
Der Fokus von Tag 1 liegt auf der Installation notwendiger Komponenten und der Erstellung einer ersten Spring Boot Applikation, die ein einfaches „Hello World“-Programm ausführt. Es wird die Verwendung eines lokalen Large Language Models (LLM) mittels llama.cpp und unsloth/Qwen3-30B-A3B-GGUF:Q4_K_M demonstriert.
1. Installation von llama.cpp
llama.cpp ist ein Projekt, das die Inferenz von Large Language Models auf Consumer-Hardware ermöglicht. Man kann es einfach unter https://github.com/ggml-org/llama.cpp/releases herunterladen und entpacken. Dabei gilt es nur darauf zu achten, die richtige Version zu installieren. Es gibt llama.cpp für Liniux, Windows, MacOS, CPU, GPU, CUDA, Vulkan, HIP, etc.
Nachdem man die korrekte Version heruntergeladen und entpackt hat stehen diverse Programme zur Verfügung. Für das Tutorial wird aber nur der llama-server verwendet.
2. Installation des Modells unsloth/Qwen3-Coder-Next-GGUF
Für die lokale Ausführung verwende ich das Modell unsloth/Qwen3-30B-A3B-GGUF:Q4_K_M. Man kann es von Huggingface herunterladen und mit dem Parameter „-m“ verwenden, aber der llama-server hat auch die Möglichkeit, das Modell selber herunterzuladen und auf der Platte zu cachen. Dazu kann man einfach dem folgenden Befehl auf der Konsole ausführen.
llama-server --port 8001 -hf unsloth/Qwen3-30B-A3B-GGUF:Q4_K_MDer llama-server läd dann das Modell dann einmalig herunter und speichert es (unter Linux) im Ordner „~/.cache/llama.cpp“ ab. Bei jedem weiteren Aufruf wird dann die Version aus dem Cache genommen und der Start des llama-servers geht recht schnell. Die Angabe „–port 8001“ gibt an, dass der HTTP Server auf dem Port 8001 läuft. Man kann das leicht überprüfen, in dem man im Browser „http://127.0.0.1:8001/“ eingibt. Wenn alles funktioniert, sollte man folgendes sehen:
Der llama-server bringt neben der Web-Oberfläche auch eine OpenAI kompatible /chat/completions API mit, die man in Langchain4J verwenden kann.
3. Installation von claude code
Die Installation von Claude Code erfolgt wie unter https://code.claude.com/docs/de/setup beschrieben. In meinem Fall ist das einfach der Aufruf von:
curl -fsSL https://claude.ai/install.sh | bashDanach kann man mit „claude –help“ prüfen, ob Claude Code korrekt installiert ist.
➜ ~ claude --help
Usage: claude [options] [command] [prompt]
Claude Code - starts an interactive session by default, use -p/--print for non-interactive output
Arguments:
prompt Your prompt
Options:
--add-dir <directories...> Additional directories to allow tool access to
--agent <agent> Agent for the current session. Overrides the 'agent' setting.
--agents <json> JSON object defining custom agents (e.g. '{"reviewer": {"description": "Reviews code",
"prompt": "You are a code reviewer"}}')
--allow-dangerously-skip-permissions Enable bypassing all permission checks as an option, without it being enabled by default.
Recommended only for sandboxes with no internet access.
--allowedTools, --allowed-tools <tools...> Comma or space-separated list of tool names to allow (e.g. "Bash(git:*) Edit")
--append-system-prompt <prompt> Append a system prompt to the default system prompt
--betas <betas...> Beta headers to include in API requests (API key users only)
--chrome Enable Claude in Chrome integration
-c, --continue Continue the most recent conversation in the current directory
--dangerously-skip-permissions Bypass all permission checks. Recommended only for sandboxes with no internet access.
-d, --debug [filter] Enable debug mode with optional category filtering (e.g., "api,hooks" or "!statsig,!file")
--disable-slash-commands Disable all skills
--disallowedTools, --disallowed-tools <tools...> Comma or space-separated list of tool names to deny (e.g. "Bash(git:*) Edit")
--fallback-model <model> Enable automatic fallback to specified model when default model is overloaded (only works
with --print)
--file <specs...> File resources to download at startup. Format: file_id:relative_path (e.g., --file
file_abc:doc.txt file_def:img.png)
--fork-session When resuming, create a new session ID instead of reusing the original (use with --resume
or --continue)
-h, --help Display help for command
--ide Automatically connect to IDE on startup if exactly one valid IDE is available
--include-partial-messages Include partial message chunks as they arrive (only works with --print and
--output-format=stream-json)
--input-format <format> Input format (only works with --print): "text" (default), or "stream-json" (realtime
streaming input) (choices: "text", "stream-json")
--json-schema <schema> JSON Schema for structured output validation. Example:
{"type":"object","properties":{"name":{"type":"string"}},"required":["name"]}
--max-budget-usd <amount> Maximum dollar amount to spend on API calls (only works with --print)
--mcp-config <configs...> Load MCP servers from JSON files or strings (space-separated)
--mcp-debug [DEPRECATED. Use --debug instead] Enable MCP debug mode (shows MCP server errors)
--model <model> Model for the current session. Provide an alias for the latest model (e.g. 'sonnet' or
'opus') or a model's full name (e.g. 'claude-sonnet-4-5-20250929').
--no-chrome Disable Claude in Chrome integration
--no-session-persistence Disable session persistence - sessions will not be saved to disk and cannot be resumed
(only works with --print)
--output-format <format> Output format (only works with --print): "text" (default), "json" (single result), or
"stream-json" (realtime streaming) (choices: "text", "json", "stream-json")
--permission-mode <mode> Permission mode to use for the session (choices: "acceptEdits", "bypassPermissions",
"default", "delegate", "dontAsk", "plan")
--plugin-dir <paths...> Load plugins from directories for this session only (repeatable)
-p, --print Print response and exit (useful for pipes). Note: The workspace trust dialog is skipped
when Claude is run with the -p mode. Only use this flag in directories you trust.
--replay-user-messages Re-emit user messages from stdin back on stdout for acknowledgment (only works with
--input-format=stream-json and --output-format=stream-json)
-r, --resume [value] Resume a conversation by session ID, or open interactive picker with optional search term
--session-id <uuid> Use a specific session ID for the conversation (must be a valid UUID)
--setting-sources <sources> Comma-separated list of setting sources to load (user, project, local).
--settings <file-or-json> Path to a settings JSON file or a JSON string to load additional settings from
--strict-mcp-config Only use MCP servers from --mcp-config, ignoring all other MCP configurations
--system-prompt <prompt> System prompt to use for the session
--tools <tools...> Specify the list of available tools from the built-in set. Use "" to disable all tools,
"default" to use all tools, or specify tool names (e.g. "Bash,Edit,Read").
--verbose Override verbose mode setting from config
-v, --version Output the version number
Commands:
doctor Check the health of your Claude Code auto-updater
install [options] [target] Install Claude Code native build. Use [target] to specify version (stable, latest, or
specific version)
mcp Configure and manage MCP servers
plugin Manage Claude Code plugins
setup-token Set up a long-lived authentication token (requires Claude subscription)
update Check for updates and install if availableFür das Hello Word heute werde ich Claude Code aber noch nicht verwenden. Den Start mache ich noch auf die „altmodische“ Art und weise. Allerdings erstelle ich schon mal ein Starter-Script, um Claude Code mit Modell unsloth/Qwen3-Coder-Next-GGUF über llama.cpp zu starten damit Claude Code auch komplett offline funktioniert. Das Starter Script sieht wie folgt aus, geht aber davon aus, dass der llama-server mit dem Modell unsloth/Qwen3-Coder-Next-GGUF:Q4_K_M auf Port 8080 läuft (Qwen3-Coder-30B-A3B.sh).
#!/bin/sh
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_API_KEY=""
export ANTHROPIC_BASE_URL=http://localhost:8080
claude --model unsloth/Qwen3-Coder-Next-GGUF:Q4_K_MDas kleine Shell-Skript setzt die Umgebungsvariablen, um das Anthropic-API-Interface auf einen lokalen Server umzubiegen: Es definiert einen (Dummy-)Auth-Token, leert den API-Key und legt als Basis-URL den lokal laufenden llama-server fest. Anschließend wird das claude-CLI gestartet, jedoch nicht gegen die echte Anthropic-Cloud, sondern gegen diesen lokalen Endpoint, und dabei das quantisierte Modell unsloth/Qwen3-Coder-Next-GGUF:Q4_K_M ausgewählt. Damit wird Claude als Client genutzt, um ein lokales LLM anzusprechen.
Claude Code mit unsloth/Qwen3-Coder-Next
5. Erstellen einer Spring Boot Starter App
Eine Spring Boot Applikation kann man leicht mit dem Spring Initializr unter https://start.spring.io/ generiern. Die von mir gewählte Konfiguration umfasst die folgenden Abhängigkeiten:
- Spring Web: Für die Entwicklung von Webanwendungen und RESTful Services.
- Spring Boot DevTools: Bietet schnelle Anwendungsneustarts und LiveReload für eine verbesserte Entwicklungserfahrung.
- Lombok: Eine Java-Annotation-Bibliothek zur Reduzierung von Boilerplate-Code.
- Thymeleaf: Eine serverseitige Java-Template-Engine.
- H2 Database: Eine schnelle In-Memory-Datenbank.
Die spezifische URL für die Generierung der Projektstruktur lautet:https://start.spring.io/#!type=gradle-project&language=java&platformVersion=3.5.10&packaging=jar&configurationFileFormat=properties&jvmVersion=21&groupId=com.jentsch.langchain4j&artifactId=demo&name=Langchain4J%20Demo%20&description=Langchain4J%20Demo%20App&packageName=com.jentsch.langchain4j.demo&dependencies=web,devtools,lombok,thymeleaf,h2
Nach dem Download wird das generierte Projekt entpackt und in IntelliJ geöffnet und die Abhängigkeit ‚dev.langchain4j:langchain4j-open-ai-spring-boot-starter:1.11.0-beta19‘ in in der build.gradle eingetragen.
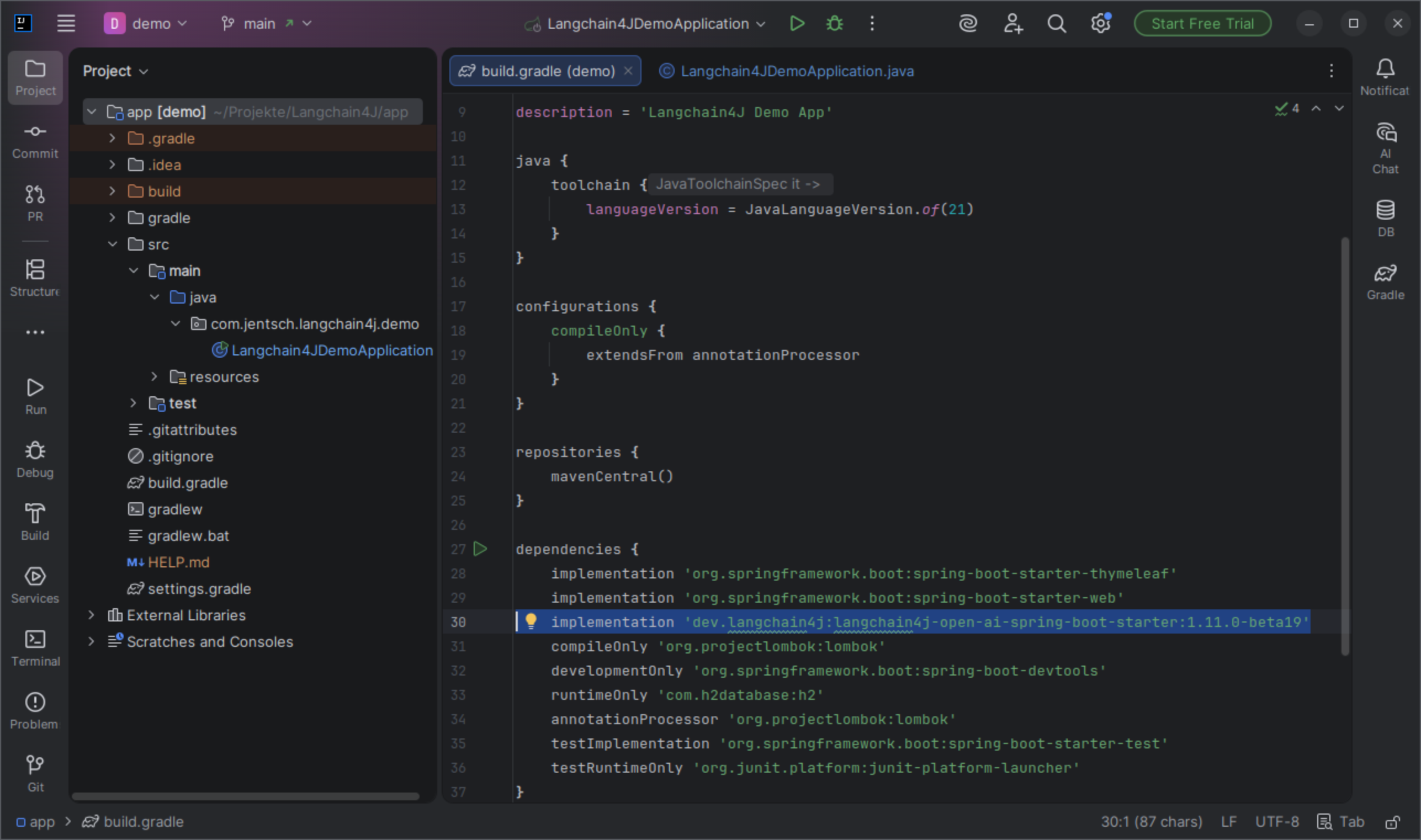
Die langchain4j-open-ai-spring-boot-starter-Abhängigkeit wird der build.gradle Datei hinzugefügt, um die Integration von Langchain4J in die Spring Boot Applikation zu ermöglichen.
dependencies {
implementation 'dev.langchain4j:langchain4j-open-ai-spring-boot-starter:1.11.0-beta19'
}Diese Abhängigkeit ermöglicht die Nutzung der Langchain4J-Funktionalitäten zur Interaktion mit Large Language Models.
7. Ausführen des einfachen Hello World Programms
Damit sind alle Vorbereitungen für das Hello World Programm erledigt und die eigentliche HelloWorld Klasse kann erstellt werden. Dazu ergänze ich in der Langchain4JDemoApplication Klasse einfach einen einfachen CommandLineRunner mit folgendem Inhalt.
@Component
public static class StartupTask implements CommandLineRunner {
@Value("${app.model.name}")
private String modelName;
@Value("${app.model.baseurl}")
private String baseUrl;
@Override
public void run(String... args) throws Exception {
System.out.println("✅ Application started successfully!");
ChatModel model = OpenAiChatModel.builder()
.apiKey("")
.baseUrl(baseUrl)
.modelName(modelName)
.build();
String answer = model.chat("Say Hello World");
System.out.println(answer);
System.exit(0);
}
}Der StartupTask ist als Spring @Component annotiert, was bedeutet, dass sie von Spring beim Start der Anwendung verwaltet wird. Sie implementiert das CommandLineRunner-Interface, wodurch die run-Methode der Klasse automatisch ausgeführt wird, sobald die Spring-Anwendung vollständig geladen und gestartet ist.
Innerhalb dieser Klasse werden die beiden Variablen modelName und baseUrl, durch die @Value-Annotation aus den application.properties injiziert, die den Namen des Modells und die Basis-URL definieren, die später für die Initialisierung des Chat-Modells verwendet werden.
In der run-Methode wird ein ChatModel-Objekt instanziiert. Dabei wird ein leerer der API-Schlüssel, der zuvor injizierte baseUrl und der modelName gesetzt. Nach der Initialisierung des Modells wird ein Chat-Befehl an das Modell gesendet, der es anweist, „Say Hello World“ zu sagen. Die Antwort des Modells wird auf der Konsole ausgegeben und die Anwendung mit System.exit(0) beendet.
Die gekürzte Ausgabe des Programms sieht wie folgt aus:
.....
17:39:16.609 [restartedMain] INFO c.j.l.d.Langchain4JDemoApplication - Started Langchain4JDemoApplication in 3.997 seconds (process running for 4.393)
17:39:16.610 [restartedMain] DEBUG o.s.b.a.ApplicationAvailabilityBean - Application availability state LivenessState changed to CORRECT
✅ Application started successfully!
17:39:16.731 [restartedMain] DEBUG o.s.s.c.ThreadPoolTaskExecutor - Initializing ExecutorService
17:39:16.778 [restartedMain] DEBUG i.m.c.u.i.l.InternalLoggerFactory - Using SLF4J as the default logging framework
17:39:16.779 [restartedMain] DEBUG o.s.web.client.DefaultRestClient - Writing [{
"model" : "unsloth/Qwen3-30B-A3B-GGUF:Q4_K_M",
"messages" : [ {
"role" : "user",
"content" : "Say Hello World"
} ],
"stream" : false
}] as "application/json" with org.springframework.http.converter.StringHttpMessageConverter
17:39:18.465 [restartedMain] DEBUG o.s.web.client.DefaultRestClient - Reading to [java.lang.String] as "application/json;charset=utf-8"
Hello World
17:39:18.486 [SpringApplicationShutdownHook] DEBUG o.s.b.a.ApplicationAvailabilityBean - Application availability state ReadinessState changed to REFUSING_TRAFFIC
17:39:18.487 [SpringApplicationShutdownHook] DEBUG o.s.b.w.s.c.AnnotationConfigServletWebServerApplicationContext - Closing org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@43a7a0a8, started on Sat Feb 07 17:39:12 CET 2026
17:39:18.487 [SpringApplicationShutdownHook] DEBUG o.s.c.s.DefaultLifecycleProcessor - Stopping beans in phase 2147482623
17:39:18.488 [SpringApplicationShutdownHook] INFO o.s.b.w.e.tomcat.GracefulShutdown - Commencing graceful shutdown. Waiting for active requests to complete
17:39:18.490 [tomcat-shutdown] INFO o.s.b.w.e.tomcat.GracefulShutdown - Graceful shutdown complete
17:39:18.491 [SpringApplicationShutdownHook] DEBUG o.s.c.s.DefaultLifecycleProcessor - Stopping beans in phase 2147481599
17:39:18.491 [tomcat-shutdown] DEBUG o.s.c.s.DefaultLifecycleProcessor - Bean 'webServerGracefulShutdown' completed its stop procedure
17:39:18.492 [SpringApplicationShutdownHook] DEBUG o.s.c.s.DefaultLifecycleProcessor - Bean 'webServerStartStop' completed its stop procedure
17:39:18.492 [SpringApplicationShutdownHook] DEBUG o.s.c.s.DefaultLifecycleProcessor - Stopping beans in phase 1073741823
17:39:18.492 [SpringApplicationShutdownHook] DEBUG o.s.c.s.DefaultLifecycleProcessor - Bean 'applicationTaskExecutor' completed its stop procedure
.....
Process finished with exit code 0
Wie man sieht, hat LangChain4J einen JSON String mit dem folgenden Inhalt an llama.cpp gesendet …
[{
"model" : "unsloth/Qwen3-30B-A3B-GGUF:Q4_K_M",
"messages" : [ {
"role" : "user",
"content" : "Say Hello World"
} ],
"stream" : false
}].. und Qwen3-30B-A3B hat mit „Hello World“ geantwortet. Das war also ein einfaches Hello World.
Fazit
Dieses einfache Hello World-Beispiel zeigt schön, was LangChain4J leistet: Es abstrahiert die direkte Kommunikation mit einem LLM auf ein sauberes, Java-freundliches API und nimmt einem die komplette Handhabung von Request-Strukturen, JSON-Formaten und Transportdetails ab. Statt sich mit Low-Level-HTTP-Calls oder Modell-spezifischen Eigenheiten auseinanderzusetzen, kann man sich auf das konzentrieren, was wirklich zählt – die fachliche Logik der Anwendung.
Gleichzeitig macht das Beispiel transparent, was unter der Haube passiert: LangChain4J generiert letztlich strukturierte JSON-Requests, die an ein Modell gesendet werden und verarbeitet die Antwort, so dass die Antwort wieder zurück in Java-Objekte übersetzt wird.
Auch wenn der Aufwand für ein einfaches Hello World etwas übertrieben wirkt, ist es erste Schritt. Von hier aus lassen sich ohne grundlegende Architekturänderungen deutlich anspruchsvollere Szenarien umsetzen – von Chat-Anwendungen über RAG-Pipelines bis hin zu agentenbasierten Workflows.
Der komplette Sourcecode dazu liegt unter https://github.com/msoftware/Langchain4J-Tutorial