Das Trainieren oder Finetuning von großen Sprachmodellen (LLMs) ist oft ein langwieriger Prozess, der sich über viele Stunden oder sogar Tage erstrecken kann. Währenddessen ständig den Fortschritt im Auge zu behalten, kann mühsam sein. Man muss sich per SSH auf dem Trainingsserver einloggen, TensorBoard starten oder Log-Dateien durchsuchen. Das ist nicht nur umständlich, sondern auch leicht zu vergessen.
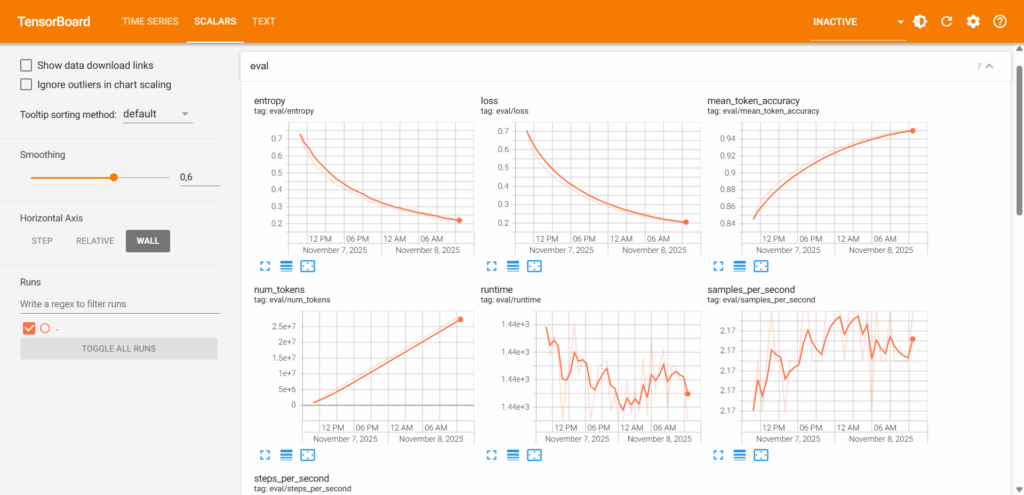
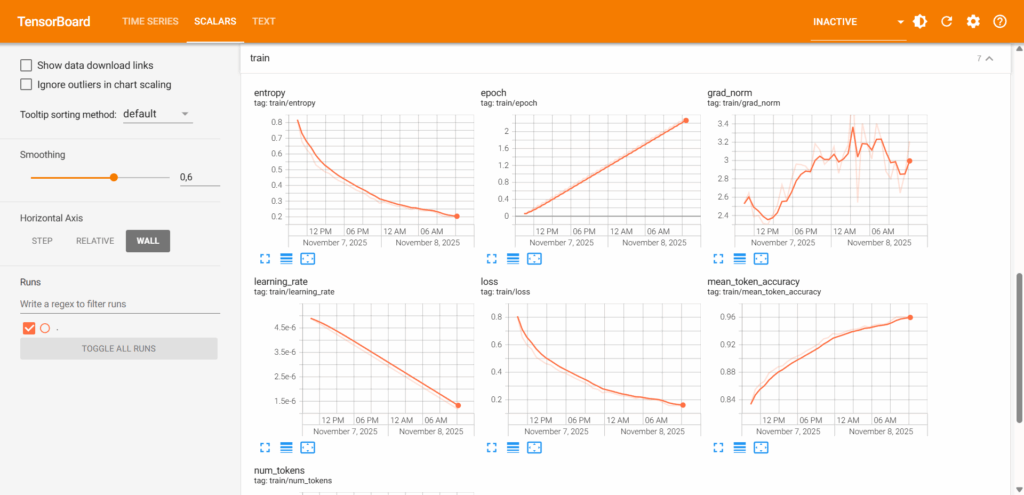
Ich wollte eine einfachere Lösung: automatische, stündliche Updates direkt auf mein Handy, die mir auf einen Blick zeigen, wie das Training verläuft. Also habe ich mit dem einfachen Push-Benachrichtigungsdienst ntfy, einem Python-Skript und einem Cronjob genau das realisiert.
Das Ziel: Ein visueller Überblick auf Abruf
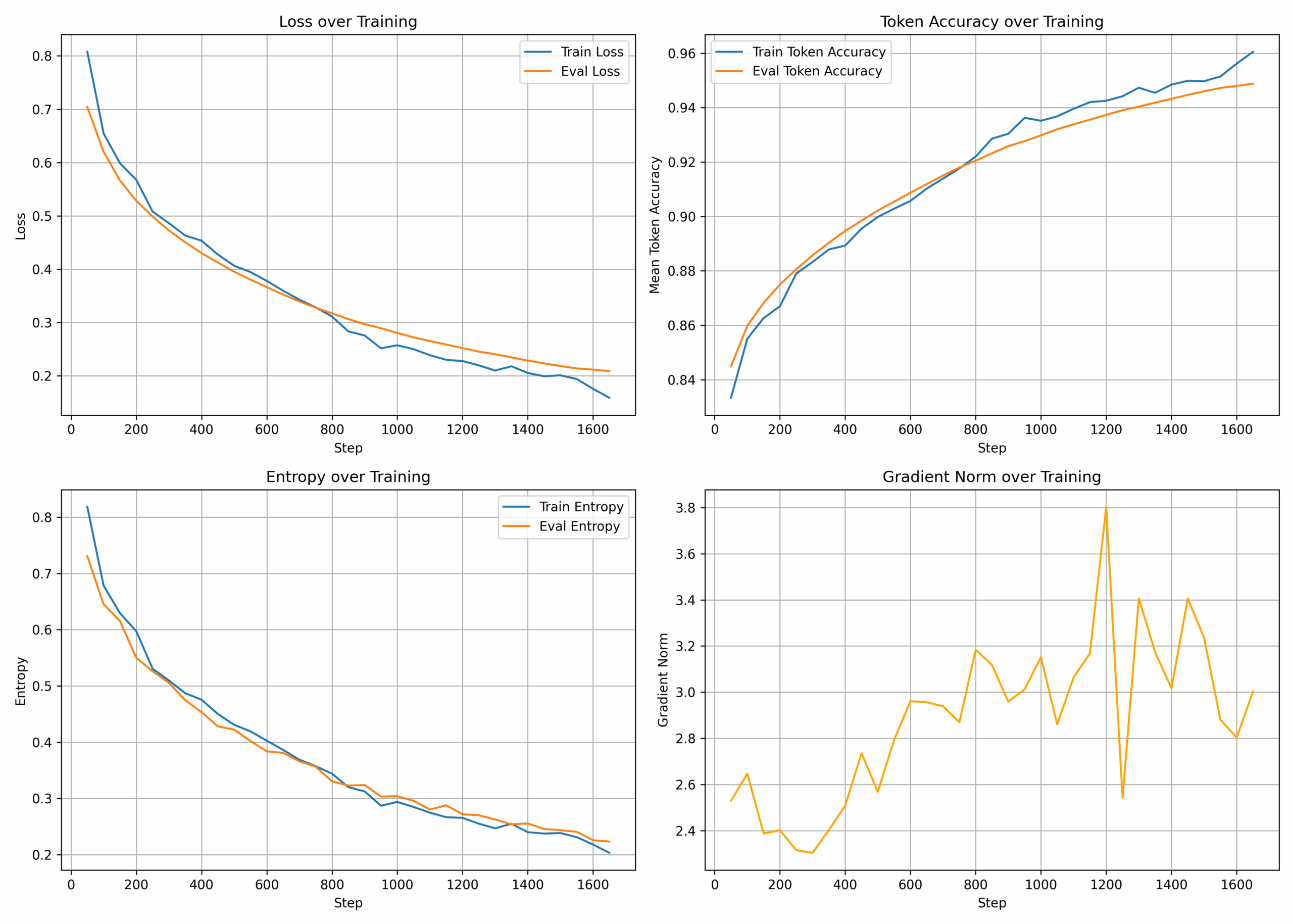
Jede Stunde erhalte ich nun eine Benachrichtigung auf meinem Smartphone, die so aussieht:
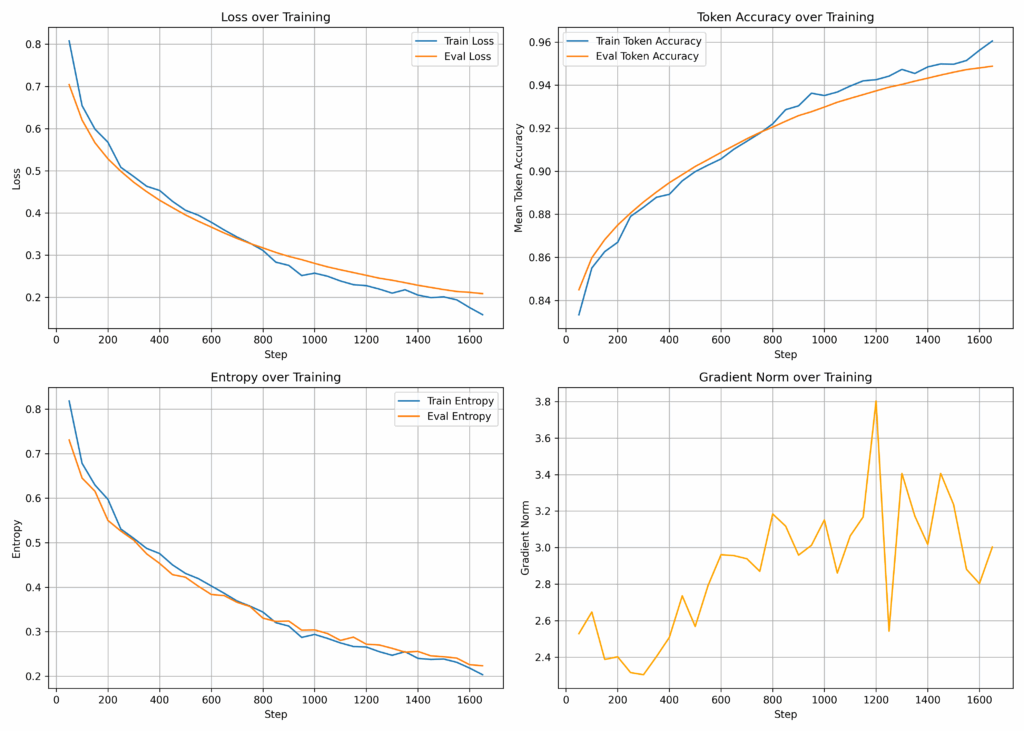
Die Grafik selbst besteht aus vier Diagrammen:
- Loss over Training (Verlustkurve)
Dies ist die wichtigste Metrik. Sie zeigt, wie gut das Modell lernt, die Trainingsdaten vorherzusagen. Sowohl der Trainings- als auch der Evaluierungsverlust sollten idealerweise sinken. Steigt der Evaluierungsverlust, während der Trainingsverlust weiter sinkt, ist das ein Zeichen für Overfitting. - Token Accuracy over Training (Token-Genauigkeit)
Diese Kurve zeigt, wie präzise das Modell das nächste Token in einer Sequenz vorhersagt. Eine steigende Genauigkeit ist ein gutes Zeichen. - Entropy over Training (Entropie)
Die Entropie ist ein Maß für die Unsicherheit des Modells bei seinen Vorhersagen. Ein sinkender Wert bedeutet, dass das Modell mit der Zeit „selbstbewusster“ wird. - Gradient Norm over Training (Gradientennorm)
Diese Metrik ist nützlich für die Diagnose von Trainingsproblemen. Große Spitzen können auf instabiles Training oder „explodierende Gradienten“ hindeuten.
Mit diesen vier Diagrammen kann ich schnell beurteilen, ob das Training nach Plan verläuft oder ob ich eingreifen muss.
Die Bausteine: Was man dafür braucht
Mein Setup ist bewusst einfach gehalten und basiert auf Tools, die ich schon lange im Einsatz habe
- Ein Trainingsserver
Mein Jetson Orin Developer Kit 64GB auf dem das LLM-Training läuft. - Python 3
Mit den Bibliothekenmatplotlibundtensorboard - ntfy
Ein simpler, Open-Source-Benachrichtigungsdienst. Man kann den öffentlichen Serverntfy.shnutzen oder wie ich einen eigenen Server hosten. - Ein Webserver
Um das generierte Bild temporär öffentlich zugänglich zu machen, damit ntfy es anhängen kann. - Standard-Linux-Tools
cronfür die zeitgesteuerte Ausführung,scpzum Hochladen der Grafik undcurlzum Senden der Benachrichtigung.
Schritt 1: Die Grafik mit Python und Matplotlib erstellen
Das Herzstück des Systems ist ein Python-Skript, das die Trainingsdaten aus den TensorBoard-Logfiles liest und daraus die oben gezeigte Grafik erstellt. TensorBoard ist fantastisch, aber manchmal möchte man die Daten programmatisch weiterverarbeiten. Glücklicherweise bietet die tensorboard-Bibliothek genau dafür eine Schnittstelle.
Mein Skript create_chart.py sieht wie folgt aus:
import matplotlib.pyplot as plt
import json
from tensorboard.backend.event_processing import event_accumulator
# Pfad zu deiner TensorBoard-Logdatei anpassen
ea = event_accumulator.EventAccumulator('Qwen2.5-Coder-w3max-0.5B_3/runs/Nov02_10-03-55_ubuntu/events.out.tfevents.ubuntu')
ea.Reload()
# Alle verfügbaren skalaren Metriken auslesen
tags = ea.Tags()['scalars']
# Daten in einem Dictionary sammeln
data = {}
for t in tags:
data[t] = [{'step': e.step, 'value': e.value} for e in ea.Scalars(t)]
# Plots vorbereiten (2x2-Raster)
plt.figure(figsize=(14, 10))
# 1. Loss
plt.subplot(2,2,1)
plt.plot([x['step'] for x in data.get('train/loss', [])],
[x['value'] for x in data.get('train/loss', [])], label='Train Loss')
plt.plot([x['step'] for x in data.get('eval/loss', [])],
[x['value'] for x in data.get('eval/loss', [])], label='Eval Loss')
plt.xlabel('Step')
plt.ylabel('Loss')
plt.title('Loss over Training')
plt.legend()
plt.grid(True)
# 2. Token Accuracy
plt.subplot(2,2,2)
plt.plot([x['step'] for x in data.get('train/mean_token_accuracy', [])],
[x['value'] for x in data.get('train/mean_token_accuracy', [])], label='Train Token Accuracy')
plt.plot([x['step'] for x in data.get('eval/mean_token_accuracy', [])],
[x['value'] for x in data.get('eval/mean_token_accuracy', [])], label='Eval Token Accuracy')
plt.xlabel('Step')
plt.ylabel('Mean Token Accuracy')
plt.title('Token Accuracy over Training')
plt.legend()
plt.grid(True)
# 3. Entropy
plt.subplot(2,2,3)
plt.plot([x['step'] for x in data.get('train/entropy', [])],
[x['value'] for x in data.get('train/entropy', [])], label='Train Entropy')
plt.plot([x['step'] for x in data.get('eval/entropy', [])],
[x['value'] for x in data.get('eval/entropy', [])], label='Eval Entropy')
plt.xlabel('Step')
plt.ylabel('Entropy')
plt.title('Entropy over Training')
plt.legend()
plt.grid(True)
# 4. Gradient Norm
plt.subplot(2,2,4)
plt.plot([x['step'] for x in data.get('train/grad_norm', [])],
[x['value'] for x in data.get('train/grad_norm', [])], label='Grad Norm', color='orange')
plt.xlabel('Step')
plt.ylabel('Gradient Norm')
plt.title('Gradient Norm over Training')
plt.grid(True)
# Layout optimieren, damit sich die Titel nicht überlappen
plt.tight_layout()
# Chart als PNG-Datei speichern
plt.savefig("training_metrics_chart.png", dpi=300)
print("Chart als 'training_metrics_chart.png' gespeichert.")
Was passiert hier im Detail?
EventAccumulator
Diese Klasse lädt die binären Log-Dateien (.tfevents), die von deinem Training-Framework (z.B. PyTorch, TensorFlow, Hugging Face Trainer) geschrieben werden. Hier muss man den Pfad zu der spezifischen Logdatei anpassen. Könnte man schöner machen, aber ….- Daten extrahieren
Das Skript liest alle skalaren Werte (Zahlen, die sich über die Zeit ändern) und speichert sie in einem Dictionary. - Matplotlib-Plots
Mitmatplotlib.pyplotwird ein 2×2-Raster aus Plots erstellt. Für jede Metrik werden die Trainings- und Evaluierungswerte (falls vorhanden) in ein eigenes Diagramm gezeichnet. savefig
Am Ende wird die komplette Abbildung alstraining_metrics_chart.pngim aktuellen Verzeichnis gespeichert.
Schritt 2
Automatisierung mit einem Shell-Skript und Cronjob
Um den Prozess zu automatisieren habe ich noch ein kleines Shell-Skript erstellt, das sich um die gesamte Logik: Grafik erstellen, hochladen und die Benachrichtigung senden kümmert.
#!/bin/sh
# Schritt 1: Das Python-Skript ausführen, um die neuste Grafik zu erstellen
python create_chart.py
# Schritt 2: Die Grafik auf einen Webserver hochladen, damit sie öffentlich erreichbar ist
# Passe den Host und den Zielpfad an deine Umgebung an
scp training_metrics_chart.png BENUTZER@SERVER:/var/www/VERZEICHNIS
# Schritt 3: Eine Benachrichtigung an den ntfy-Server senden
curl \
-H "Attach: https://URL/training_metrics_chart.png" \
-d "Training update" \
https://ntfy.sh/qwen-coder
Die einzelnen Befehle:
python create_chart.py
Führt das Skript aus Schritt 1 aus.scp
Kopiert dietraining_metrics_chart.pngper Secure Copy auf meinen Webserver in ein Verzeichnis, das über eine öffentliche URL erreichbar ist.curl
Sendet die eigentliche Benachrichtigung.-H "Attach: ...":
Dies ist eine spezielle ntfy-Funktion. Sie weist ntfy an, die Datei von der angegebenen URL herunterzuladen und an die Benachrichtigung anzuhängen.-d "Training update"
Der Text der Benachrichtigung.https://URL/qwen-coder:
Die URL deines ntfy-Themas (Topics). Jeder, der dieses Thema abonniert, erhält die Nachricht. Ändere dies in dein persönliches, geheimes Thema!
Schritt 3: Alles mit einem Cronjob verbinden
Der letzte Schritt ist, das Shell-Skript regelmäßig auszuführen. Dafür ist der gute alte cron perfekt geeignet.
Crontab-Konfiguration mit crontab -e öffnen und folgende Zeile ergänzen:
0 * * * * /pfad/zum/script.sh
Diese Zeile bedeutet:
0: Zur Minute 0*: jeder Stunde*: an jedem Tag des Monats*: in jedem Monat*: an jedem Wochentag …führe das Skript unter/pfad/zu/deinem/script.shaus.
Wichtig ist, dass der Pfad zum Shell-Skript korrekt ist und das Skript ausführbar ist (chmod +x script.sh).
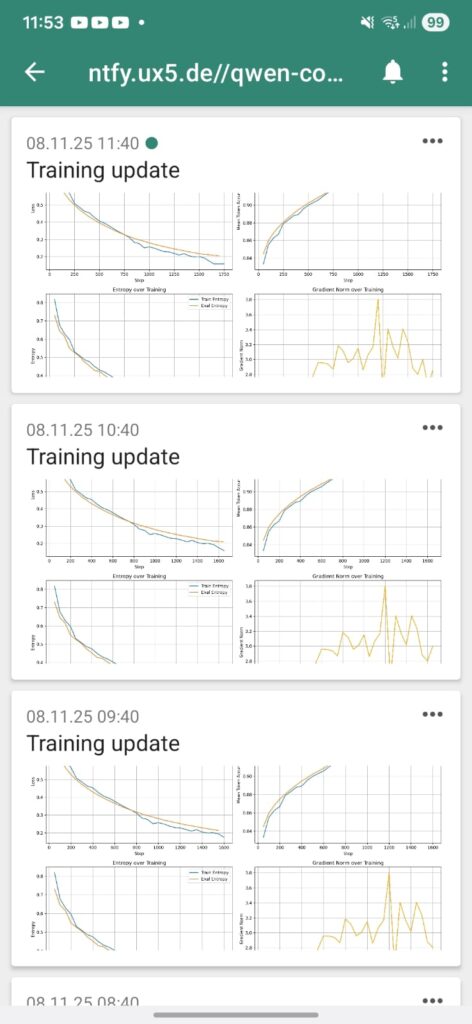
Wenn alles funktioniert und man die ntfy App installiert hat bekommt man stündlich ein Update aufs Handy. Das sieht dann z.B. wie folgt aus:
Fazit
Das war’s schon! Mit diesem einfachen, aber leistungsstarken Setup habe ich jetzt eine vollautomatische Überwachung für meine LLM-Trainings. Ich muss nicht mehr aktiv nachsehen, wie es läuft, sondern werde stündlich informiert. Wenn eine Kurve seltsam aussieht, kann ich sofort reagieren.
Das Schöne an diesem Ansatz ist seine Flexibilität. Man kann das Python-Skript leicht anpassen, um andere Metriken zu visualisieren, das Aussehen der Diagramme ändern oder sogar statistische Zusammenfassungen in den Benachrichtigungstext einfügen. Für mich ist es die perfekte Lösung um die Lücke zwischen langen, unbeaufsichtigten Prozessen und dem Bedürfnis, informiert zu bleiben, zu schließen.