
TODO für Tag 21
- Einfaches Bag-of-Words Modell mit CountVectorizer
- Klassifikation von Textdaten testen
Einfaches Bag-of-Words Modell mit CountVectorizer
Ein Bag-of-Words Modell stellt eine Methode dar, um Text in ein numerisches Format umzuwandeln, das von Computeralgorithmen verarbeitet werden kann. Bei diesem Modell wird ein Textdokument als eine ungeordnete Sammlung seiner Wörter betrachtet, wobei die Grammatik und die Reihenfolge der Wörter vollständig ignoriert werden. Der Fokus liegt einzig auf der Häufigkeit, mit der jedes Wort im Dokument vorkommt.
In scikit-learn implementiert der CountVectorizer dieses Bag-of-Words Konzept auf eine einfache und effiziente Weise. Seine Hauptaufgabe ist es, eine Sammlung von Textdokumenten, zu nehmen und daraus eine Matrix von Wort-Zählungen zu erstellen. Zunächst analysiert der CountVectorizer den gesamten Korpus, um ein Vokabular aller einzigartigen Wörter zu erstellen, die im Text vorkommen. Dieses Vokabular bildet die Grundlage für die spätere numerische Darstellung. Nachdem das Vokabular aufgebaut ist, transformiert er jedes einzelne Dokument im Korpus. Für jedes Dokument erstellt er einen Vektor, dessen Länge der Größe des erstellten Vokabulars entspricht. Jeder Eintrag in diesem Vektor repräsentiert ein bestimmtes Wort aus dem Vokabular, und der Wert des Eintrags gibt an, wie oft dieses Wort im jeweiligen Dokument gezählt wurde.
Das Endergebnis des CountVectorizer ist eine Liste von Sparse-Vektoren die dem ursprünglichen Dokument entsprechen. Jede Spalte der Matrix ist einem Wort aus dem globalen Vokabular zugeordnet, und die Einträge in der Matrix sind die Häufigkeiten der Wörter. Dieses Vorgehen wandelt rohen Text effektiv in eine Form um, die für maschinelle Lernaufgaben wie Klassifizierung oder Clustering verwendet werden kann, wobei die Bedeutung von Wörtern durch ihre Häufigkeit und ihr Vorkommen im Korpus erfasst wird, unabhängig von ihrer Position oder grammatischen Beziehung zu anderen Wörtern.
Beispiel:
from sklearn.feature_extraction.text import CountVectorizer
import matplotlib.pyplot as plt
import numpy as np
# Definition des Beispiel-Korpus
corpus = [
"Dies ist der erste Satz für das Beispiel.",
"Der zweite Satz ist ein weiterer Satz für dieses Beispiel.",
"Ein dritter Satz, der auch zum Beispiel gehört.",
"Das Beispiel zeigt die Funktionsweise des CountVectorizer."
]
# Initialisierung des CountVectorizer
# Standardmäßig wandelt er den Text in Kleinbuchstaben um und entfernt Satzzeichen
vectorizer = CountVectorizer()
# Anwenden des Vectorizers auf den Korpus. fit_transform lernt das Vokabular aus dem Korpus (fit) und erstellt dann die Dokument-Term-Matrix (transform)
X = vectorizer.fit_transform(corpus)
# Abrufen des gelernten Vokabulars (der Feature-Namen)
words = vectorizer.get_feature_names_out()
# X ist eine sparse Matrix, die die Wortzählungen enthält.
# Jede Zeile repräsentiert ein Dokument, jede Spalte ein Wort aus dem Vokabular.
# Für die Visualisierung wird die Gesamthäufigkeit jedes Wortes ermittelt
total_counts = np.sum(X, axis=0)
# Paare von Wort und Gesamtzählung erstellen
word_count_pairs = list(zip(words, np.asarray(total_counts).flatten()))
# Sortieren nach der Häufigkeit
word_count_pairs_sorted = sorted(word_count_pairs, key=lambda item: item[1], reverse=True)
# Extrahieren der sortierten Wörter und Zählungen für die Visualisierung
sorted_words, sorted_counts = zip(*word_count_pairs_sorted)
# Erstellen einer Visualisierung der Gesamtworthäufigkeiten
plt.figure(figsize=(12, 7)) # Setzen der Größe des Plots
plt.bar(sorted_words, sorted_counts, color='skyblue') # Erstellen eines Balkendiagramms
plt.xlabel("Wort") # Beschriftung der X-Achse
plt.ylabel("Gesamthäufigkeit im Korpus") # Beschriftung der Y-Achse
plt.title("Gesamtworthäufigkeiten im Korpus (Bag-of-Words Darstellung)") # Titel des Plots
plt.xticks(rotation=45, ha='right') # Drehen der X-Achsen-Beschriftungen für bessere Lesbarkeit
plt.tight_layout() # Anpassen des Layouts
plt.show() # Anzeigen des PlotsAusgabe:
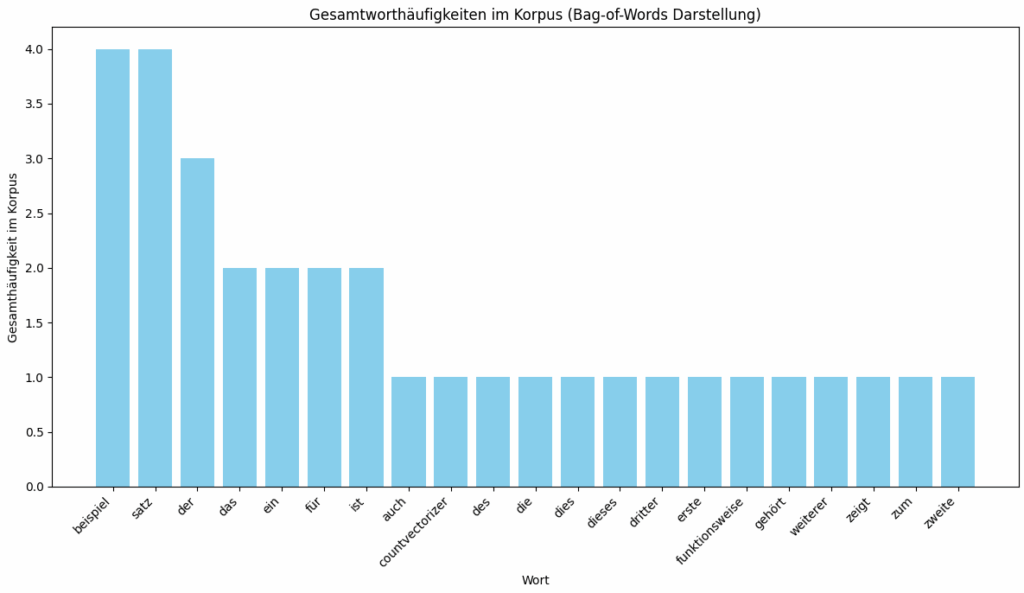
Das erzeugte Bild zeigt die Gesamthäufigkeiten der einzelnen Wörter im zuvor definierten Textkorpus, basierend auf der Ausgabe des Bag-of-Words Modells mittels CountVectorizer.
Auf der horizontalen X-Achse sind die einzelnen, einzigartigen Wörter aufgeführt, die vom CountVectorizer im Korpus identifiziert wurden und das Vokabular des Modells bilden. Auf der vertikalen Y-Achse zeigt die Anzahl, wie oft jedes spezifische Wort über alle Dokumente des Korpus hinweg gezählt wurde.
Jeder Balken im Diagramm repräsentiert ein Wort aus dem Vokabular, und die Höhe des Balkens entspricht der Gesamtzählung dieses Wortes im gesamten Korpus. Das Diagramm ist so sortiert, dass die Wörter mit der höchsten Gesamthäufigkeit links und die Wörter mit geringerer Häufigkeit weiter rechts angezeigt werden.
Klassifikation von Textdaten testen
Das folgende Beispiel verwendet einen Kaggle Datensatz zur Textklassifikation und implementiert mit scikit-learns CountVectorizer und einem Naive-Bayes-Klassifikator.
Wir verwenden hier das „SMS Spam Collection Dataset“ von Kaggle, der aus Nachrichten und ihrer Klassifizierung als „spam“ oder „ham“ (nicht-spam) besteht. Dieser Datensatz ist relativ klein und eignet sich gut für ein Beispiel.
Für das Beispiel muss die pandas-Bibliothek installiert sein und die span.csv Datei aus dem „SMS Spam Collection Dataset“ im aktuellen Ordner gespeichert werden.
Der erste Schritt ist das Umwandeln der Labels von Zeichenketten (‚ham‘, ’spam‘) in numerische Werte, da maschinelle Lernmodelle Zahlen verarbeiten. ‚ham‘ wird der Kategorie 0 und ’spam‘ der Kategorie 1 zugeordnet. Dann wird der Datensatz in Trainings- und Testteile aufgeteilt. Der Trainingsdatensatz wird verwendet, um das Modell zu trainieren, während der Testdatensatz dazu dient, die Leistung des Modells auf neuen, ungesehenen Daten zu bewerten.
Dann wird eine Pipeline (Siehe Tag 13) erstellt. Diese Pipeline bündelt die Schritte der Textverarbeitung und der Modellierung. Der erste Schritt ist der CountVectorizer, der den Text in eine numerische Darstellung (Bag-of-Words Matrix) umwandelt. Der zweite Schritt ist der Klassifikator. Es wird der MultinomialNB verwendet, der für Zähldaten wie Worthäufigkeiten gut geeignet ist.
Das Training der Pipeline, wird mit der fit-Methode auf die Trainingsdaten durchgeführt. Während dieses Trainingsprozesses lernt der CountVectorizer das Vokabular aus den Trainings texten und wandelt sie in Vektoren um. Anschließend verwendet der MultinomialNB diese Vektoren und die Trainings-Labels, um zu lernen, wie Texte basierend auf ihren Wortinhalten den Kategorien 0 oder 1 zugeordnet werden können.
Nach dem Training wird die Pipeline verwendet, um Vorhersagen für die Texte im Testdatensatz zu treffen. Die predict-Methode wendet zuerst die Vektorisierung auf die Test texte an und verwendet dann das trainierte Modell, um eine Vorhersage für jede Test-Nachricht zu treffen.
Zur Bewertung der Modellleistung wird die Genauigkeit (accuracy_score) ermittelt, die den Anteil der korrekt klassifizierten Testnachrichten misst. Zum Schluss wird alles in eine Confusion-Matrix dargestellt.
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
import numpy as np
# Datensatz laden ohne die erste Zeile
file_path = 'spam.csv'
df = pd.read_csv(file_path, encoding='latin-1', names=['label', 'text'], usecols=[0, 1], skiprows=[0])
# Labels von Text in Zahlen umwandeln
# 'ham' wird 0, 'spam' wird 1
df['label'] = df['label'].map({'ham': 0, 'spam': 1})
# Extrahieren der Features (Texte) und der Zielvariablen (Labels)
texte = df['text']
labels = df['label']
# Aufteilen in Trainings- und Testdatensatz (80% Training, 20% Test)
texte_train, texte_test, labels_train, labels_test = train_test_split(
texte, labels, test_size=0.2, random_state=42, stratify=labels)
# Pipeline erstellen und trainieren
# - Vektorisierung: CountVectorizer erstellt die Bag-of-Words Darstellung
# - Klassifikator: MultinomialNB klassifiziert die Texte
model_pipeline = Pipeline([
('vectorizer', CountVectorizer()),
('classifier', MultinomialNB())
])
# Trainieren des Modells auf den Trainingsdaten
print("Trainiere Modell...")
model_pipeline.fit(texte_train, labels_train)
print("Training abgeschlossen.")
# Vorhersagen treffen
# Vorhersagen auf dem Testdatensatz machen
print("Treffe Vorhersagen auf Testdaten...")
vorhersagen = model_pipeline.predict(texte_test)
print("Vorhersagen abgeschlossen.")
# Berechnung der Genauigkeit
genauigkeit = accuracy_score(labels_test, vorhersagen)
print(f"\nDie Genauigkeit des Modells auf dem Testdatensatz beträgt: {genauigkeit:.4f}")
# Ergebnisse visualisieren (Confusion-Matrix)
# Berechnung der Konfusionsmatrix
cm = confusion_matrix(labels_test, vorhersagen, labels=model_pipeline.classes_)
# Anzeigen
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['ham', 'spam'])
fig, ax = plt.subplots(figsize=(8, 6)) # Setzen der Größe des Plots
disp.plot(cmap=plt.cm.Blues, ax=ax) # Plotten der Matrix, Farbkarte 'Blues'
plt.title("Konfusionsmatrix der SMS Klassifikation") # Titel des Plots
plt.xlabel("Vorhergesagtes Label") # Beschriftung der X-Achse
plt.ylabel("Wahres Label") # Beschriftung der Y-Achse
plt.grid(False) # Gitternetzlinien entfernen
plt.show() # Anzeigen des PlotsDieses Beispiel zeigt, wie ein Textklassifikationsproblem angegangen werden kann, beginnend mit dem Laden und Vorbereiten von Daten, der Anwendung der Bag-of-Words Methode mit CountVectorizer innerhalb einer Pipeline, dem Training eines Klassifikators und der Bewertung der Ergebnisse.
Ausgabe:
Trainiere Modell...
Training abgeschlossen.
Treffe Vorhersagen auf Testdaten...
Vorhersagen abgeschlossen.
Die Genauigkeit des Modells auf dem Testdatensatz beträgt: 0.9839
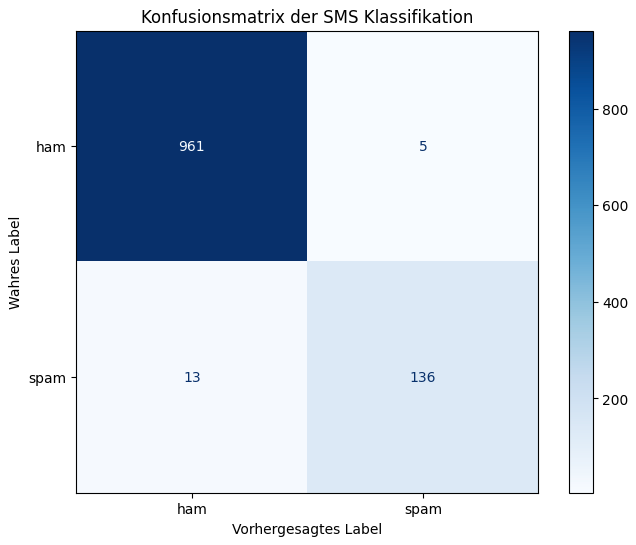
Das erzeugte Bild zeigt eine Konfusionsmatrix für eine Klassifikationsaufgabe. Die vertikale Achse, beschriftet mit repräsentiert die tatsächlichen Kategorien der Nachrichten im Testdatensatz. Die Zellen innerhalb der Matrix sind farblich kodiert, wobei dunklere Blautöne höhere Werte darstellen. Jeder Wert in einer Zelle gibt die Anzahl der Nachrichten an, für die das wahre Label und das vorhergesagte Label übereinstimmten oder nicht übereinstimmten.
Das Diagramm zeigt, dass das Modell eine hohe Anzahl Nachrichten korrekt identifiziert hat, bei einer relativ geringen Anzahl von Fehlklassifikationen sowohl bei der fälschlichen Markierung von „ham“ als „spam“ als auch umgekehrt.
