
Chain-of-Thought (CoT) ist eine Technik, die die Fähigkeit von Sprachmodellen (LLMs) bei komplexen, mehrstufigen Aufgaben verbessert. Anstatt eine direkte Antwort zu erzwingen, instruiert CoT das Modell, seine Schlussfolgerungen schrittweise herzuleiten und diesen Denkprozess explizit darzulegen, bevor das finale Ergebnis präsentiert wird. Das DSPy-Framework stellt für diesen Zweck das Modul dspy.ChainOfThought bereit.
Theoretische Grundlagen von Chain of Thought (CoT)
Standard-Prompting fordert ein LLM auf, direkt von einer Eingabe zu einer Ausgabe zu gelangen. Bei Aufgaben, die mehrere logische Schritte erfordern, ist dieser Ansatz fehleranfällig, da das Modell gezwungen ist, den gesamten Denkprozess intern und ohne explizite Struktur zu verarbeiten. Die CoT-Methode modifiziert diesen Prozess. Sie zerlegt die Aufgabenlösung in zwei Phasen:
Reasoning (Schlussfolgern)
Das Modell generiert eine schrittweise Herleitung der Lösung. Jeder Schritt baut logisch auf dem vorherigen auf. Dieser Prozess wird als „Rationale“ oder „Gedankenkette“ bezeichnet.
Answering (Antworten)
Basierend auf der abgeschlossenen Herleitung extrahiert das Modell die endgültige Antwort.
Durch das explizite Generieren der Gedankenkette wird das Modell angeleitet, einem strukturierten Lösungsweg zu folgen. Dies reduziert das Risiko von Rechen- oder Logikfehlern und erhöht die Transparenz und Interpretierbarkeit des Ergebnisses. Der Anwender kann den Denkprozess nachvollziehen und potenzielle Fehlerquellen identifizieren.
Diese Technik ist heute in so gut wie allen kommerziellen Modellen integriert.
Google AI Studio erzeugt eine Gedankenkette, wenn man sie nicht explizit deaktiviert.

ChatGPT hat eine „Denke nach“ Funktion, die man manuell aktivieren kann.

Der Qwen Chat hat eine „Denken“ Funktion bei man sogar die maximale Länge des Nachdenkens kontrollieren kann.
Bei Open Source Modellen sieht es nicht anders aus. Auch hier gibt es diverse Modelle die darauf trainiert sind, erst „nachzudenken“ und dann zu antworten.
- moonshotai/Kimi-K2-Thinking
- Qwen/Qwen3-VL-4B-Thinking
- ByteDance/Ouro-2.6B-Thinking
- …..
Sucht man bei Huggingface nach Modellen mit thinking im Namen die im GGUF Format vorliegen findet man aktuell 764 Modelle und es werden kontinuierlich mehr.
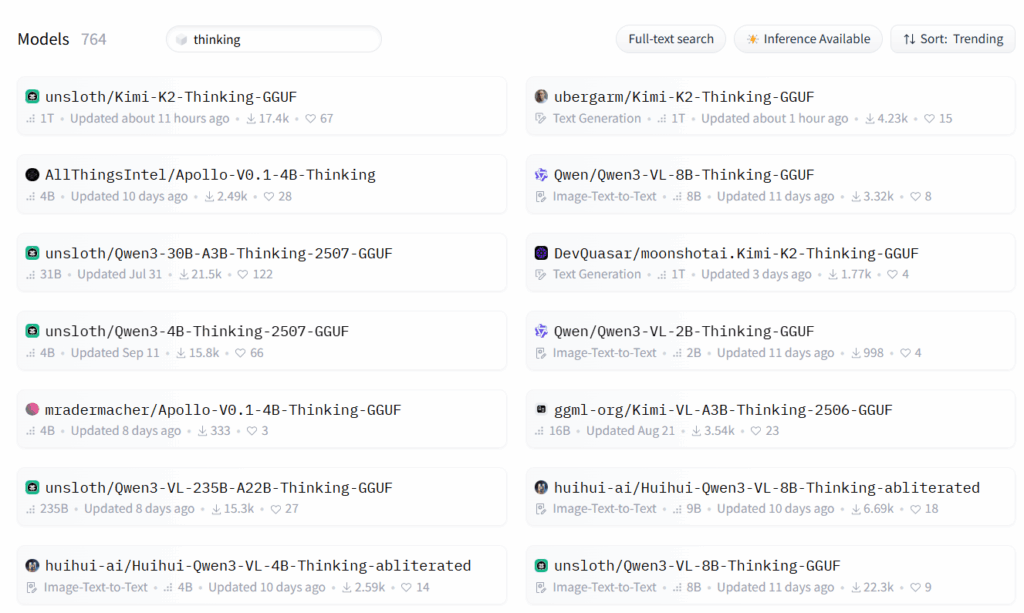
Thinking ist ein Trend bei Modellen, der zwar die Inference Kosten erhöht da mehr Token erzeugt werden, aber dafür die Qualität der Antwort deutlich verbessert. Ich bleibe für den Moment erst mal bei dem Qwen3-VL-8B-Instruct Modell. Es ist kein spezielles Thinking Modell, aber evtl. bringt es DSPy ja doch zum nachdenken. Mal sehen ….
Praktische Implementierung in DSPy
Die Umsetzung erfolgt unter Verwendung des dspy.ChainOfThought-Moduls. Dieses Modul benötigt eine Signatur, die die Struktur der Eingabe und der finalen Ausgabe definiert. Das Modul fügt automatisch die Anweisung zur schrittweisen Herleitung in den Prompt ein.
Szenario: Eine einfache Logikfrage, bei der die Position einer Person nach mehreren Bewegungen bestimmt werden muss.
Konfiguration der Umgebung
Zunächst muss die DSPy-Umgebung konfiguriert werden. Dies umfasst die Initialisierung eines Sprachmodells (LM), beispielsweise über die OpenAI-API.
import dspy
from dspy.teleprompt import BootstrapFewShot
local_llm = dspy.LM(
"openai/Qwen3-VL-8B-Instruct-Q4_K_M.gguf",
api_base="http://localhost:8080/v1",
api_key="no_key_needed"
)
dspy.configure(lm=local_llm)Definition der Signatur
Die Signatur definiert die erwarteten Felder für die Aufgabe. Für diese Logikfrage wird ein kontext als Eingabe und eine antwort als finale Ausgabe festgelegt. Die Beschreibung innerhalb der Signatur dient als Anweisung für das LLM.
# Definition der Ein- und Ausgabefelder für die Aufgabe
class LogikFrageSignatur(dspy.Signature):
"""Beantwortet eine Frage, die logisches Schlussfolgern erfordert."""
kontext = dspy.InputField(desc="Die zu lösende Logikfrage.")
antwort = dspy.OutputField(desc="Die endgültige, knappe Antwort.")Implementierung des Chain-of-Thought-Moduls
Anstelle eines einfachen dspy.Predict-Moduls wird dspy.ChainOfThought verwendet. Dieses Modul erhält die zuvor definierte Signatur als Argument.
# Die Logikfrage, die das Modell lösen soll
frage = "Arthur ist im Wohnzimmer. Er geht in die Küche, wo auch Berta ist. Dann geht Arthur ins Schlafzimmer. Wo ist Arthur am Ende?"
# Initialisierung des ChainOfThought-Moduls mit der Signatur
chain_of_thought_modul = dspy.ChainOfThought(LogikFrageSignatur)
# Ausführung des Moduls mit der Frage
ergebnis = chain_of_thought_modul(kontext=frage)Analyse der Ergebnisse
Die Ausführung des Moduls liefert ein Ergebnis, das sowohl die generierte Gedankenkette (rationale) als auch die finale Antwort (antwort) enthält.
Ausgabe des Modells:
Prediction(
reasoning='Arthur beginnt im Wohnzimmer. Er geht dann in die Küche, wo Berta ebenfalls ist. Anschließend geht er ins Schlafzimmer. Da keine weiteren Bewegungen beschrieben werden, ist Arthur am Ende im Schlafzimmer.',
antwort='im Schlafzimmer'
)Interpretation der Ausgabe:
rationale
Dieses Feld enthält die vom LLM generierte Gedankenkette. Das Modell hat die Ausgangsposition identifiziert, die erste Bewegung in die Küche nachvollzogen und die zweite Bewegung ins Schlafzimmer registriert. Die irrelevante Information über Berta wurde korrekt ignoriert und schlussgefolgert, dass Arthur am Ende im Schlafzimmer ist.antwort
Dieses Feld enthält die extrahierte Endantwort, die direkt aus den Schritten derrationaleabgeleitet wird.
Das Ergebnis demonstriert, dass das Modell durch die CoT-Instruktion einen nachvollziehbaren und korrekten Lösungsweg generiert hat. Ein direktes dspy.Predict hätte möglicherweise ebenfalls die richtige Antwort geliefert.
Analyse der Prompts
Mit local_llm.inspect_history(n=1) kann man den Prompt und die Antwort vom LLM analysieren. CoT erzeugt keine Prompt Kette. Daher reicht es den letzten Prompt mit n=1 ausgeben zu lassen.
System message:
Your input fields are:
1. `kontext` (str): Die zu lösende Logikfrage.
Your output fields are:
1. `reasoning` (str):
2. `antwort` (str): Die endgültige, knappe Antwort.
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## kontext ## ]]
{kontext}
[[ ## reasoning ## ]]
{reasoning}
[[ ## antwort ## ]]
{antwort}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Beantwortet eine Frage, die logisches Schlussfolgern erfordert.
User message:
[[ ## kontext ## ]]
Arthur ist im Wohnzimmer. Er geht in die Küche, wo auch Berta ist. Dann geht Arthur ins Schlafzimmer. Wo ist Arthur am Ende?
Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## antwort ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`.
Response:
[[ ## reasoning ## ]]
Arthur beginnt im Wohnzimmer. Er geht dann in die Küche, wo Berta ebenfalls ist. Anschließend geht er ins Schlafzimmer. Da keine weiteren Bewegungen beschrieben werden, ist Arthur am Ende im Schlafzimmer.
[[ ## antwort ## ]]
im Schlafzimmer
[[ ## completed ## ]]
Bestandteile des Prompts
Der Prompt gliedert sich wie schon in den letzten Tagen festgestellt in zwei Hauptteile: die Systemnachricht (System message) und die Benutzernachricht (User message). Die Systemnachricht fungiert als eine Meta-Instruktion, die dem LLM das grundlegende Regelwerk für die Interaktion vorgibt.
- Definition der Ein- und Ausgabefelder
Your input fields are: 1. kontext (str): Die zu lösende Logikfrage.Your output fields are: 1. reasoning (str): 2. antwort (str): Die endgültige, knappe Antwort.
dspy.Signature. Das Feldkontextstammt aus demdspy.InputField, und das Feldantwortaus demdspy.OutputField. Das Feldreasoningwird vomdspy.ChainOfThought-Modul automatisch und implizit hinzugefügt. Die Beschreibungen ("Die zu lösende Logikfrage.") werden ebenfalls direkt aus der Signatur übernommen und dienen dem LLM als semantischer Kontext für jedes Feld. - Strukturvorgabe
[[ ## kontext ## ]] {kontext}[[ ## reasoning ## ]] {reasoning}[[ ## antwort ## ]] {antwort}[[ ## completed ## ]]
[[ ## Feldname ## ]]-Syntax dient als eindeutiger, maschinenlesbarer Trenner (Delimiter). Dies zwingt das LLM, seine Ausgabe in eine klar definierte Struktur zu bringen. Das Ergebnis ist kein Fließtext, sondern eine formatierte Zeichenkette, die von DSPy zuverlässig geparst werden kann, um die Werte fürreasoningundantwortzu extrahieren. - Zielsetzung (Objective)
your objective is: Beantwortet eine Frage, die logisches Schlussfolgern erfordert.
LogikFrageSignaturübernommen. Sie gibt dem LLM eine übergeordnete Anweisung zum Zweck der Aufgabe und stellt sicher, dass das Modell das Gesamtziel versteht.
Die Benutzernachricht wendet die in der Systemnachricht definierten Regeln auf eine spezifische Instanz an.
- Strukturierte Eingabe
[[ ## kontext ## ]] Arthur ist im Wohnzimmer. ... Wo ist Arthur am Ende?
kontext-Feld eingefügt. Dadurch wird dem LLM signalisiert, welche Information zu welchem Feld gehört. - Handlungsanweisung
Respond with the corresponding output fields, starting with...
reasoning→antwort→completed) zu halten. Diese Anweisung ist der entscheidende Mechanismus, der das Chain-of-Thought-Verhalten aktiviert.
Analyse der Modell-Antwort
Die Antwort des Modells demonstriert die Wirksamkeit des strukturierten Prompts.
Strukturtreue
Das Modell hält sich exakt an die vorgegebene Struktur. Es verwendet die [[ ## Feldname ## ]]-Trenner wie gefordert. Der [[ ## completed ## ]]-Marker signalisiert das Ende der Ausgabe, was den Parsing-Prozess für DSPy robust macht.
Inhaltliche Zerlegung
[[ ## reasoning ## ]]: Das Modell generiert hier die schrittweise Herleitung. Es identifiziert die Ausgangsposition, verfolgt die Bewegungen sequenziell und leitet daraus die finale Position ab. Dies ist die explizit gemachte „Gedankenkette“.
[[ ## antwort ## ]]: Basierend auf dem letzten Schritt im reasoning-Teil extrahiert das Modell die finale, knappe Antwort. Dies zeigt die Fähigkeit, von einer detaillierten Herleitung auf ein Endergebnis zu schließen.
Zusammenfassung und Bewertung
Die Analyse zeigt, dass DSPy „Programming, not Prompting“ wörtlich umsetzt. Anstatt manuell Prompts zu formulieren, definiert der Entwickler abstrakte Strukturen (Signaturen) und Verhaltensweisen (Module) in Python. DSPy kompiliert diese Abstraktionen in einen hochgradig strukturierten und präzisen Prompt, der dem LLM kaum Interpretationsspielraum lässt.
Die Schlüsselprinzipien, die dieser Prompt verdeutlicht, sind:
Explizite Strukturierung
Die Verwendung von klaren Trennzeichen ([[ ## ... ## ]]) erzwingt einen vorhersagbaren Output und macht die LLM-Interaktion robust.
Programmgesteuerte Logik
Das dspy.ChainOfThought-Modul fügt systematisch das reasoning-Feld und die entsprechenden Anweisungen hinzu, um eine bestimmte Problemlösungsstrategie zu implementieren.
Transparenz
Der generierte Prompt macht exakt nachvollziehbar, wie DSPy intern arbeitet und welche Anweisungen das LLM tatsächlich erhält.
Zusammenfassung und Bewertung
Das Modul dspy.ChainOfThought ist ein Werkzeug zur Steigerung der Lösungsqualität bei komplexen Aufgaben. Es implementiert das Chain-of-Thought-Prompting, indem es das Sprachmodell anleitet, eine explizite, schrittweise Begründung vor der finalen Antwort zu formulieren. Dadurch wird eine erhöhte Genauigkeit und eine verbesserte Interpretierbarkeit erreicht. So stellt dspy.ChainOfThought eine robuste Methode dar, um die Zuverlässigkeit und Nachvollziehbarkeit von LLM-basierten Anwendungen zu erhöhen.
Nachtrag: Verwendung eines Thinking Modells
Ich habe dspy.ChainOfThought heute mit einem Instruct Modell durchgeführt und frage mich, was passiert, wenn ich stattdessen ein Thinking Modell verwende. Ich lade also das TODO Modell herunter und führe das day5.ipynb noch mal mit dem geänderten Modell aus. Die Prediction sieht jetzt etwas anders aus.
Prediction(
reasoning='Arthur beginnt im Wohnzimmer. Er geht dann in die Küche (wo Berta ist) und anschließend ins Schlafzimmer. Die letzte genannte Bewegung ist der Übergang ins Schlafzimmer, daher ist Arthur dort am Ende.',
antwort='Schlafzimmer'
)
Aber das Reasoning ist nicht wesentlich länger geworden. Die Analyse des Prompts zeigt, dass auch hier nicht viel mehr „Thinking“ passiert ist.
System message:
Your input fields are:
1. `kontext` (str): Die zu lösende Logikfrage.
Your output fields are:
1. `reasoning` (str):
2. `antwort` (str): Die endgültige, knappe Antwort.
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## kontext ## ]]
{kontext}
[[ ## reasoning ## ]]
{reasoning}
[[ ## antwort ## ]]
{antwort}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Beantwortet eine Frage, die logisches Schlussfolgern erfordert.
User message:
[[ ## kontext ## ]]
Arthur ist im Wohnzimmer. Er geht in die Küche, wo auch Berta ist. Dann geht Arthur ins Schlafzimmer. Wo ist Arthur am Ende?
Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## antwort ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`.
Response:
[[ ## reasoning ## ]]
Arthur beginnt im Wohnzimmer. Er geht dann in die Küche (wo Berta ist) und anschließend ins Schlafzimmer. Die letzte genannte Bewegung ist der Übergang ins Schlafzimmer, daher ist Arthur dort am Ende.
[[ ## antwort ## ]]
Schlafzimmer
[[ ## completed ## ]]
Alles in allem scheint DSPy keinen offenen, interpretierbaren Prompt, sondern eine rigide, template-basierte Anweisung zu erzeugen, die unabhängig von Modell eine Struktur vorgibt, an die sich das Modell hält. DSPy abstrahiert die Notwendigkeit des manuellen „Prompt Engineering“ so weit, dass es sogar die unterschiedlichen, angeborenen Tendenzen von spezialisierten LLM-Varianten durch eine klare, programmatische Struktur vereinheitlichen kann. Für die gestellte, einfache Aufgabe ist die von DSPy vorgegebene „Leitplanke“ so dominant, dass beide Modelle auf einem ähnlichen Weg, korrekten Weg zum Ziel geführt werden.
Exkurs Modell-Typen
Basis-Modell (Base Model)
Das Basis-Modell ist das rohe, vortrainierte Modell, das riesige Mengen an Textdaten (Code, Bücher, Webseiten, Dokumente usw.) verarbeitet hat, um die statistische Struktur von Sprache zu lernen.
- Kein Verständnis von Anweisungen
Wenn du es fragst „Erkläre mir den Unterschied zwischen …“, liefert es oft unstrukturierten oder zufälligen Text. - Stärken
Sprachverständnis, Wissensbasis, stilistische Vielfalt. - Schwächen
Kein klarer Gesprächsstil, kein Gehorsam gegenüber Prompts, mögliche „halluzinatorische“ oder unpassende Antworten.
Instruct-Modell (Instruction-Tuned Model)
Das Instruct-Modell wurde weitertrainiert (Fine-Tuning) darauf, menschliche Anweisungen korrekt und hilfreich zu befolgen.
- Antwortet zielgerichtet, höflich und erklärend.
- Hat gelernt, die Intention des Nutzers zu verstehen.
- Kann Aufgaben ausführen, zusammenfassen, erklären, strukturieren, usw.
- Lässt sich besser steuern über Systemprompts.
Schwächen
- Weniger „roh“ kreativ (da auf Konformität getrimmt).
- Manche Modelle verlieren etwas an „explorativer“ Denkfähigkeit im Vergleich zu ihrem Basis-Modell.
Thinking Model (z. B. CoT-, Reasoning-, oder Reflection-Modelle)
Thinking-Modelle sind eine neue Generation, die Explizites Denken / Reasoning imitiert.
- Kann komplexe Probleme in Teilschritte zerlegen.
- Arbeitet logisch, analytisch und iterativ.
- Hat oft ein internes „Gedankenfeld“ (z. B.
reasoning_trace), das vom System oder Nutzer eingesehen werden kann. - Zeigt deutlich bessere Ergebnisse in Mathematik, Logik, Coding, Planung und Multi-Hop-Reasoning.
- Mit verzögertem Output, wo es zuerst denkt, dann spricht.
Schwächen
- Langsamer.
- Höherer Rechenaufwand.
- Manchmal zu „überanalytisch“ oder neigt zu Overthinking.
Zusammenfassung
| Typ | Training | Stärke | Schwäche | Einsatz |
|---|---|---|---|---|
| Base Model | Nur Self-Supervised (Textvorhersage) | Sprachkompetenz, Wissen | Kein Promptverständnis | Fine-Tuning, Forschung |
| Instruct Model | Fine-Tuning mit Prompts/Responses + RLHF | Befolgt Anweisungen, benutzerfreundlich | Weniger explorativ | Chatbots, Assistenten |
| Thinking Model | Instruct + CoT + Reasoning Training | Analytisch, logisch, bessere Qualität | Langsamer, komplexer | Wissenschaft, Coding, Agenten |
Das zugehörige Jupyter Notebook kann man unter https://github.com/msoftware/DSPy finden.