
TODO für Tag 6
- Unterschied zwischen Train/Test Split und Cross-Validation
- cross_val_score verwenden
Unterschied zwischen Train/Test Split und Cross-Validation und cross_val_score verwenden
Beim Train/Test Split wird der vorhandene Datensatz einmalig in zwei getrennte Teile aufgeteilt – einen Teil zum Trainieren des Modells und einen anderen zum Testen, ob das Modell etwas gelernt hat. Den scikit-learn Code zum splitten der Daten habe ich in den letzten 5 Tagen ja schon diverse male verwendet und beschrieben.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Das Modell sieht die Testdaten beim Training nicht und wird danach auf diesen unbekannten Daten bewertet. Der Nachteil dabei ist, dass die Leistung des Modells stark davon abhängen kann, wie genau diese eine Aufteilung zufällig gewählt wurde – manchmal hat man Glück, manchmal Pech, und das Ergebnis kann täuschen.
Cross-Validation löst dieses Problem, indem der Datensatz in mehrere gleich große Abschnitte aufgeteilt wird, sogenannte Folds. Das Modell wird dann mehrmals trainiert, wobei in jedem Durchlauf ein anderer Abschnitt zum Testen genutzt wird und die restlichen Abschnitte zum Trainieren dienen. So wird jedes Stück der Daten einmal als Testdaten verwendet und das Modell bekommt eine viel gründlichere Prüfung. Cross-Validation liefert dadurch ein stabileres und aussagekräftigeres Ergebnis als ein einzelner Split, ist aber auch aufwändiger, weil das Training mehrfach wiederholt werden muss. Glücklicherweise hat scikit-learn eine eingebaute Funktion, die es dem Entwickler ermöglicht, Cross-Validation in einer einzelnen Zeile Code zu erledigen.
Beispiel:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
# Beispiel-Daten laden (Iris-Datensatz)
X, y = load_iris(return_X_y=True)
# Modell definieren
model = RandomForestClassifier(random_state=42)
# Cross-Validation durchführen (5-Fold)
scores = cross_val_score(model, X, y, cv=5)
# Ergebnisse anzeigen
print(f"Cross-Validation Scores: {scores}")
print(f"Durchschnittlicher Score: {scores.mean():.4f}")Was passiert hier?
load_iris()lädt einen typischen kleinen Beispieldatensatz.RandomForestClassifierist das Modell.cross_val_scoreübernimmt alles: automatisch aufteilen, mehrfach trainieren, mehrfach testen. Der Wertcv=5bedeutet 5-Fold Cross-Validation: Der Datensatz wird in 5 Teile aufgeteilt.- Am Ende erhält man 5 Scores, einen pro Fold, und den Durchschnitt.
Cross-Validation Scores: [0.96666667 0.96666667 0.93333333 0.96666667 1. ] Durchschnittlicher Score: 0.9667
Mit dem folgenden Python Skript kann man die Cross-Validation Scores dann auch grafisch darstellen.
plt.figure(figsize=(8, 4))
plt.plot(range(1, 6), scores, marker='o', linestyle='-')
plt.title('Cross-Validation Scores pro Fold')
plt.xlabel('Fold')
plt.ylabel('Score')
plt.ylim(0.0, 1.05)
plt.grid(True)
plt.show()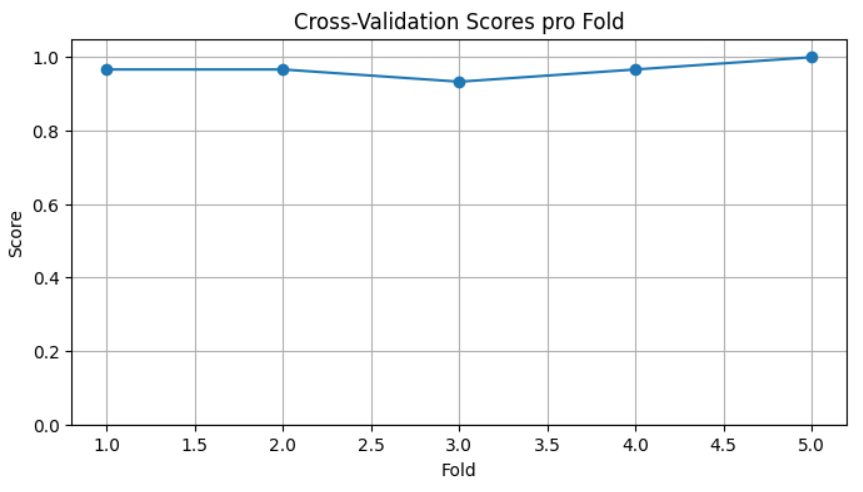
Der wichtigste Unterschied ist also, dass beim Train/Test Split eine zufälligen Aufteilung gewählt wird, während beim Cross-Validation viele Bewertungen für verschiedenen Aufteilungen kombiniert werden, was verlässlichere Aussagen über die Modellqualität ermöglicht.
Alles in allem eine gute Möglichkeit, etwas mehr Details über die Qualität des Modells zu erfahren.