
Nach einer kleinen Weihnachtspause geht es nun endlich weiter mit der 30 Tage DSPy-Challenge.
Sprachmodelle (LLMs) besitzen ein breites Allgemeinwissen, das jedoch auf den Daten basiert, mit denen sie trainiert wurden. Dieses Wissen ist statisch und kann veralten oder für spezifische, private Domänen unvollständig sein. Retrieval Augmented Generation (RAG) ist eine Architektur, die dieses Problem löst, indem sie LLMs zur Laufzeit Zugriff auf externe Wissensquellen gewährt. Anstatt eine Frage direkt an das LLM zu senden, wird die Anfrage zunächst genutzt, um relevante Informationen aus einer Wissensdatenbank zu finden. Diese Informationen werden dem LLM dann als zusätzlicher Kontext für die Beantwortung der ursprünglichen Frage bereitgestellt.
Die Architektur besteht aus zwei Kernkomponenten:
Embedding
Die Aufgabe des Retrievers ist es, aus einem großen Korpus von Dokumenten (einer Wissensdatenbank) eine kleine Menge an Textpassagen zu identifizieren, die für die Beantwortung einer gegebenen Anfrage am relevantesten sind. In der Regel werden die Dokumente des Korpus in kleinere Abschnitte (Chunks) zerlegt und mittels eines Embedding-Modells in numerische Vektoren umgewandelt. Diese Vektoren werden in einer Vektordatenbank gespeichert. Bei einer Anfrage wird diese ebenfalls in einen Vektor umgewandelt, und der Retriever sucht mittels einer Ähnlichkeitssuche (z. B. Kosinus-Ähnlichkeit) die Vektoren – und damit die Textpassagen – die der Anfrage am nächsten kommen.
Generator
Der Generator, typischerweise ein LLM, erhält die ursprüngliche Anfrage sowie den vom Retriever bereitgestellten Kontext. Seine Aufgabe ist es, eine kohärente, präzise und auf dem Kontext basierende Antwort zu formulieren. Der abgerufene Kontext wird in den Prompt des LLMs eingefügt. Das Modell wird angewiesen, seine Antwort ausschließlich oder primär auf diesen Informationen zu basieren. Um den wird es aber erst morgen wieder gehen.
Vorteile von RAG-Systemen
RAG-Systeme können auf aktuelle oder domänenspezifische Informationen zugreifen, die nicht im ursprünglichen Trainingsdatensatz des LLMs enthalten waren. Da die Antworten des LLMs auf externen, überprüfbaren Fakten basieren („Grounding“), wird die Tendenz des Modells, sachlich falsche Informationen zu erfinden, deutlich verringert. Die Quellen, auf denen eine Antwort basiert, können zitiert werden. Dies ermöglicht es dem Benutzer, die Fakten zu überprüfen und schafft Vertrauen in das System.
Exkurs Embeddings
Embeddings sind eine Art digitale „Fingerabdrücke“ für Daten wie Wörter, Sätze, Texte oder Bilder. Sie wandeln diese Inhalte in Vektoren, also Listen von Zahlen, um. Der Clou dabei ist, dass ähnliche Inhalte ähnliche Zahlenrepräsentationen erhalten und dadurch im mehrdimensionalen Raum nahe beieinander liegen. Das erlaubt Computern, Bedeutungen zu vergleichen, Zusammenhänge zu erkennen oder passende Inhalte zu suchen, ohne den ursprünglichen Text oder das Bild direkt verstehen zu müssen. Embeddings sind damit die Grundlage vieler moderner KI-Anwendungen, etwa für semantische Suche, Empfehlungssysteme oder Textanalyse.
Ich verwende heute das Modell unsloth/embeddinggemma-300m von Google mit 300 Millionen Parametern. Es basiert technisch auf der Gemma‑3-Architektur und erzeugt Vektor-Repräsentationen von Text, die sich sehr gut für semantische Aufgaben eignen – etwa Suche, Klassifikation, Clustering oder Ähnlichkeitsmessung. Trotz relativ kleiner Parameterzahl liefert es gute Embeddings und ist mit gerade mal 300.000.000 Parametern sehr ressourcenschonend einsetzbar.
Die maximale Eingabelänge beträgt 2048 Token, und das Modell liefert Embeddings mit einer Standarddimension von 768. Zusätzlich unterstützt es über eine Technik namens Matryoshka Representation Learning (MRL) auch kleinere Embedding-Größen (512, 256, 128), indem es die 768-Dimensionen effektiv „trunkiert“ und neu normalisiert.
Vorbereitung
Damit RAG funktioniert benötigt man ein weiteres Modell, dass die Embedding erstellt. Ich verwende hier das embeddinggemma-300m Modell. Es ist klein, schnell, ich habe es schon in anderen Projekten verwendet und gute Erfahrungen damit gemacht. Nach dem Download muss man einen weiteren llama.cpp Server Starten, der auf Port 8081 horcht.
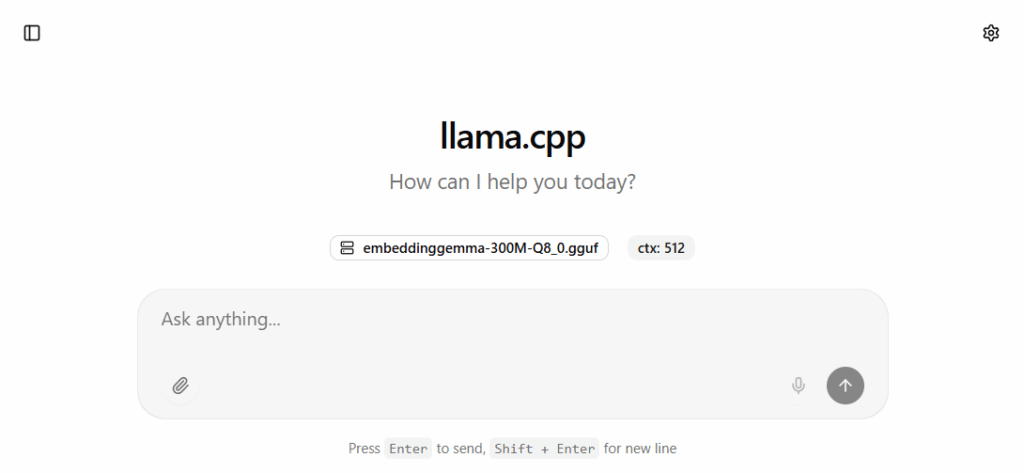
llama-server -m embeddinggemma-300M-Q8_0.gguf --embeddings -c 512 -ngl 99 --host 0.0.0.0 --port 8081Wenn der Server läuft, kann man den Browser öffnen (http://127.0.0.1:8081/) und sollte folgendes sehen.
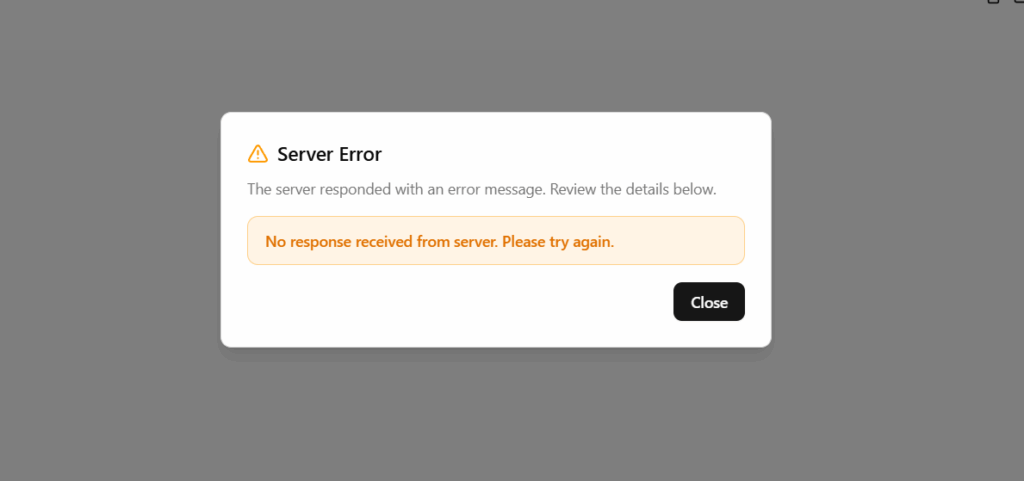
Versucht man ein Frage zu stellen, erhält man folgenden Fehler, da ein Embedding Modell nicht dazu gedacht ist, Texte zu erzeugen.
So weit so gut.
Einrichtung eines Embedding Models in DSPy
Die folgende Umsetzung zeigt, wie ein einfacher Dokumentenkorpus erstellt und ein Embedding Model in DSPy konfiguriert wird. Als Embedder wird embeddinggemma-300M verwendet, ein leistungsstarkes Modell, das eine feinere Interaktion zwischen Anfrage und Dokumenten-Embeddings ermöglicht.
import dspy
embedder = dspy.Embedder("openai/embeddinggemma-300M-Q8_0.gguf",
api_base="http://localhost:8081/v1",
api_key="no_key_needed",
batch_size=100)
local_llm = dspy.LM(
"openai/gemma-3-4b-it-Q4_K_M.gguf",
api_base="http://localhost:8080/v1",
api_key="no_key_needed",
temperature=0.1,
cache=False
)
dspy.configure(lm=local_llm)Für eine lokale Demonstration wird ein kleiner Korpus von Textdokumenten erstellt. In einem realen Szenario würde dieser Korpus in einer Vektordatenbank indexiert. Für die Demonstration wird der Korpus manuell definiert.
# Definition eines Beispiel-Korpus (für das Verständnis, wird hier nicht direkt indexiert)
document_corpus = [
"Die Photosynthese ist der Prozess, den Pflanzen nutzen, um Lichtenergie in chemische Energie umzuwandeln.",
"Der Mount Everest ist mit 8.848 Metern der höchste Berg der Erde und liegt im Himalaya-Gebirge.",
"Albert Einstein war ein theoretischer Physiker, der die Relativitätstheorie entwickelte, eine der beiden Säulen der modernen Physik.",
"Das Römische Reich war ein antikes Reich, dessen Zentrum die Stadt Rom war. Es existierte von 27 v. Chr. bis 476 n. Chr."
]Das dspy.retrievers.Embeddings-Modul ist eine Schnittstelle in DSPy, um Informationen aus dem Embedding Model abzurufen. Es nimmt eine Anfrage entgegen und gibt die k relevantesten Passagen zurück.
# Instanziierung des Retrieve-Moduls. `k=3` bedeutet, es sollen die 3 relevantesten Passagen gefunden werden.
retrieve = dspy.retrievers.Embeddings(k=3, corpus=document_corpus, embedder=embedder)
# Beispielanfrage an das Retrieval Model
query = "Was ist die Relativitätstheorie?"
retrieved_passages = retrieve(query).passages
# Ausgabe der abgerufenen Passagen
print(f"Anfrage: '{query}'\n")
for i, passage in enumerate(retrieved_passages):
print(f"--- Passage {i+1} ---\n{passage}\n")Ergebnis
Die Ausführung des dspy.retrievers.Embeddings
Anfrage: 'Was ist die Relativitätstheorie?'
--- Passage 1 ---
Albert Einstein war ein theoretischer Physiker, der die Relativitätstheorie entwickelte, eine der beiden Säulen der modernen Physik.
--- Passage 2 ---
Die Photosynthese ist der Prozess, den Pflanzen nutzen, um Lichtenergie in chemische Energie umzuwandeln.
--- Passage 3 ---
Der Mount Everest ist mit 8.848 Metern der höchste Berg der Erde und liegt im Himalaya-Gebirge.Interpretation und Zusammenfassung
Das Ergebnis zeigt, dass das dspy.retrievers.Embeddings
- Funktionsweise
Der Retriever hat die Anfrage analysiert und die Passagen aus seiner Wissensdatenbank zurückgegeben, die die Konzepte „Relativitätstheorie“, „Einstein“, „Physik“, „Raum und Zeit“ am besten abdecken. - Bedeutung für RAG
Diese abgerufenen Passagen sind der „Augmented“-Teil in RAG. Sie stellen den faktenbasierten Kontext dar, der im nächsten Schritt (Tag 16) an ein LLM übergeben wird. Anstatt auf sein internes, potenziell veraltetes Wissen zurückzugreifen, wird das LLM angewiesen, seine Antwort auf Basis dieser spezifischen, relevanten Informationen zu formulieren.
Die Einrichtung eines Retrieval Models ist somit ein wichtiger Baustein beim Bau eines RAG-Systems. Es stellt die Brücke zwischen der dynamischen Welt externer Daten und den Inferenzfähigkeiten eines Sprachmodells her und schafft die Voraussetzung für die Erzeugung von faktenbasierten, transparenten und vertrauenswürdigen Antworten.
