Ein neues spannendes Modell für den Bereich der Softwareentwicklung ist Kwaipilot/KAT-Dev-72B-Exp. Mit einem SWE-Bench Verified von 74.6% ist es ein vermutlich das beste Open Source Modell für alles, was mit Code zu tun hat. Das Modell benötigt in seiner ursprünglichen Form erhebliche Rechenressourcen. Um es zugänglicher und auf lokaler Hardware lauffähig zu machen, habe ich es in das GGUF-Format konvertiert, quantisiert und anschließend sowohl auf Hugging Face als auch auf Ollama.com veröffentlicht.
Schritt 1: Die Vorbereitung und Konvertierung nach GGUF
Das GGUF-Format, entwickelt vom Team hinter llama.cpp, ist der Schlüssel, um große Modelle effizient auf Consumer-Hardware (sogar nur mit CPU) auszuführen. Der erste Schritt war also, das ursprüngliche Modell in dieses Format zu überführen.
1.1. llama.cpp einrichten
Das Herzstück der Konvertierung ist das llama.cpp-Repository. Zuerst habe ich das Repository geklont und die notwendigen Python-Abhängigkeiten installiert.
# Repository klonen
git clone https://github.com/ggerganov/llama.cpp.git
# Abhängigkeiten installieren
pip install -r llama.cpp/requirements.txt
1.2. Konvertierung zu GGUF (F16)
Mit den vorbereiteten Skripten konnte ich nun das Hugging Face Modell in ein 16-Bit-Floating-Point (F16) GGUF-Modell umwandeln. Dies ist die unquantisierte Basisversion.
# Download
hf download Kwaipilot/KAT-Dev-72B-Exp --cache-dir Kwaipilot_KAT-Dev-72B-Exp
# Convertpython3 llama.cpp/convert_hf_to_gguf.py Kwaipilot_KAT-Dev-72B-Exp/models--Kwaipilot--KAT-Dev-72B-Exp/snapshots/fa664c94f06af1304986f3e9c06dd75e5fe19830
Das Ergebnis war eine Datei namens Kwaipilot_KAT-Dev-72B-Exp-F16.gguf. Diese ist zwar schon im richtigen Format, aber mit über 130 GB immer noch riesig.
1.3. Quantisierung auf Q4_K_M
Jetzt kommt die Magie der Quantisierung ins Spiel. Dabei wird die Präzision der Modellgewichte reduziert, was die Dateigröße und den Speicherbedarf drastisch senkt. Ich habe mich für die Q4_K_M-Variante entschieden, da sie einen exzellenten Kompromiss zwischen Leistung und Größe bietet. dazu habe ich noch mal das llama.cpp Release https://github.com/ggml-org/llama.cpp/releases/download/b6732/llama-b6732-bin-ubuntu-x64.zip heruntergeladen um llama-quantize nicht selbst kompilieren zu müssen.
./llama-quantize Kwaipilot_KAT-Dev-72B-Exp-F16.gguf Kwaipilot_KAT-Dev-72B-Exp-Q4_K_M.gguf Q4_K_MDieser Befehl nahm die große F16-Datei als Input und erzeugte eine deutlich kleinere, quantisierte Q4_K_M-Version.
Schritt 2: Veröffentlichung auf Hugging Face
Um das Modell Community zu teilen, habe ich beide GGUF-Dateien auf Hugging Face hochgeladen. Dadurch können andere das Modell leicht finden und für ihre eigenen Zwecke nutzen.
Ich habe ein neues Repository namens Michael22/Kwaipilot_KAT-Dev-72B-Exp-GGUF angelegt und die Dateien hochgeladen:
# Upload der unquantisierten F16-Version
hf upload Michael22/Kwaipilot_KAT-Dev-72B-Exp-GGUF Kwaipilot_KAT-Dev-72B-Exp-F16.gguf
# Upload der quantisierten Q4_K_M-Version
hf upload Michael22/Kwaipilot_KAT-Dev-72B-Exp-GGUF Kwaipilot_KAT-Dev-72B-Exp-Q4_K_M.gguf
Ihr findet das fertige Repository hier: https://huggingface.co/Michael22/Kwaipilot_KAT-Dev-72B-Exp-GGUF
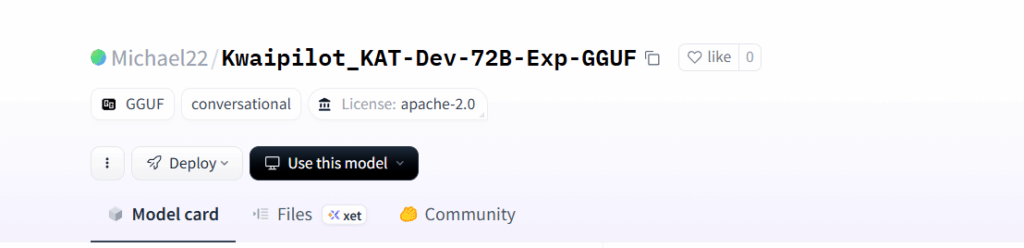
Schritt 3: Veröffentlichung auf Ollama.com
Ollama ist eine fantastische Plattform, die es unglaublich einfach macht, LLMs lokal auszuführen und zu verwalten. Ein ollama run …-Befehl genügt, und schon kann man loslegen. Mein Ziel war es, das Kwaipilot-Modell genauso einfach zugänglich zu machen.
3.1. Das Modelfile erstellen
Ollama verwendet eine Konfigurationsdatei namens Modelfile, um zu definieren, wie ein Modell aufgebaut ist und wie es sich verhalten soll. Ich habe ein Modelfile mit folgendem Inhalt erstellt: code Modelfiledownloadcontent_copyexpand_less
# Definiert die GGUF-Datei als Basis
FROM ./Kwaipilot_KAT-Dev-72B-Exp-Q4_K_M.gguf
# Setzt Standardparameter für Kreativität und Kontextlänge
PARAMETER temperature 0.6
PARAMETER num_ctx 65536
# Definiert die Chat-Vorlage
TEMPLATE """
{{- if .System }}
{{ .System }}
{{- end }}
USER: {{ .Prompt }}
ASSISTANT:
"""
# Definiert den System-Prompt, um das Modell auf seine Rolle vorzubereiten
SYSTEM """
You are an expert AI programmer and software engineer. You are a large language model created by Kwaipilot. Your purpose is to assist users with all their software engineering needs. This includes:
* **Writing high-quality, clean, and efficient code.**
* **Debugging and fixing errors in existing code.**
* **Refactoring and improving code quality.**
* **Optimizing code for performance.**
* **Generating test cases.**
* **Explaining complex code and providing documentation.**
* **Assisting with architectural and design decisions.**
When responding to a request, provide a complete and well-thought-out solution. Explain your reasoning and the trade-offs of your approach. When you provide code, include explanations of how it works.
"""
Dieser System-Prompt ist entscheidend, denn er weist das Modell an, als Experte für Softwareentwicklung zu agieren und stets qualitativ hochwertige, gut erklärte Antworten zu liefern.
3.2. Lokales Ollama-Modell erstellen und veröffentlichen
Mit dem Modelfile konnte ich nun das lokale Ollama-Modell erstellen und es direkt im Anschluss in den öffentlichen Hub von Ollama hochladen. code Bashdownloadcontent_copyexpand_less
# Erstellt das lokale Modell aus dem Modelfile
ollama create jentschmichael/Kwaipilot_KAT-Dev-72B-Exp-GGUF -f Modelfile
# Lädt das Modell in den öffentlichen Ollama-Hub hoch
ollama push jentschmichael/Kwaipilot_KAT-Dev-72B-Exp-GGUF
Und das war’s schon! Das Modell ist jetzt auf Ollama.com unter https://ollama.com/jentschmichael/Kwaipilot_KAT-Dev-72B-Exp-GGUF verfügbar.
Fazit
Der Prozess, ein spezialisiertes Modell wie Kwaipilot/KAT-Dev-72B-Exp zu nehmen und es für eine breitere Community zugänglich zu machen, ist recht einfach und benötigt keine GPU. Durch die Konvertierung in GGUF und die Veröffentlichung auf Plattformen wie Hugging Face und Ollama kann nun jeder von der Leistungsfähigkeit dieses Modells auf seiner lokalen Maschine profitieren.
Ich hoffe, diese Anleitung war hilfreich für euch. Probiert das Modell gerne selbst aus und lasst mich wissen, was ihr damit entwickelt!
