
TODO für Tag 20
- Prinzipielle Einführung in PCA
- Anwendung von PCA auf Datensätze
Prinzipielle Einführung in PCA
Die Hauptkomponentenanalyse, als PCA abgekürzt, ist eine Technik zur Dimensionalitätsreduktion. Ihr Hauptziel besteht darin, die Anzahl der Dimensionen eines Datensatzes zu verringern, während gleichzeitig so viel wie möglich von der ursprünglichen Varianz, also der Information, in den Daten erhalten bleibt. Dies ist besonders nützlich bei hochdimensionalen Datensätzen, wo viele Merkmale redundant sein können.
Die grundlegende Idee hinter PCA ist es, einen neuen Satz von Features zu finden, die sogenannten Hauptkomponenten. Diese Hauptkomponenten sind Kombinationen der ursprünglichen Merkmale. Die erste Hauptkomponente ist die Richtung im Merkmalsraum, entlang derer die Daten die größte Varianz aufweisen. Jede nachfolgende Hauptkomponente wird so gewählt, dass sie die nächstgrößte verbleibende Varianz erklärt, unter der Bedingung, dass sie unkorreliert zu allen vorhergehenden Hauptkomponenten ist. Dieser Prozess der sukzessiven Maximierung der Varianz bei gleichzeitiger Gewährleistung der Orthogonalität führt zu einem neuen Koordinatensystem, das die Struktur der Daten oft effizienter darstellt.
In scikit-learn wird PCA durch die Klasse sklearn.decomposition.PCA bereitgestellt. Um PCA anzuwenden, instanziiert man typischerweise ein PCA-Objekt und gibt dabei einen wichtigen Parameter an: n_components. Dieser Parameter bestimmt die Anzahl der Hauptkomponenten, auf die die Daten reduziert werden sollen. n_components kann eine ganze Zahl sein, die die exakte Anzahl der gewünschten Dimensionen angibt. Alternativ kann es ein Fließkommawert zwischen 0 und 1 sein, der den Anteil der kumulativen erklärten Varianz angibt, der durch die ausgewählten Komponenten erhalten bleiben soll. Scikit-learn wählt dann automatisch die kleinste Anzahl von Komponenten, die diesen Schwellenwert erreichen.
Nach der Initialisierung des PCA-Objekts wird die fit()-Methode auf die Trainingsdaten angewendet. Während dieses Schritts lernt das Modell die Hauptkomponenten aus den Daten. Das bedeutet, es berechnet die Mittelwerte der ursprünglichen Merkmale und bestimmt dann die Richtungen, die die Hauptkomponenten definieren, sowie die Menge an Varianz, die jede Komponente erklärt.
Sobald das Modell trainiert wurde, kann die transform()-Methode verwendet werden, um die ursprünglichen Daten in den neuen, niedrigdimensionalen Raum der Hauptkomponenten zu projizieren. Das Ergebnis ist ein neuer Datensatz mit der durch n_components spezifizierten Anzahl von Merkmalen. Diese transformierten Features sind die Werte der ursprünglichen Datenpunkte entlang der Achsen der Hauptkomponenten. Man kann auch die Methode fit_transform() verwendet, die das Lernen der Komponenten und die Transformation der Daten, in einem einzigen Aufruf kombiniert.
Ein wichtiger Aspekt bei der Verwendung von PCA ist die Interpretation der Ergebnisse. Das Attribut explained_variance_ratio_ des PCA-Objekts gibt den prozentualen Anteil der Varianz an, der von jeder der ausgewählten Komponenten erklärt wird. Dies hilft bei der Entscheidung, wie viele Komponenten beibehalten werden sollen, um einen guten Kompromiss zwischen Dimensionsreduktion und Informationserhalt zu finden. Die Hauptkomponenten selbst sind im Attribut components_ gespeichert. Diese zeigen, wie die ursprünglichen Features zu den neuen Hauptkomponenten beitragen.
PCA ist eine lineare Transformation, was bedeutet, dass sie am besten funktioniert, wenn die zugrundeliegenden Beziehungen in den Daten linear sind. Es ist auch wichtig zu beachten, dass PCA empfindlich gegenüber der Skalierung der ursprünglichen Merkmale ist. Merkmale mit größeren Wertebereichen können die Hauptkomponenten überproportional beeinflussen. Daher ist es üblich, die Daten vor der Anwendung von PCA mit dem StandardScaler zu standardisieren. So kann man sicherzustellen, dass alle Merkmale einen Mittelwert von Null und eine Standardabweichung von Eins haben.
Anwendung von PCA auf Datensätze
Das Folgende Beispiel zeigt, wie PCA in scikit-learn verwendet wird, um einen hochdimensionalen Datensatz mit redundanten Merkmalen zu reduzieren.
Dazu wird eine synthetischen Datensatz mit make_classification erzeugt. Dieser Datensatz besitzt Features, von denen einige tatsächlich nützliche Informationen für eine Klassifikationsaufgabe enthalten, während andere redundant sind und wieder andere einfach nur Rauschen darstellen oder Wiederholungen anderer Merkmale sind. Der Datensatz ist so konstruiert, dass er 500 Datenpunkte mit jeweils 50 Merkmalen enthält. Von diesen 50 Merkmalen sind bewusst nur 10 für die Klassifizierung wirklich informativ, während 20 als lineare Kombinationen davon redundant sind, 5 exakte Wiederholungen darstellen und die restlichen 15 zufälliges Rauschen sind. Ziel ist es, einen realistischen Datensatz mit überflüssigen und korrelierten Merkmalen zu simulieren, der von PCA effektiv reduziert werden kann, und der zwei Zielklassen besitzt.
Im zweiten Schritt erfolgt die Skalierung der Daten. Da PCA empfindlich auf die unterschiedlichen Skalen der einzelnen Merkmale reagiert, ist dieser Vorverarbeitungsschritt unerlässlich. Mit Hilfe des StandardScalers wird jedes Merkmal unabhängig voneinander transformiert. Nach dieser Transformation hat jedes Merkmal einen Mittelwert von 0 und eine Standardabweichung von 1. So wird sicherstellt, dass alle Merkmale gleichgewichtig in die PCA-Analyse eingehen.
Der dritte Schritt wendet die eigentliche Hauptkomponentenanalyse (PCA) auf die skalierten Daten an. Dabei wird nicht eine feste Anzahl von Zielkomponenten vorgegeben, sondern festgelegt, welcher Prozentsatz der ursprünglichen Varianz in den Daten durch die transformierten Hauptkomponenten beibehalten werden soll. Im vorliegenden Fall wird PCA so konfiguriert, dass 95% der Gesamtvarianz der Daten in den resultierenden Hauptkomponenten erhalten bleiben. PCA berechnet dann die notwendige Anzahl von Komponenten, die benötigt werden, um dieses Kriterium zu erfüllen, und projiziert die hochdimensionalen, skalierten Daten auf diesen niedriger-dimensionalen Unterraum.
Der vierte und letzte Schritt dient der Visualisierung und der Analyse des PCA-Prozesses.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import pandas as pd # Für eine schönere Darstellung der Daten
# Erstellung eines hochdimensionalen Datensatzes mit redundanten Merkmalen.
# 500 Samples, 50 Merkmale, 10 dieser Merkmale sind wirklich informativ,
# 20 Merkmale sind lineare Kombinationen der informativen Merkmale,
# 5 Merkmale sind exakte Duplikate von informativen oder redundanten Merkmalen.
# Die restlichen 50 - 10 - 20 - 5 = 15 Merkmale sind zufälliges Rauschen.
X, y = make_classification(
n_samples=500,
n_features=50,
n_informative=10,
n_redundant=20,
n_repeated=5,
n_classes=2, # 2 Zielklassen.
random_state=42
)
# PCA ist empfindlich gegenüber der Skalierung der Merkmale. Daher
# werden die Daten mit dem StandardScaler vorverarbeitet, sodass jedes
# Merkmal einen Mittelwert von 0 und eine Standardabweichung von 1 hat.
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Anwendung von PCA
# Es gibt zwei gängige Wege, die Anzahl der Komponenten für PCA zu bestimmen:
# a) Eine feste Anzahl von Komponenten wählen (z.B. 2 oder 3 für Visualisierung).
# b) Den Prozentsatz der erklärten Varianz angeben, den man beibehalten möchte (z.B. 95%).
# Variante b) ist oft vorzuziehen, da sie datengesteuert ist.
# Komponenten behalten, so dass 95% der Varianz in den Daten erklärt werden.
pca_95_variance = PCA(n_components=0.95)
X_pca_95 = pca_95_variance.fit_transform(X_scaled)
# Plot, um die erklärte Varianz pro Komponente zu zeigen.
pca_full = PCA()
pca_full.fit(X_scaled)
plt.figure(figsize=(10, 6))
plt.plot(np.cumsum(pca_full.explained_variance_ratio_), marker='o', linestyle='--')
plt.xlabel("Anzahl der Komponenten")
plt.ylabel("Kumulative erklärte Varianz")
plt.title("Kumulative erklärte Varianz durch Hauptkomponenten")
plt.axhline(y=0.95, color='r', linestyle='-', label="95% erklärte Varianz")
plt.axvline(x=pca_95_variance.n_components_, color='g', linestyle=':', label=f"{pca_95_variance.n_components_} Komponenten für 95% Varianz")
plt.legend(loc='best')
plt.grid(True)
plt.show()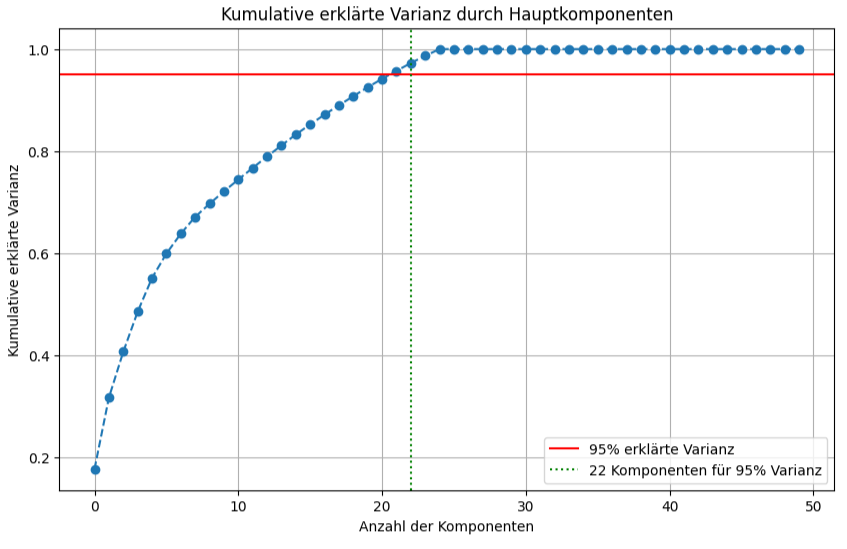
Das Diagramm ist ein sogenannter Scree Plot, der ein wichtiges Ergebnis der Hauptkomponentenanalyse visualisiert. Auf der horizontalen Achse ist die Anzahl der berücksichtigten Hauptkomponenten aufgetragen (0-50 entspricht der ursprünglichen Anzahl der Merkmale im Datensatz). Die vertikale Achse zeigt die Kumulative erklärte Varianz, die von 0.0 (keine Varianz erklärt) bis 1.0 (gesamte Varianz erklärt) reicht.
Die blaue, gestrichelte Linie zeigt, wie sich der Anteil der erklärten Varianz kumulativ erhöht, wenn man sukzessive mehr Hauptkomponenten hinzunimmt. Am Anfang, bei wenigen Komponenten, steigt die Kurve sehr steil an. Dies bedeutet, dass die ersten Hauptkomponenten bereits einen sehr großen Teil der Gesamtvarianz des Datensatzes abdecken. Je weiter man sich auf der X-Achse nach rechts bewegt, also mehr Komponenten einbezieht, desto flacher wird der Anstieg der blauen Kurve. Das illustriert, dass jede zusätzliche Hauptkomponente einen immer geringeren zusätzlichen Beitrag zur Erklärung der Gesamtvarianz leistet.
Zwei Hilfslinien sind im Diagramm eingezeichnet. Die rote, durchgehende horizontale Linie befindet sich auf der Höhe von 0.95 der kumulativen erklärten Varianz. Dieser Wert ist der Schwellenwert, der verwendet wird, um zu entscheiden wie viele Komponenten beibehalten werden sollen um einen Großteil der Information des ursprünglichen Datensatzes zu erhalten. Die grüne, gestrichelte vertikale Linie (22 Komponenten für 95% Varianz) schneidet die X-Achse bei dem Wert 22. Sie markiert den Punkt, an dem die blaue Kurve der kumulativen erklärten Varianz die rote 95%-Schwelle erreicht oder erstmalig überschreitet.
Zusammenfassend zeigt das Diagramm also, dass in diesem spezifischen Fall 22 Hauptkomponenten ausreichen, um 95% der gesamten Varianz des ursprünglichen Datensatzes zu erklären. Dies ist eine signifikante Dimensionsreduktion von 50 auf 22 Features, wobei der Informationsverlust, gemessen an der Varianz, auf 5% begrenzt wird. Der Plot ist ein einfaches Werkzeug, um einen Kompromiss zwischen der Reduktion der Komplexität und dem Erhalt der relevanten Informationen im Datensatz zu finden.