
Die Entwicklung von spezialisierten Large Language Models (LLMs) für die Softwareentwicklung hat in den letzten Jahren beeindruckende Fortschritte gemacht. Ein neuer Player in dem Spiel ist das Modell NousResearch/NousCoder-14B. Dieses Modell wurde gezielt für die Lösung Programmieraufgaben und die Teilnahme an Programmierwettbewerben (Olympiad Programming) optimiert. Als Open-Source-Alternative bietet es Entwicklern und Unternehmen eine leistungsstarke Basis für automatisierte Code-Generierung und algorithmische Problemlösungen.
Einführung in NousResearch/NousCoder-14B
Bei NousResearch/NousCoder-14B handelt es sich um ein spezialisiertes Sprachmodell, das auf der Architektur von Qwen2.5-Coder-14B-Instruct basiert. Das primäre Ziel der Entwicklung bestand darin, die Fähigkeiten im Bereich des logischen Schlussfolgerns und der algorithmischen Effizienz zu steigern. Während viele Modelle die Syntax von vielen Programmiersprachen beherrschen, liegt der Fokus hier auf der Bewältigung von Aufgaben, die normalerweise in Informatik-Olympiaden oder technischen Interviews vorkommen.
Die Bereitstellung als Open-Source-Modell ermöglicht eine transparente Überprüfung der Leistungsdaten sowie eine lokale Implementierung, was insbesondere für datenschutzrelevante Projekte in Deutschland von hoher Bedeutung ist.
Technische Architektur und Datengrundlage
Das Fundament für NousCoder-14B bildet die Qwen2.5-Coder-Serie, welche bereits für ihre starke Performance in Coding-Benchmarks bekannt ist. Mit 14 Milliarden Parametern findet das Modell eine Balance zwischen Recheneffizienz und hoher kognitiver Kapazität.
Die Rolle von Qwen2.5-Coder
Die Entscheidung für die Qwen2.5-Basis resultiert aus der hohen Qualität der zugrundeliegenden Trainingsdaten. Diese beinhalten eine massive Menge an sicherem, funktionalem und dokumentiertem Programmcode. Die 14B-Variante ist so dimensioniert, dass sie auf moderner Consumer-Hardware oder kleineren Enterprise-Servern betrieben werden kann, ohne die Präzision massiv gegenüber 70B-Modellen einzubüßen.
Spezifisches Fine-Tuning für Olympiad Programming
Das Team von NousResearch hat ein spezifisches Fine-Tuning durchgeführt, um die Leistung in kompetitiven Szenarien zu maximieren. Dabei wurden Datensätze verwendet, die komplexe mathematische Logik und fortgeschrittene Datenstrukturen priorisieren. Dies führt dazu, dass das Modell weniger zu repetitiven Code-Mustern neigt und stattdessen optimierte Algorithmen vorschlägt.
Leistungsanalyse und Benchmarks
Um die Effektivität von NousResearch/NousCoder-14B zu bewerten, ist ein Blick auf standardisierte Benchmarks unerlässlich. Das Modell erzielt Ergebnisse, die es in die Nähe oder sogar über das Niveau von deutlich größeren proprietären Modellen heben.
HumanEval und MBPP
In den klassischen Tests wie HumanEval und MBPP (Mostly Basic Python Problems) zeigt NousCoder-14B eine hohe Erfolgsquote bei der Generierung von funktional korrektem Code beim ersten Versuch (Pass@1).
- HumanEval: Messung der Fähigkeit, Python-Funktionen basierend auf Docstrings zu vervollständigen.
- MBPP: Fokus auf grundlegende Programmierkonzepte und Standardbibliotheken.
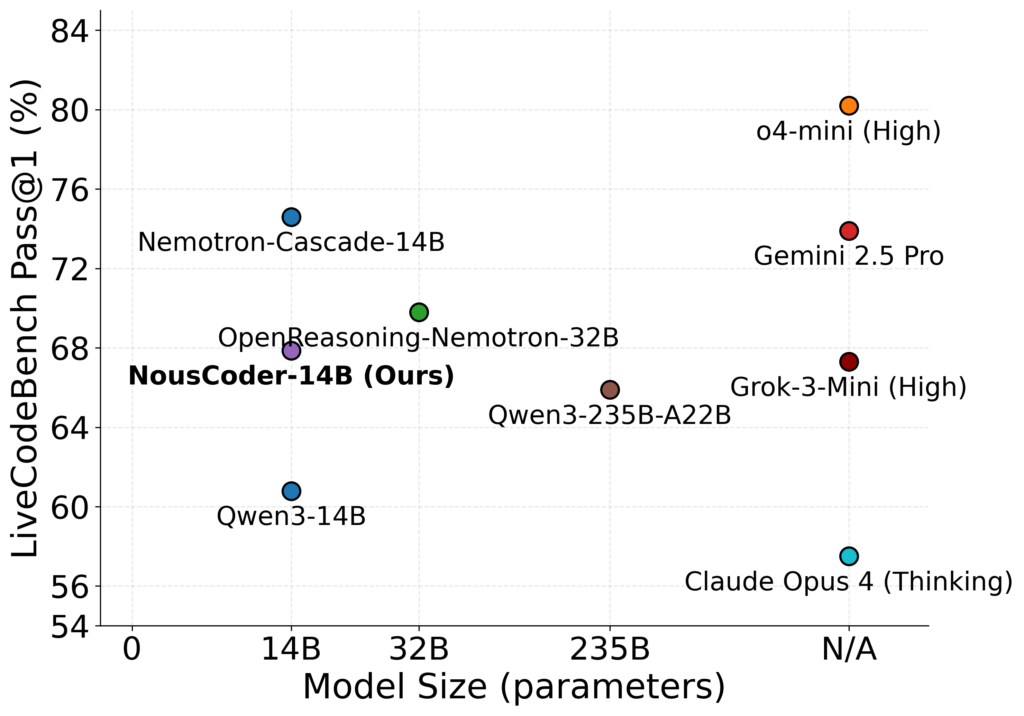
LiveCodeBench und kompetitive Metriken
Besonders hervorzuheben ist die Performance im LiveCodeBench. Dieser Benchmark nutzt Aufgaben von Plattformen wie LeetCode, AtCoder und Codeforces, die nach dem Trainingszeitraum des Modells veröffentlicht wurden. Dies verhindert den Effekt des Auswendiglernens (Data Contamination) und beweist die tatsächliche Problemlösungskompetenz von NousResearch/NousCoder-14B.
Praktische Umsetzung und Implementierung
Die Nutzung des Modells erfolgt primär über die transformers-Bibliothek von Hugging Face oder spezialisierte Inferenz-Engines wie vLLM. Um NousResearch/NousCoder-14B in einer Python-Umgebung zu verwenden, ist die Installation der entsprechenden Bibliotheken erforderlich. Dank der Nutzung der Qwen-2.5 Architektur gibt es aber auch schon GGUF Varianten, die man in llama.cpp und ollama nutzen kann. Ich verwende z.B. gerne die Quants von bartowski die in llama.cpp bei mir immer gut funktionieren.
https://huggingface.co/bartowski/NousResearch_NousCoder-14B-GGUF
Das Modell kann man in verschiedenen Größen herunterladen und in llama.cpp oder ollama verwenden.
Das folgende PowerShell-Skript konfiguriert zunächst den Fenstertitel der Konsole auf die Bezeichnung des Modells inklusive der Portnummer 6660 und des aktuellen Datums, woraufhin ein lokaler Inferenz-Server mittels llama-server gestartet wird. Hierbei lädt das Skript das Modell NousResearch/NousCoder-14B mit einer Kontextgröße von 65.536 Token und erzwingt durch die Verlagerung von 99 Layern auf die GPU sowie die Aktivierung von Flash-Attention eine hohe Rechenleistung. Der Server wird auf allen Netzwerkschnittstellen über den Port 6660 bereitgestellt, unterstützt durch vier parallele Slots die gleichzeitige Verarbeitung von Anfragen und nutzt für die Code-Generierung definierte Sampling-Parameter wie eine Temperatur von 0,6 sowie einen Top-p-Wert von 0,95 unter dem Alias NousCoder.
$Host.UI.RawUI.WindowTitle = "nouscoder-14b :6660 $(Get-Date -Format 'MM-dd')"
llama-server --flash-attn on -m NousResearch_NousCoder-14B-Q6_K_L.gguf -c 65536 -ngl 99 -np 4 --temp 0.6 --top-p 0.95 --host 0.0.0.0 --port 6660 -a NousCoder Das Skript erreicht auf einem Evo X2 ca. 17 Token pro Sekunde und auf meinem HP ZBook Ultra 14 Zoll G1a TODO
NousResearch_NousCoder-14B-Q6_K_L.gguf auf Evo X2

Mit 16,87 Token pro Sekunde liegt der Evo X2 knapp vorne.
NousResearch_NousCoder-14B-Q6_K_L.gguf auf HP ZBook Ultra 14 Zoll G1a

Mit 15,58 Token pro Sekunde liegt das Notebook von HP knapp dahinter.
NousResearch_NousCoder-14B-Q6_K_L.gguf auf Jetson Orin Developer Board
Auf meinem Jetson Orin läuft das Modul in ollama mit einem Open-WebUI Interface.
ollama run hf.co/bartowski/NousResearch_NousCoder-14B-GGUF:Q6_K_L
Nur noch 13,91 Token pro Sekunde liefert mein Jetson Orin 64GB. Allerdings läuft auf dem Jetson Orin ein ollama Server und kein llama.cpp, da ich hier sehr viele Modelle installiert habe und ollama die Modelle schnell und komfortabel wechselt. Der Vergleich ist also nicht ganz fair.
Parameter-Konfiguration
Für optimale Ergebnisse beim Coding sollte die temperature niedrig gehalten werden (z. B. zwischen 0.2 und 0.3), um deterministische Antworten zu begünstigen. Ein zu hoher Wert könnte die Kreativität steigern, führt bei Programmieraufgaben aber gelegentlich zu Syntaxfehlern. Ich starte immer gerne etwas höher und reduziere die Werte wenn ich das Modell zu viel Blödsinn ausspuckt. Ich starte im meiner Open-WebUI auch gerne eine
Interpretation der Ergebnisse
Wenn man die Ausgaben von NousResearch/NousCoder-14B analysiert, stellt man fest, dass das Modell dazu neigt, seine Antwort sehr ausführlich zu erläutern. Dies ist vermutlich ein direktes Resultat des Tunings auf Thinking.
Einsatzbereiche in der Softwareentwicklung
Das Modell eignet sich für verschiedene Szenarien innerhalb des Software-Lebenszyklus:
- Automatisierte Code-Reviews
Schwachstellen in bestehendem Code identifizieren - Pair Programming
Integration in IDEs als smarter Assistent - Algorithmendesign
- Unterstützung bei der Lösung von Problemen
- Legacy-Code-Modernisierung
Unterstützung beim Verständnis von Code
Details kann ich erst in ein paar Wochen liefern, wenn ich das Modell ausgiebig getestet habe.
Fazit
NousResearch/NousCoder-14B stellt einen Schritt in Richtung Open-Source-KI Modelle dar. Durch die Spezialisierung auf Programmierung und die Basis Qwen2.5-Architektur bietet es eine Leistungsfähigkeit, die bisher oft nur größeren Modellen vorbehalten war.
Links
https://nousresearch.com/nouscoder-14b-a-competitive-olympiad-programming-model
