
Der Zitat Generator soll in der Lage sein, zu einem vorgegebenen Thema ein Zitat im Stil einer bestimmten berühmten Persönlichkeit zu generieren. Das Projekt dient der Festigung der grundlegenden Konzepte von DSPy, insbesondere der Signatures und Predict-Module. Für ChainOfThought sehe ich hier keine Verwendeung, da es keine verschachtelten Aufgaben gibt, die man in Einzelschritten durchgehen muss. Theoretische Grundlagen Ich werde den Zitat-Generators auf den folgenden beiden Komponenten des DSPy-Frameworks aufbauen. Praktische Umsetzung Die Umsetzung erfolgt in mehreren Schritten: Konfiguration der Umgebung, Definition der Signatur, Erstellung des Vorhersagemoduls und schließlich die Ausführung des Programms. Konfiguration des Sprachmodells Zunächst muss wieder eine Verbindung zu einem Sprachmodell hergestellt werden. In diesem Beispiel wird ein Modell von Qwen verwendet. Es ist ein 8 Milliarden…
Kommentare geschlossenKategorie: Allgemein

Chain-of-Thought (CoT) ist eine Technik, die die Fähigkeit von Sprachmodellen (LLMs) bei komplexen, mehrstufigen Aufgaben verbessert. Anstatt eine direkte Antwort zu erzwingen, instruiert CoT das Modell, seine Schlussfolgerungen schrittweise herzuleiten und diesen Denkprozess explizit darzulegen, bevor das finale Ergebnis präsentiert wird. Das DSPy-Framework stellt für diesen Zweck das Modul dspy.ChainOfThought bereit. Theoretische Grundlagen von Chain of Thought (CoT) Standard-Prompting fordert ein LLM auf, direkt von einer Eingabe zu einer Ausgabe zu gelangen. Bei Aufgaben, die mehrere logische Schritte erfordern, ist dieser Ansatz fehleranfällig, da das Modell gezwungen ist, den gesamten Denkprozess intern und ohne explizite Struktur zu verarbeiten. Die CoT-Methode modifiziert diesen Prozess. Sie zerlegt die Aufgabenlösung in zwei Phasen: Reasoning (Schlussfolgern)Das Modell generiert eine schrittweise Herleitung der Lösung. Jeder…
Kommentare geschlossen
Ich habe ein Experiment gewagt. Mit nichts weiter als den Originalbildern, dem Text und dem Audio-Tool im Google AI Studio habe ich versucht, die Geschichte vorlesen zu lassen und muss sagen, das es wirklich gut funktioniert hat, auch wenn die Stimme zum Schluss etwas nachgelassen hat. Hier schon mal das Video. Das fertige Ergebnis: Paulinchens Geschichte, neu interpretiert. Der Prozess Die Erstellung war recht intuitiv. Anstatt Stunden im Tonstudio zu verbringen oder professionelle Sprecher zu buchen, nutzte ich die multimodalen Fähigkeiten von Google AI Studio. Ich habe den Reimtext direkt in das Tool geladen. Die KI generierte daraufhin eine Audio-Spur, die wie ein kurzes Hörbuch wirkt. Kein trockenes Vorlesen, sondern eine Darbietung. Anschließend habe ich die generierte Audiodatei mit den…
Kommentare geschlossen
In DSPy stellen Module die fundamentalen Bausteine zur Erstellung komplexer Anwendungen mit Sprachmodellen (LLMs) dar. Ein Modul kapselt eine bestimmte Logik – typischerweise einen oder mehrere Aufrufe an ein Sprachmodell – und kann mit anderen Modulen zu einer mehrstufigen Pipeline kombiniert werden. Dieser modulare Ansatz ermöglicht es, komplexe Probleme in überschaubare, wiederverwendbare Komponenten zu zerlegen. Die zentralen integrierten Module sind dspy.Predict und dspy.ChainOfThought. Während dspy.Predict für direkte Inferenzen von Eingabe zu Ausgabe verwendet wird, erweitert dspy.ChainOfThought diesen Prozess um einen expliziten Zwischenschritt des „Nachdenkens“, was die Qualität der Ausgabe bei anspruchsvollen Aufgaben verbessert. Das Ziel dieses Tages ist es, ein Programm zu erstellen, das zwei Module miteinander verkettet, um eine Aufgabe zu lösen, die eine sequenzielle Verarbeitung erfordert. Theorie: Die…
Kommentare geschlossen
Eine Signatur definiert auf deklarative Weise die Ein- und Ausgabestruktur für einen Aufruf an ein Sprachmodell (LLM). Sie ist das Kernstück, um die Interaktion mit dem Modell programmatisch und strukturiert zu gestalten, anstatt manuelle Prompts zu formulieren. Theorie: Die Funktion von DSPy-Signaturen Eine DSPy-Signatur ist eine Spezifikation, die dem LLM mitteilt, welche Aufgabe es ausführen soll. Sie besteht im Wesentlichen aus zwei Komponenten: Anstatt einen langen, detaillierten Prompt zu konstruieren, deklariert eine Signatur die semantischen Rollen der Ein- und Ausgaben. Zum Beispiel unterscheidet eine Signatur klar zwischen einer frage und einer antwort. Es gibt zwei primäre Methoden, Signaturen zu definieren: Inline oder als Klasse. Die klassenbasierte Methode bietet mehr Kontrolle und ermöglicht es, die Aufgabe durch einen Docstring genauer zu…
Kommentare geschlossen
Dieser Beitrag behandelt die grundlegende Struktur eines DSPy-Programms und dessen praktische Umsetzung. Das Ziel ist die Erstellung einer einfachen Frage-Antwort-Anwendung. Das habe ich zwar schon gestern erledigt, aber das war nur zum Testen ob alles wie erwartet funktioniert. Theorie: Die Grundstruktur eines DSPy-Programms Ein DSPy-Programm besteht aus drei Kernkomponenten, die ein modulares und programmatisches Arbeiten mit Sprachmodellen (LMs) ermöglichen. Die Kombination dieser drei Komponenten erlaubt es, LLM-basierte Anwendungen strukturiert zu programmieren, anstatt manuelle und oft fehleranfällige Prompts zu erstellen. Anbindung von LLMs Hier sind 10 Beispiele für die Anbindung verschiedener Language Models von unterschiedlichen Anbietern an DSPy. OpenAI Anthropic Databricks Gemini Weitere Provider DSPy erweitert seine Kompatibilität durch die Integration von LiteLLM, wodurch Dutzende weiterer LLM-Anbieter angebunden werden können. Die…
Kommentare geschlossen
Heute starte ich die 30-Tage-DSPy-Challenge. Die Idee ist, jeden Tag ein Stück tiefer in das DSPy-Framework einzutauchen, um am Ende nicht nur zu verstehen, was es kann, sondern es auch wirklich anwenden zu können. Ich möchte herausfinden, ob DSPy wirklich die Art und Weise verändert, wie ich mit großen Sprachmodellen (LLMs) arbeite. Die Theorie: Warum ich das hier überhaupt mache Bisher fühlt sich die Arbeit mit LLMs oft wie ein unstrukturiertes Herumprobieren an. Ich habe viel Zeit damit verbracht, Prompts in f-strings zu verpacken, mit Formulierungen zu jonglieren und zu hoffen, dass das Modell das gewünschte Ergebnis liefert. Das ist nicht nur mühsam, sondern auch extrem fragil. Ändert sich das Modell, kann die ganze Arbeit umsonst gewesen sein. Genau hier…
Kommentare geschlossen
In den nächsten 30 Tagen werde ich DSPy lernen. Ich werde alle wichtigen Aspekte des DSPy-Frameworks kennenlernen und meine Erfahrungen hier teilen. Dabei werde ich von den Grundlagen bis hin zu fortgeschrittenen Techniken an jedem Tag eine Mischung aus Theorie und praktischen Übungen auf dieser Webseite veröffentlichen. Mal sehen, ob DSPy sein Versprechen „The framework for programming—not prompting—language models“ hält und wirklich ein Game changer ist. Mit knapp 30.000 Stars auf GitHub und ca. 2.000.000 Downloads pro Monat erwarte ich schon etwas … Tag 1: Was ist DSPy? Theorie: Kernidee von DSPy: „Programming, not Prompting“ versehenen und lernen, wie DSPy die Entwicklung von LLM-Anwendungen durch einen programmatischen Ansatz vereinfacht und von traditionellem Prompt Engineering abhebt. Praxis: Einrichten der Entwicklungsumgebung. Installation…
Kommentare geschlossen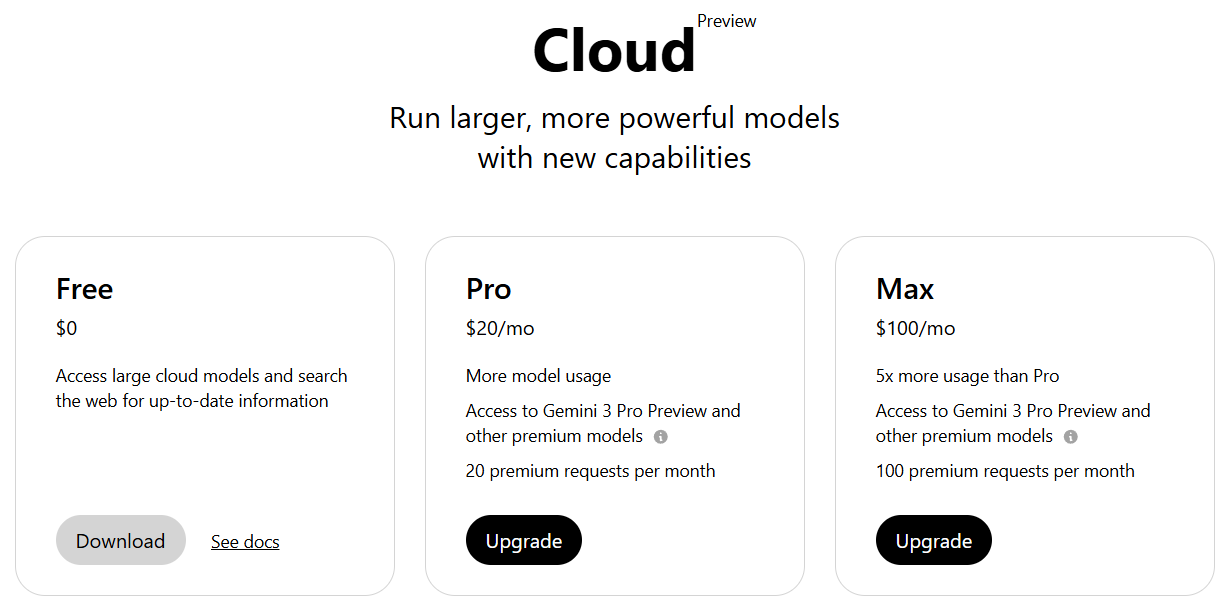
Ich habe gerade versucht, das brandneue Gemini 3 Pro Preview Modell über ollama zu starten, nur um von einer Fehlermeldung gestoppt zu werden. Hier beschriebe ich die Lösung für das kleine Probelm. Der Befehl ollama run gemini-3-pro-preview ist der Schlüssel zu enormer KI-Power direkt im Terminal. Doch in diesem Fall endet der erste Versuch mit einem frustrierenden Fehler: Error: 401 Unauthorized Warum bekomme ich einen „401 Unauthorized“ Fehler? Normalerweise bin ich es bei Ollama gewohnt, Modelle wie Qwen3 oder Mistral einfach herunterzuladen, ohne uns irgendwo anzumelden. Das liegt daran, dass diese Modelle öffentlich und frei zugänglich (Open Source) sind. Bei speziellen Cloud Modellen wie gemini-3-pro-preview sieht die Sache anders aus. Ein „401 Unauthorized“ bedeutet schlichtweg: „Ich weiß nicht, wer du…
Kommentare geschlossenWenn ich meinen Acer Nitro 5 mit einer RTX 3080 Grafikkarte für intensive KI Aufgaben nutze, passiert es gelegentlich, dass die blaue und die orangene LED plötzlich gleichzeitig anfangen zu blinken und der Akku trotz eingestecktem Netzteil nicht mehr lädt. Das ist echt ätzend da man in der Situation das Ladegeräte abziehen und wieder einstecken muss bevor der Laptop wieder lädt. Ich habe dieses Problem mal zum Anlass genommen, das neue Qwen3-Max Deep Research Feature zu testen und mal zu checken, was Qwen3-Max Deep Research zu dem Problem herausfinden kann. https://chat.qwen.ai/?inputFeature=deep_research Hier also das Ergebnis von Qwen3-Max Deep Research, dass mir als Markdown und PDF zum Download angeboten wurde – ich finde das Ergebnis kann sich sehen lassen. Analyse des…
Kommentare geschlossen