
Dieser Beitrag beschreibt den Aufbau einer grundlegenden RAG-Pipeline mit dem DSPy-Framework. Das System wird so konzipiert, dass es eine Nutzerfrage entgegennimmt, relevante Passagen aus einem Wikipedia-Datensatz abruft und auf Basis dieser Informationen eine fundierte Antwort generiert. Als Vektordatenbank wird Qdrant und für die Inferenz werden lokal betriebene Modelle eingesetzt.
Schritt-für-Schritt-Implementierung
Die Implementierung erfordert ein laufendes Setup für die lokalen Modelle (z. B. über einen llama.cpp-Server auf den Ports 8080 und 8081) sowie eine aktive Qdrant-Instanz (z. B. via Docker).
Die Docker Instanz kann wie unter https://qdrant.tech/documentation/guides/installation/ beschrieben installiert werden. Nach der Installation kann man in Docker Desktop sehen, dass der Qdrant Server läuft.
Ist der Docker Conainer gestartet, kann man im Browser http://localhost:6333/dashboard#/collections aufrufen und sollte das Qdrant Dashboard sehen.
Im meinem Fall sind schon 2 Collections vorhanden, aber die sind nicht weiter relevant für dieses Beispiel. Zusätzlich muss noch de Qdrant Client mit dem folgenden Befehl installiert werden.
pip install qdrant-client
Nach der Installation kann Jupyter Notebook gestartet werden.
Zunächst werden alle notwendigen Abhängigkeiten importiert und die Verbindungen zum lokalen LLM, zum Embedding-Modell und zu Qdrant konfiguriert.
import dspy
from datasets import load_dataset
# 1. Initialisierung der Modelle (lokal betrieben)
# Annahme: Ein Embedding-Modell-Server läuft auf Port 8081
embedder = dspy.Embedder(
"openai/embeddinggemma-300M-Q8_0.gguf",
api_base="http://localhost:8081/v1",
api_key="no_key_needed",
batch_size=100
)
# Annahme: Ein LLM-Server läuft auf Port 8080
local_llm = dspy.LM(
"openai/gemma-3-4b-it-Q4_K_M.gguf",
api_base="http://localhost:8080/v1",
api_key="no_key_needed",
temperature=0.1,
cache=False
)
dspy.configure(lm=local_llm, embedder=embedder)Schritt 2: Laden und Indexieren der Daten
Der simple-wiki-Datensatz von Hugging Face wird geladen. Anschließend werden die Texte in die Qdrant-Datenbank indexiert, wofür Vektor-Embeddings der Textpassagen erstellt werden.
# Laden des Datensatzes
dataset = load_dataset("embedding-data/simple-wiki", split="train[:1000]")
documents = [" ".join(doc['set']) for doc in dataset] Die Datensätze müssen ind kleinere Chunks aufgeteilt werden. Sehr kleine Chunks ignorieren, da sie keine relevanten Inhalte enthalten.
# Aus den Dokumenten Chunks erzeugen
chunk_size = 512
all_chunks = []
for doc in documents:
# Anzahl der Chunks für dieses Dokument
for i in range(0, len(doc), chunk_size):
chunk = doc[i:i+chunk_size]
if len(chunk) > 100: # nur Chunks > 100 Zeichen übernehmen
all_chunks.append(chunk)
print(len(all_chunks))
# print(all_chunks[:2]) # die ersten zwei Chunks anzeigenBevor man eine Qdrant Vektor-Datenbank nutzen kann muss man sie erst anlegen. Dabei wird der Name und die Embedding-Dimension angegeben.
# Erstellen der Qdrant Collection (nur falls sie nicht existiert)
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
# Qdrant Client erstellen
client = QdrantClient(host="localhost", port=6333)
collection_name = "simple_wiki_rag"
embedding_dim = 768 # Dimension für embedding-gemma-Modell
# Prüfen, ob die Collection existiert
if not client.collection_exists(collection_name):
client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(
size=embedding_dim,
distance=Distance.COSINE
)
)
print(f"Collection '{collection_name}' created successfully.")
else:
print(f"Collection '{collection_name}' already exists.")
Ist die Qdrant Vektor-Datenbank erstellt, kann man unter http://localhost:6333/dashboard#/collections prüfen, ob Colection korrekzt angelegt wurde.
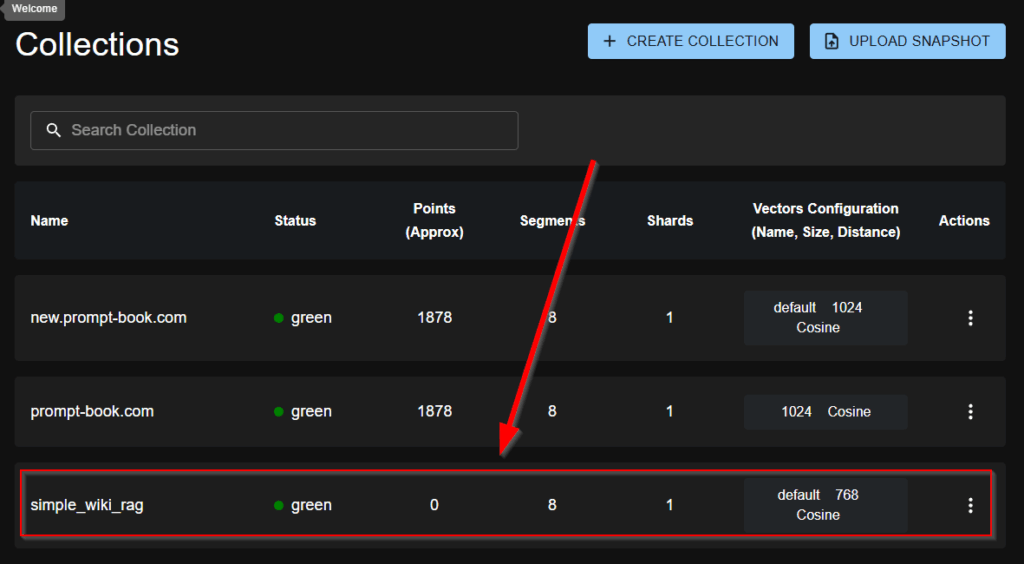
Wie man sieht, gibt es eine weitere Collection mit dem Name simple_wiki_rag. Als nächstes müssen die Chunks mit Hilfe des Embedding-Modells in Embedding-Vektoren umgewandelt werden. Diese können dann in Qdrant gespeichert werden.
# Embedden und Indexieren der Dokumente
embeddings = embedder(all_chunks)
from qdrant_client.models import PointStruct
points = [
PointStruct(id=i, vector=vec, payload={"text": chunk})
for i, (chunk, vec) in enumerate(zip(all_chunks, embeddings))
]
# Punkte in Qdrant hochladen (in Batches für große Daten)
batch_size = 100
for i in range(0, len(points), batch_size):
batch = points[i:i+batch_size]
client.upsert(
collection_name=collection_name,
points=batch
)
print(f"{len(points)} Chunks erfolgreich in Qdrant gespeichert.")Ist die Collection gefüllt, kann man das im Browser sehen, da in der Spalte Points (Approx) ein Wert > 0 steht. Als nächstes werden die DSPy-Komponenten definiert: ein Retriever für Qdrant, eine Signatur für die Generate-Aufgabe und das finale RAG-Modul.
# Definition des Qdrant Retrievers
class QdrantRetriever(dspy.Retrieve):
def __init__(self, client, collection_name, embedder, k=3):
self._client = client
self._collection_name = collection_name
self._embedder = embedder
self._k = k
super().__init__()
def forward(self, query_or_queries, k=None):
k = k if k is not None else self._k
# Embedden der Suchanfrage
query_embeddings = self._embedder(query_or_queries)
# Suche in Qdrant
results = [
self._client.query_points(
collection_name=collection_name,
query=query_embeddings,
limit=3,
) for emb in query_embeddings
]
# Extrahieren des Textes aus den Suchergebnissen - TODO not only results[0]
passages = [p.payload["text"] for p in results[0].points]
return passages
# Definition der Signatur für den Generator
class GenerateAnswer(dspy.Signature):
"""Beantworte die Frage basierend auf dem bereitgestellten Kontext."""
context = dspy.InputField(desc="Relevante Fakten zur Beantwortung der Frage.")
question = dspy.InputField(desc="Die ursprüngliche Nutzerfrage.")
answer = dspy.OutputField(desc="Eine prägnante und faktenbasierte Antwort.")
# Aufbau des RAG-Moduls
class RAG(dspy.Module):
def __init__(self):
super().__init__()
self.retriever = QdrantRetriever(client, collection_name, embedder)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retriever(question)
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)Die RAG-Pipeline wird instanziiert und mit einer Testfrage ausgeführt. In dem Fall mit der Frage ‚What is the largest continent?‘.
# Instanziieren und Ausführen des RAG-Programms. Zu der Frage gibt es kein passenden Eintrag im Vector Store
rag_pipeline = RAG()
question = "What is the largest continent?"
prediction = rag_pipeline(question)
# Anzeigen der Ergebnisse
print(f"Frage: {question}")
print(f"Antwort: {prediction.answer}")Zu dieser Frage gib es in dem embedding-data/simple-wiki Datensatz aber keine Informationen. Daher antwortet das Modell mit „The context does not provide information about the largest continent.“. Das liegt daran, dass mit der Anweisung „Beantworte die Frage basierend auf dem bereitgestellten Kontext.“ das Modell angewiesen wurde nur auf Basis des bereitgestellten Kontextes zu antworten. Da der Kontext die Informationen nicht hergibt, antwortet das Modell nicht, obwohl die Informationen in den Parametern des Modells gespeichert sind.
# Inspizieren des finalen Prompts, der an das LLM gesendet wurde
local_llm.inspect_history(n=1)Die Ausgabe von inspect_history zeigt den Prompt:
System message:
Your input fields are:
1. `context` (str): Relevante Fakten zur Beantwortung der Frage.
2. `question` (str): Die ursprüngliche Nutzerfrage.
Your output fields are:
1. `reasoning` (str):
2. `answer` (str): Eine prägnante und faktenbasierte Antwort.
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## context ## ]]
{context}
[[ ## question ## ]]
{question}
[[ ## reasoning ## ]]
{reasoning}
[[ ## answer ## ]]
{answer}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Beantworte die Frage basierend auf dem bereitgestellten Kontext.
User message:
[[ ## context ## ]]
[1] «When people write about these countries , they usually write BRICs or the BRIC countries '' ' . It is typically rendered as `` the BRICs '' or `` the BRIC countries '' or alternatively as the `` Big Four '' .»
[2] «Praia a port that transports coffee , sugar cane , and tropical fruits . Praia is Cape Verde 's largest city , a commercial center , and a port that ships coffee , sugar cane , and tropical fruits .»
[3] «They occur only in the New World . They occur throughout the New World from extreme southern Canada to Chile .»
[[ ## question ## ]]
What is the largest continent?
Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## answer ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`.Wie man sieht, konnte kein passender Kontext aus dem Vektor-Store geladen werden.
Eine zweite Anfrage mit einem passenden Chunk in der Vektor-Datenbank wird ganz anders beantwortet.
# Instanziieren und Ausführen des RAG-Programms. Zu der Frage gibt es einen passenden Eintrag im Vector Store
rag_pipeline = RAG()
question = "What happened to the orchestra's funding in 1939, and how did this change the orchestra's governance structure?"
prediction = rag_pipeline(question)
# Anzeigen der Ergebnisse
print(f"Frage: {question}")
print(f"Antwort: {prediction.answer}")Antwort:
Frage: What happened to the orchestra's funding in 1939, and how did this change the orchestra's governance structure?
Antwort: In 1939, the orchestra's sponsors withdrew their financial support, leading to the orchestra becoming self-governing. The players then took control of the organization's affairs, including pay, membership, and musical selections.
Zu der Frage „What happened to the orchestra’s funding in 1939, and how did this change the orchestra’s governance structure?“ hat Qdrant anscheinend mindestens einen passenden Chunk gefunden.
# Inspizieren des finalen Prompts, der an das LLM gesendet wurde
local_llm.inspect_history(n=1)Die Ausgabe von inspect_history zeigt den Prompt:
System message:
Your input fields are:
1. `context` (str): Relevante Fakten zur Beantwortung der Frage.
2. `question` (str): Die ursprüngliche Nutzerfrage.
Your output fields are:
1. `reasoning` (str):
2. `answer` (str): Eine prägnante und faktenbasierte Antwort.
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## context ## ]]
{context}
[[ ## question ## ]]
{question}
[[ ## reasoning ## ]]
{reasoning}
[[ ## answer ## ]]
{answer}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Beantworte die Frage basierend auf dem bereitgestellten Kontext.
User message:
[[ ## context ## ]]
[1] «In 1939 the orchestra 's sponsors stopped giving money to the orchestra . The orchestra became a self-governing body , which meant that , like the London Symphony Orchestra , the players organized the orchestra themselves , deciding on their pay , their members , what music they should play etc. In 1939 the orchestra 's sponsors withdrew their financial support and the orchestra became self-governing , with members of the orchestra themselves taking decisions on the organization 's affairs .»
[2] «In the 1930s , when Beecham conducted at the Royal Opera House , the orchestra played for operas there . In the 1930s the LPO was the orchestra for the international opera seasons at the Royal Opera House , Covent Garden , of which Beecham was artistic director .»
[3] «The associate conductor at the time was Malcolm Sargent . Its founding associate conductor was Malcolm Sargent .»
[[ ## question ## ]]
What happened to the orchestra's funding in 1939, and how did this change the orchestra's governance structure?
Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## answer ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`.
Der erste Eintrag passt genau zu der Frage (So ein Zufall 🙂 ) und das LLM konnte die Frage basierend auf dem Kontext korrekt beantworten.
Der Aufbau einer einfachen RAG-Pipeline in DSPy ist ein Prozess, der die Stärken von Information Retrieval und Sprachgenerierung kombiniert. Durch die klare Trennung von dspy.Retrieve und dspy.Predict lässt sich der Datenfluss transparent steuern. Diese Implementierung bildet eine robuste Grundlage. In den folgenden Tagen der Challenge können die einzelnen Komponenten – sowohl der Retriever als auch der Generator – mithilfe der Teleprompter von DSPy systematisch optimiert werden, um die Antwortqualität weiter zu verbessern.
