figsize=(10, 7)) # Etwas größer für bessere Lesbarkeit
bars = plt.bar(sorted_models.index, sorted_models.values, color=sns.color_palette("viridis", len(sorted_models)))
plt.title(f'Modellvergleich: {plot_title}', fontsize=16)
plt.xlabel('Modell', fontsize=14)
plt.ylabel(plot_title, fontsize=14)
plt.xticks(rotation=45, ha="right", fontsize=12) # Dreht die X-Achsen-Beschriftungen
plt.yticks(fontsize=12)
plt.ylim(bottom=max(0, sorted_models.min() * 0.95), top=min(1.0, sorted_models.max() * 1.05)) # Dynamische Y-Achsen-Grenzen, aber nicht unter 0 oder über 1
# Füge die Werte über den Balken hinzu
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2.0, yval + 0.005, f'{yval:.4f}', ha='center', va='bottom', fontsize=10)
plt.tight_layout() # Passt Plot-Parameter für eine saubere Darstellung an
plt.show()
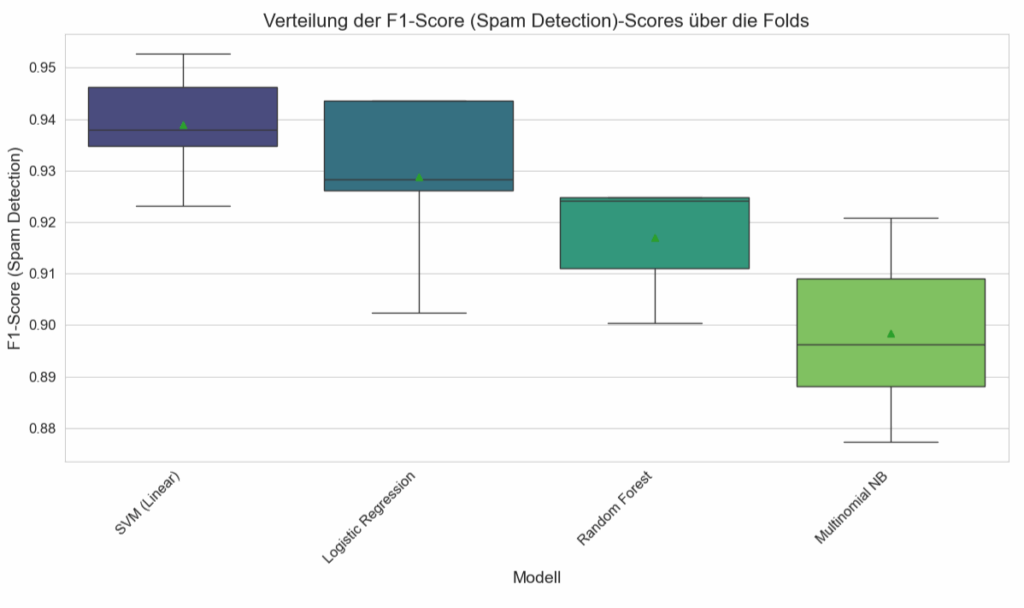
# Optional: Boxplot der Fold-Scores für eine spezifische Metrik (z.B. F1-Score)
# Dies gibt einen besseren Eindruck von der Varianz der Leistung über die Folds.
metric_for_boxplot = 'f1_spam'
metric_display_name_boxplot = metrics_to_plot[metric_for_boxplot]
# Erstelle Daten für Boxplot: DataFrame mit Modellen als Spalten und Fold-Scores als Zeilen
boxplot_data_list = []
model_order_for_boxplot = results_df.sort_values(by=metric_for_boxplot, ascending=False).index # Behalte die Reihenfolge vom Balkendiagramm
for model_name in model_order_for_boxplot:
boxplot_data_list.append(raw_results_per_metric[metric_for_boxplot][model_name])
plt.figure(figsize=(12, 7))
sns.boxplot(data=boxplot_data_list, palette="viridis", showmeans=True) # showmeans zeigt den Mittelwert als Dreieck
plt.xticks(ticks=range(len(model_order_for_boxplot)), labels=model_order_for_boxplot, rotation=45, ha="right", fontsize=12)
plt.title(f'Verteilung der {metric_display_name_boxplot}-Scores über die Folds', fontsize=16)
plt.ylabel(metric_display_name_boxplot, fontsize=14)
plt.xlabel('Modell', fontsize=14)
plt.yticks(fontsize=12)
plt.tight_layout()
plt.show()Jedes Modell wird 5-mal trainiert und getestet, wobei jedes Mal ein anderer, Teil der Daten als Test-Set dient. Für jedes Modell werden drei Metriken angezeigt. Accuracy, ROC AUC Score und F1-Score.
Die folgende Ausgabe fasst die Leistungswerte für jedes Modell über alle Metriken hinweg zusammen, was einen direkten Vergleich ermöglicht. Die Liste ist nach dem f1_spam-Score absteigend sortiert.
Verteilung der Klassen:
label_num
0 0.865937
1 0.134063
Name: proportion, dtype: float64
Vergleiche 4 Modelle mit 5-Fold Stratified Cross-Validation:
Evaluiere Modell: Logistic Regression...
Accuracy: 0.9810 (+/- 0.0079)
ROC AUC Score: 0.9911 (+/- 0.0095)
F1-Score (Spam): 0.9288 (+/- 0.0302)
------------------------------
Evaluiere Modell: Multinomial NB...
Accuracy: 0.9752 (+/- 0.0069)
ROC AUC Score: 0.9889 (+/- 0.0069)
F1-Score (Spam): 0.8983 (+/- 0.0307)
------------------------------
Evaluiere Modell: SVM (Linear)...
Accuracy: 0.9840 (+/- 0.0049)
ROC AUC Score: 0.9910 (+/- 0.0068)
F1-Score (Spam): 0.9389 (+/- 0.0203)
------------------------------
Evaluiere Modell: Random Forest...
Accuracy: 0.9794 (+/- 0.0045)
ROC AUC Score: 0.9897 (+/- 0.0083)
F1-Score (Spam): 0.9170 (+/- 0.0197)
------------------------------
--- Zusammenfassung der durchschnittlichen Metriken ---
accuracy roc_auc f1_spam
SVM (Linear) 0.984027 0.991024 0.938945
Logistic Regression 0.980976 0.991101 0.928780
Random Forest 0.979361 0.989728 0.917010
Multinomial NB 0.975233 0.988873 0.898327
Hier noch mal die Ergebnisse als Balkendiagramm.
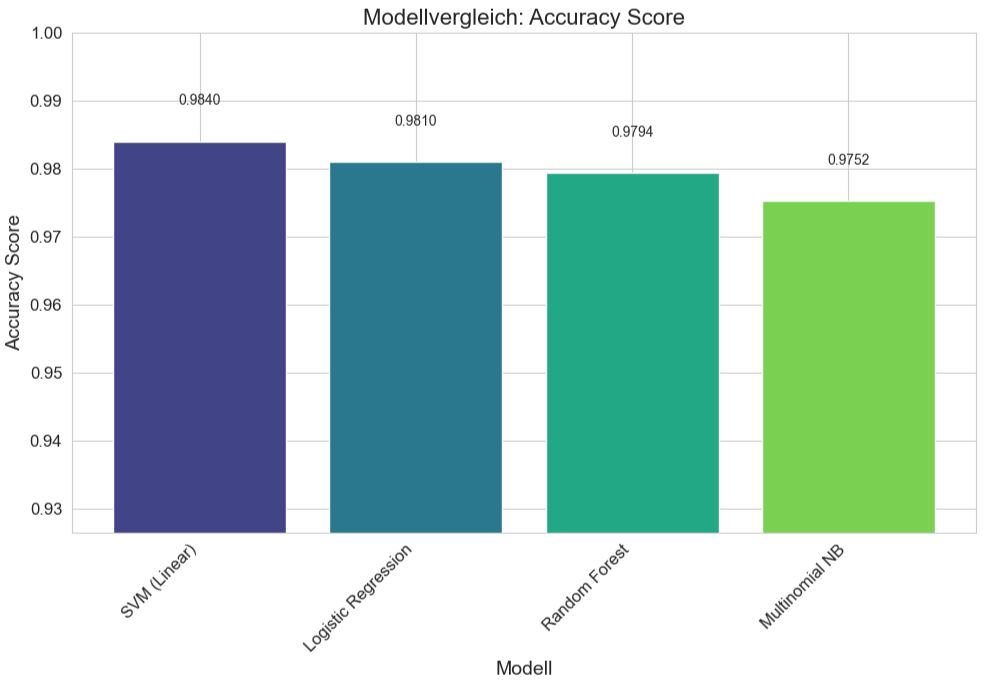
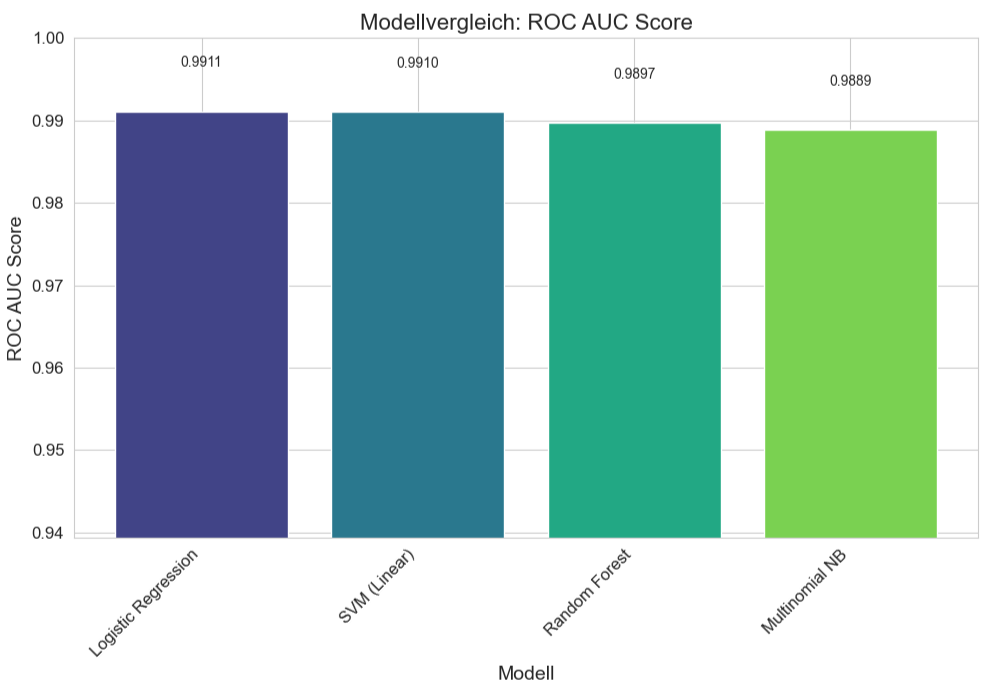
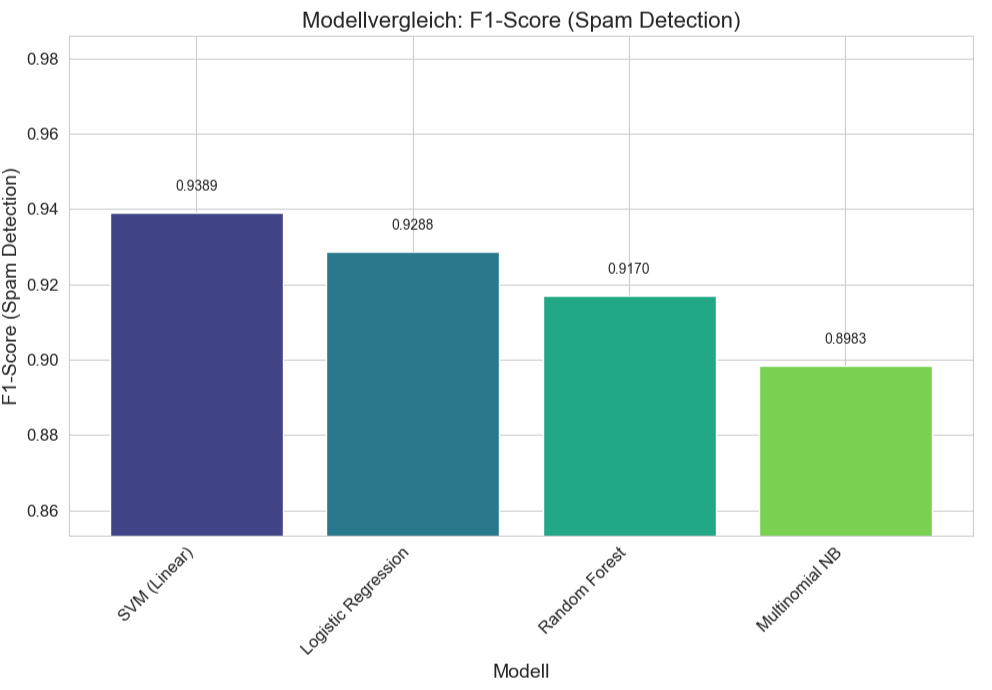
SVM (Linear) liefert den höchsten F1-Score für Spam (0.9390) und die höchste Accuracy (0.9840). Der ROC AUC ist ebenfalls exzellent (0.9910). Die (+/-)-Werte für SVM waren auch die niedrigsten für F1 und Accuracy, was auf die höchste Konsistenz hindeutet. Die Logistic Regression ist sehr nah an SVM, mit einem minimal höheren ROC AUC Score (0.9911 vs. 0.9910, praktisch identisch), aber einem etwas niedrigeren F1-Score für Spam (0.9288). Der Random Forest liefert immer noch sehr gute Ergebnisse, liegt aber bei allen drei Metriken leicht hinter SVM und Logistic Regression. Multinomial NB ist das Modell mit der niedrigsten Leistung in diesem Vergleich, aber immer noch mit sehr respektablen Scores (z.B. F1-Spam von fast 0.90). Zusammenfassend kann man festhalten, dass alle vier getesteten Modelle zeigen eine hohe Leistungsfähigkeit bei der Spam-Erkennung auf diesem Datensatz.
Die (+/-) Werte (Standardabweichungen/Konfidenzintervalle) sind für alle Modelle und Metriken relativ klein. Das deutet darauf hin, dass die Leistung der Modelle nicht stark von der spezifischen Aufteilung der Daten in Trainings- und Test-Sets innerhalb der Kreuzvalidierung abhängt, ein gutes Zeichen für die Generalisierungsfähigkeit.
