Eine empirische Studie von: Xingyu Zheng, Yuye Li, Haoran Chu, Yue Feng, Xudong Ma, Jie Luo, Jinyang Guo, Haotong Qin, Michele Magno, Xianglong Liu
https://arxiv.org/pdf/2505.02214
Wie robust ist Qwen3, wenn es um die Reduzierung der Modellgröße durch Low-Bit-Quantisierung geht? Ein internationales Forscherteam hat genau das untersucht und liefert nun erste Antworten.
Warum Quantisierung?
Große Sprachmodelle (LLMs) wie Qwen3 sind leistungsfähig, aber auch ressourcenintensiv. Für den Einsatz in Geräten mit begrenzten Ressourcen, wie Smartphones oder Edge-Computing-Plattformen, ist es entscheidend, diese Modelle zu komprimieren. Low-Bit-Quantisierung, bei der die Präzision der Modellgewichte reduziert wird, ist eine vielversprechende Methode, um Speicherbedarf und Rechenleistung zu minimieren. Allerdings kann dies die Leistung des Modells beeinträchtigen.
Die Studie im Überblick
Das Forscherteam evaluierte fünf etablierte Post-Training-Quantisierungsmethoden:
Round-To-Nearest (RTN)
Bei diesem Verfahren werden die ursprünglichen Fließkommazahlen der Gewichte eines neuronalen Netzes auf den nächstgelegenen darstellbaren Wert im niedrigeren Bitformat gerundet. Obwohl RTN rechengünstig in der Anwendung ist, kann es, insbesondere bei sehr niedrigen Bitbreiten, zu einem deutlicheren Verlust an Modellgenauigkeit führen.
GPTQ
Generative Post-Trained Quantization ist eine Methode, die speziell für die Quantisierung von großen Sprachmodellen (LLMs) entwickelt wurde. Ziel ist es, die Modellgröße auf 2-, 3- oder 4-Bit-Gewichte zu reduzieren, während der Genauigkeitsverlust minimiert wird. Dies wird erreicht, indem die Gewichte schichtweise so quantisiert werden, dass der mittlere quadratische Fehler (MSE) der Gewichte minimiert wird.
AWQ
Activation-aware Weight Quantization versucht den Genauigkeitsverlust bei der Komprimierung von großen Sprachmodellen zu reduzieren, indem sie die Aktivierungen des Modells berücksichtigt. Die Idee von AWQ ist, dass nicht alle Gewichte im Modell gleich wichtig sind. AWQ identifiziert einen kleinen Prozentsatz der Gewichte, die für die Leistung des LLMs am wichtigsten sind, indem es die Verteilung der Aktivierungen analysiert und diese wichtigen Gewichte von der Quantisierung ausnimmt oder sie mit höherer Präzision behandelt.
SmoothQuant
Diese Methode führt eine mathematische Transformation durch, bei der die Quantisierung von den Aktivierungen auf die Gewichte verlagert wird, indem ein Skalierungsfaktor angewendet wird. Dadurch werden Aktivierungen „geglättet“ und leichter quantisierbar, während die Gewichte entsprechend angepasst werden. SmoothQuant ermöglicht so eine präzisere Quantisierung von LLMs auf niedrigere Bitbreiten, sowohl für Gewichte.
BiLLM
BiLLM zielt darauf ab, große Sprachmodelle auf extrem niedrige Bitbreiten, insbesondere nahe an 1-Bit (binär), zu komprimieren. Diese Methode erreicht eine sehr aggressive Komprimierung, indem sie signifikante Gewichte durch Restnäherung behandelt und nicht signifikante Gewichte gruppiert quantisiert.
Diese Methoden wurden auf Qwen3-Modelle mit unterschiedlichen Größen von 0,6B bis 72B Parametern angewendet. Die Quantisierung erfolgte mit Bitbreiten von 1 bis 8 Bit. Zur Bewertung der Leistung wurden verschiedene Benchmarks herangezogen. Hier ein Beispiel Plot aus der Studie.
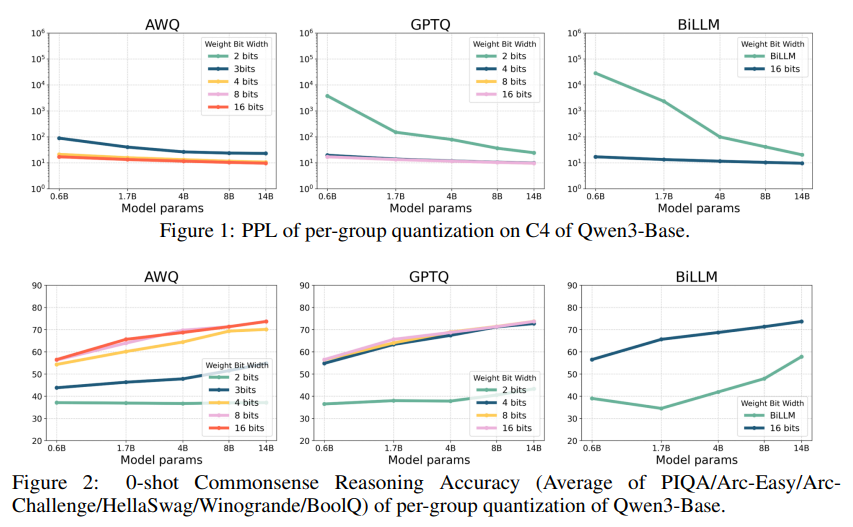
AWQ und GPTQ können die Genauigkeit bei Commonsense Reasoning Aufgaben bis zu 4-Bit gut erhalten. Der Leistungsabfall wird bei 3-Bit (für AWQ) und insbesondere bei 2-Bit deutlicher. BiLLM zeigt den größten Genauigkeitsverlust, aber die Leistung ist angesichts der extremen Komprimierung immer noch gut. Generell profitieren alle Methoden und Bitbreiten von größeren Modellparametern. Die Diagramme illustrieren den typischen Kompromiss zwischen Kompressionsrate und Modellleistung.
Ergebnisse und Erkenntnisse
Die Studie zeigt, dass Qwen3 bei moderaten Bitbreiten (z. B. 8 Bit) seine Leistung weitgehend beibehält. Allerdings nimmt die Leistung bei extrem niedrigen Bitbreiten (1–2 Bit) deutlich ab, insbesondere bei sprachbezogenen Aufgaben. Im Vergleich zu anderen Modellen wie LLaMA3 zeigt Qwen3 unter ultra-niedriger Präzision stärkere Leistungseinbußen.
Diese Ergebnisse unterstreichen die Herausforderungen bei der Komprimierung großer Sprachmodelle und die Notwendigkeit weiterer Forschung, um die Leistungseinbußen bei extremen Quantisierungsstufen zu minimieren.
Fazit
Die Studie bietet interessante Einblicke in die Auswirkungen der Low-Bit-Quantisierung auf Qwen3 und legt den Grundstein für zukünftige Arbeiten zur effizienten Bereitstellung großer Sprachmodelle in ressourcenbeschränkten Umgebungen. Die vollständige Studie ist auf arXiv verfügbar.
