GLM-4.7-Flash ist ein kompaktes Large Language Model, das auf niedrige Latenz und moderate Hardwareanforderungen ausgelegt ist. In Kombination mit Ollama eignet es sich für lokale Inferenzszenarien, bei denen keine Cloud-Anbindung gewünscht oder möglich ist. Ziel dieses Beitrags ist es, die Ausführung von GLM-4.7-Flash auf einer mobilen Workstation objektiv zu dokumentieren und die gemessenen Leistungskennzahlen technisch einzuordnen.
Als Testplattform dient ein HP ZBook Ultra G1a mit AMD Ryzen AI Max+ PRO 395. Der Fokus liegt auf der reinen Inferenzleistung, nicht auf Fine-Tuning oder Training.
Erforderliche Ollama-Version für GLM-4.7-Flash
Für die Ausführung von GLM-4.7-Flash ist eine spezielle Ollama-Version erforderlich. Das Modell nutzt Funktionalitäten, die in stabilen Releases zum Zeitpunkt des Tests noch nicht vollständig verfügbar sind. Aus diesem Grund muss eine Release-Candidate-Version von Ollama installiert werden.
Die Installation erfolgt über das offizielle Installationsskript mit expliziter Versionsangabe:
curl -fsSL https://ollama.com/install.sh | OLLAMA_VERSION=0.14.3-rc2 sh
Dabei wird die Version 0.14.3-rc2 installiert, die die notwendigen Laufzeit- und Modellanpassungen für GLM-4.7-Flash enthält. Bestehende Ollama-Installationen werden durch diesen Vorgang überschrieben, sofern sie nicht zuvor entfernt oder isoliert wurden.
Technische Einordnung
Die Abhängigkeit von einer spezifischen Ollama-Version ist ein relevanter Aspekt für den produktiven Einsatz. Release-Candidate-Versionen sind funktional weitgehend vollständig, können jedoch noch Änderungen im API-Verhalten oder in der Modellintegration erfahren. Für reproduzierbare Benchmarks und stabile Tests ist daher eine feste Versionierung zwingend erforderlich.
In Entwicklungs- und Evaluierungsszenarien ist dieser Ansatz unkritisch. Für produktive Umgebungen empfiehlt sich hingegen, die weitere Entwicklung von Ollama abzuwarten oder die verwendete Version strikt zu pinnen, um ungewollte Änderungen an der Inferenzpipeline zu vermeiden.
Ergänzende Zusammenfassung
Zusätzlich zu den gemessenen Leistungsdaten ist die verwendete Ollama-Version ein wesentlicher Bestandteil des Testaufbaus. Die erfolgreiche Ausführung von GLM-4.7-Flash setzt aktuell die Installation von Ollama 0.14.3-rc2 voraus. Damit ist der Testaufbau klar reproduzierbar definiert und die erzielten Ergebnisse technisch nachvollziehbar.
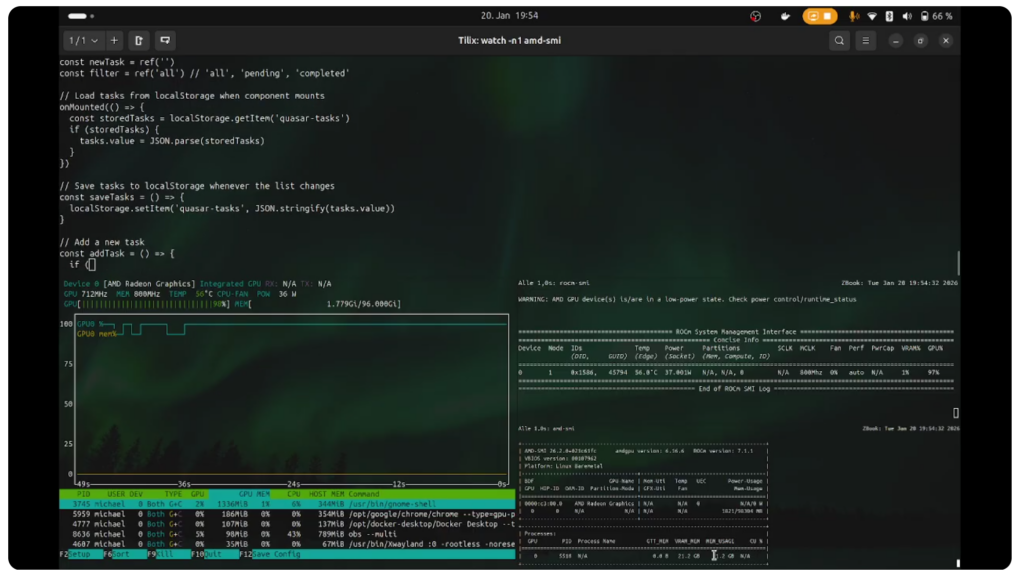
Die Ausführung erfolgt lokal über Ollama. Das Modell wird vorab geladen und anschließend mit einem kurzen Prompt zur Textgenerierung angestoßen. Die Messwerte stammen aus der von Ollama ausgegebenen Laufzeitstatistik und umfassen Ladezeiten, Prompt-Auswertung sowie die eigentliche Token-Generierung.
Relevante Rahmenbedingungen:
- Hardware: HP ZBook Ultra G1a
- CPU: AMD Ryzen AI Max+ PRO 395
- Ausführungsumgebung: Ollama (lokal)
- Modell: GLM-4.7-Flash
- Modus: Inferenz, Single Request
Gemessene Leistungsdaten
Die folgenden Kennzahlen wurden während eines vollständigen Inferenzdurchlaufs erfasst:
- Total duration: 2m54.274415618s
- Load duration: 98.379512ms
- Prompt eval count: 14 Token
- Prompt eval duration: 203.952292ms
- Prompt eval rate: 68.64 Token/s
- Eval count: 2690 Token
- Eval duration: 2m53.156480688s
- Eval rate: 15.54 Token/s
Interpretation der Ergebnisse
Die Ladezeit des Modells liegt unter 100 Millisekunden und ist damit im Kontext lokaler Inferenz vernachlässigbar. Dies deutet darauf hin, dass das Modell entweder bereits im Speicher vorliegt oder effizient initialisiert wird. Für wiederholte Anfragen in interaktiven Szenarien ist dieser Wert unkritisch.
Die Prompt-Auswertung erfolgt mit einer Rate von rund 68 Token pro Sekunde. Da der Prompt selbst nur 14 Token umfasst, ist die absolute Dauer gering. Dieser Wert ist primär für interaktive Anwendungen relevant, bei denen kurze Eingaben schnell verarbeitet werden müssen.
Der zentrale Leistungsindikator ist die eigentliche Token-Generierung. Mit 2690 erzeugten Token bei einer Rate von etwa 15,5 Token pro Sekunde ergibt sich eine Gesamtdauer von knapp drei Minuten. Dies zeigt, dass GLM-4.7-Flash auf dieser CPU-basierten Plattform stabil, aber klar durch die verfügbare Rechenleistung limitiert arbeitet. Für längere Ausgaben ist die Latenz deutlich spürbar, während kürzere Antworten in einem akzeptablen Zeitrahmen bleiben.
Einordnung im Anwendungskontext
Die gemessenen Werte sind typisch für die lokale Ausführung eines mittelgroßen Sprachmodells ohne dedizierte GPU-Beschleunigung. Für Anwendungsfälle wie:
- lokale Code- oder Textvervollständigung,
- technische Assistenz mit begrenzter Antwortlänge,
- Offline-Analyse und Prototyping,
ist die erreichte Performance ausreichend. Für Szenarien mit hohem Durchsatz oder sehr langen Generierungen ist diese Konfiguration hingegen nur eingeschränkt geeignet.
Verweis auf die Videoaufzeichnung
Die vollständige Ausführung des Tests ist als Video dokumentiert. Dort sind Modellstart, Prompt-Verarbeitung und Token-Generierung in Echtzeit nachvollziehbar. Dies ermöglicht eine direkte Einordnung der gemessenen Laufzeiten und der wahrgenommenen Latenz während der Inferenz.
Die Videoaufzeichnung ist unter folgendem Link abrufbar:
https://youtu.be/G_rOx7OcefM
Zusammenfassung
Der Test zeigt, dass GLM-4.7-Flash in Ollama auf einem HP ZBook Ultra G1a mit AMD Ryzen AI Max+ PRO 395 zuverlässig lauffähig ist. Die Modellinitialisierung ist schnell, die Prompt-Verarbeitung effizient, und die Token-Generierung erfolgt mit konstanter, aber moderater Geschwindigkeit. Damit eignet sich diese Kombination vor allem für lokale, kontrollierte Inferenzszenarien, bei denen Vorhersagbarkeit und Unabhängigkeit von externer Infrastruktur wichtiger sind als maximale Generationsgeschwindigkeit.
