
Unter https://www.jentsch.io/warten-auf-qwen3-coder-next/ habe ich beschrieben, wie ich versucht habe Qwen3-Coder-Next auf meinem Laptop mit Ollama zu installieren, was erst mal gescheitert ist. Aber da wollte ich wohl mit dem Kopf durch die Wand. Am Ende habe ich das Modell dann doch lokal installiert bekommen. Nur eben nicht mit Ollama. Stattdessen habe ich einfach llama.cpp genutzt.
Die Lösung war einfach. Ich habe die aktuelle llama.cpp Version für Vulkan heruntergeladen und entpackt und dann den folgenden Befehl ausgeführt.
llama-server -hf unsloth/Qwen3-Coder-Next-GGUF:Q4_K_MDas war’s schon. Nun läuft llama.cpp auf meinem Rechner und ich kann Qwen3-Coder-Next nutzen. Easy 🙂
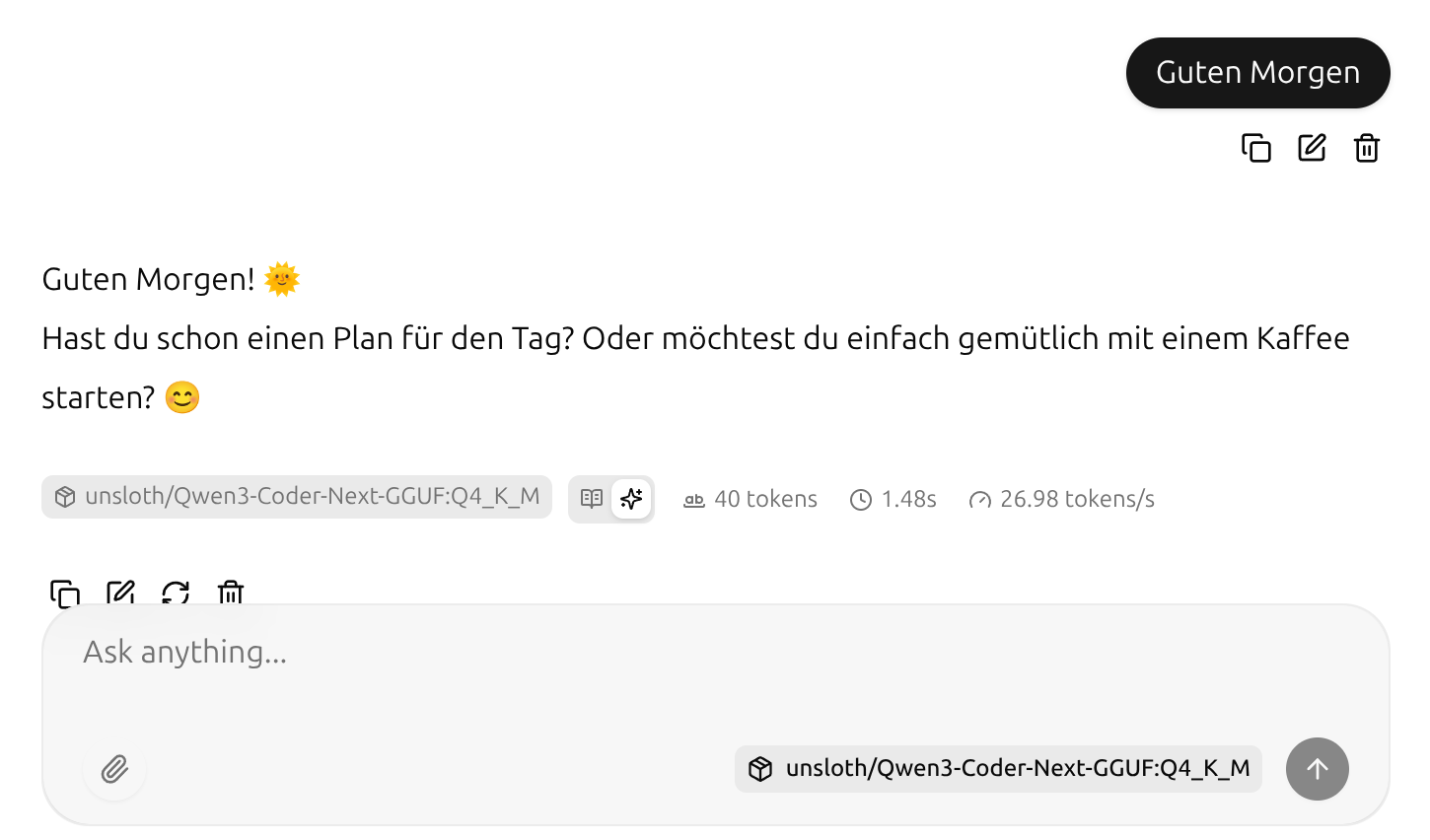
Das Modell läuft mit ca. 27 Token pro Sekunde ganz gut. Der Start dauert zwar ca. eine Minute, aber wenn es erst mal da ist dann sind die Antwortzeiten OK. Wenn das Modell so gut ist wie ich hoffe, schreibe ich mir einfach einen kleinen systemd Dienst, der direkt beim Start Booten ausgeführt wird und dann wie auch Ollama einfach im Hintergrund immer da ist.
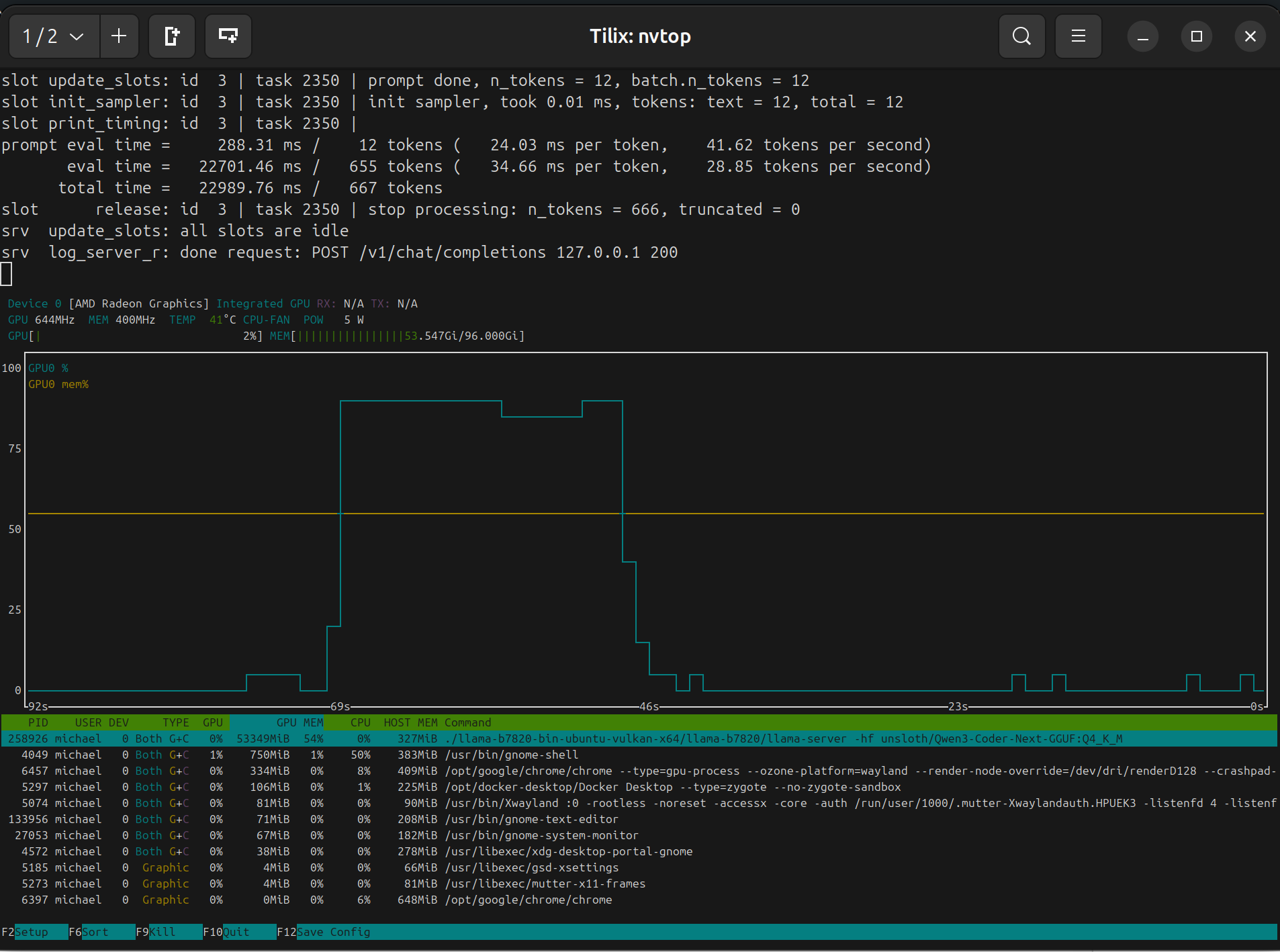
Wie man sieht, hält der RAM Verbrauch sich auch in Grenzen. Gerade mal ca. 54 GB RAM benötigt das Modell. Da ist ist noch genug Platz für andere Programme, Modelle, etc. …