Chat-GPT hat in der letzten Zeit für viel Wirbel gesorgt. Das von OpenAI entwickelte Tool kann Texte generieren und Programmcode schreiben, Übersetzen und vieles mehr. Es gibt eine Menge großartiger Anwendungsbeispiele für die Nutzung von Chat-GPT, aber es gibt auch Einschränkungen, so kann Chat-GPT z.B. nicht auf Dokumente zugreifen, die nur im Intranet verfügbar sind oder noch sehr aktuell sind und beim Training des KI-Modells noch nicht zur Verfügung standen.
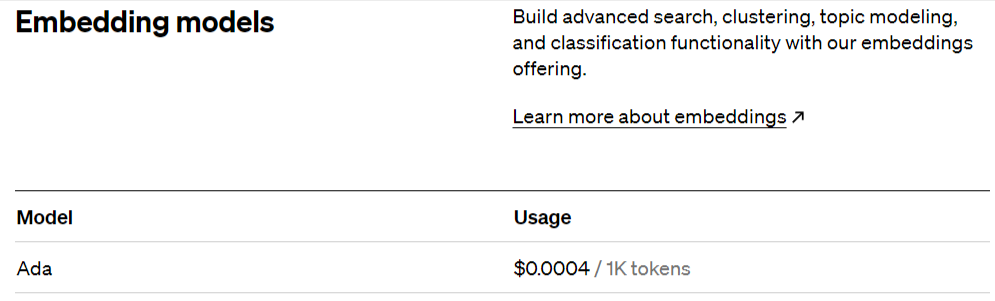
Um mit einem Buch/Dokument sprechen zu können sind einige Schritte nötig. Als erstes werden die Dokumente in sogenannte „Chunks“ aufgeteilt. Diese können z.B. 1000 Zeichen lang sein oder anders sinnvoll getrennt werden. Jeder dieser Chunks wird dann mit OpenAI Embeddings in einen Vektor umgewandelt. Der Preis für den Embeddings Endpunkt ist $0,0004 pro 1K Token.
Was ist ein Token?
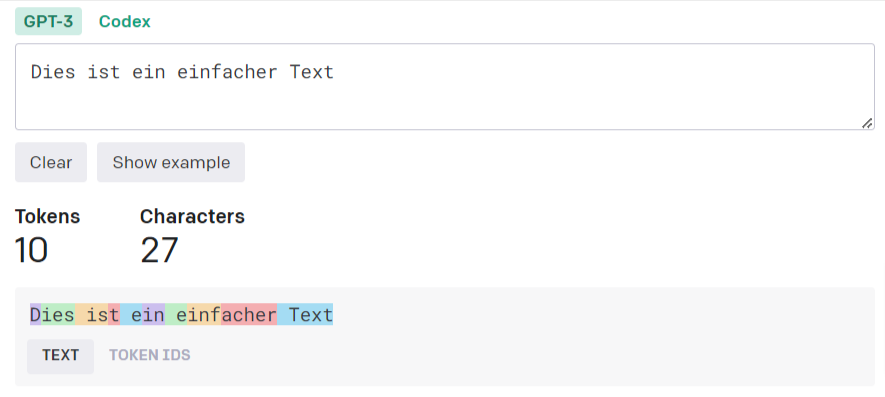
Token können Wörter, Wortteile, Buchstaben oder andere Elemente (Klammern, Komma, etc.) eines Textes sein. OpenAI gibt an, dass in einem englischen Texte 1 Token etwa 4 Zeichen oder 0,75 Wörtern entspricht. Zur genauen Berechnung hat OpenAI hat ein Tokenizer-Tool veröffentlicht. In dem Tokenizer Tool kann man einen Text eingeben und sich die Anzahl der Token und die daraus resultierenden Token anzeigen lassen.
Tokenizer Tool demo
In einem ersten Test habe ich das BGB (ca. 450 Seiten) in Chunks von je 1000 Zeichen aufgeteilt und in Vektoren umgewandelt. Die Kosten der OpenAI API Aufrufe dafür haben sich auf $0,20 belaufen. Die Kosten sind hier also überschaubar, vor allem, weil man diese Umwandlung in Vektoren nur einmal durchführen muss. Sobald die Vektoren erstellt sind, kann man sie in einer Vektor-Datenbank speichern und später jederzeit wieder verwenden. Die Vektor Datenbank ist in der Lage, diese Vektoren miteinander zu vergleichen und ähnliche Dokumente zu finden.
Gibt ein Benutzer nun eine Frage zu einem Dokument ein, wird diese Frage mit der OpenAI Embeddings API ebenfalls in einen Vektor umgewandelt und mit Hilfe der Vektoren in der Vektor-Datenbank die relevantesten Teile der gespeicherten Dokumente identifiziert. So ist es möglich einen Prompt zu erstellen, der sowohl die Frage als auch die relevanten Teile des Dokuments als Kontext enthält, ohne die maximale Token Anzahl zu überschreiten oder das Modell mit unnötigen Inhalten zu belasten (Beispiel: Siehe unten).
Verwendete Komponenten
Für die Implementierung werden folgende Komponenten verwendet:
OpenAI GPT-3 Insbesondere das Davinci Modell mit dem „/v1/completions“ Endpoint.
LangChain Eine Python Bibliothek, die Entwickler bei der Erstellung von Anwendungen im Zusammenhang mit Large Language Modellen (LLMs) unterstützt.
Chroma Chroma ist eine einfach zu bedienende Vektordatenbank/Vektorsuche, die man gut in Verbindung mit LangChain verwenden kann.
OpenAI Embeddings
Dank OpenAI Embeddings ist es möglich, eigene Dokumente mit OpenAI GPT zu nutzen.
OpenAI Embeddings sind eine Methode, Texte als Vektoren darzustellen. Ein so erzeugter Vektor entspricht dann der Thematik des Textes. Dadurch können Texte anhand ihrer Bedeutung miteinander verglichen werden, ohne dass dabei die gleichen Begriffe verwendet werden müssen.
Dank der OpenAI Embeddings ist es möglich, auch sehr große bzw. sehr viele Texte mit dem GPT-Modell zu nutzen, ohne die maximale Anzahl der Token zu überschreiten.
Um Embeddings-Vektoren zu erhalten, sendet man die Textzeichenfolge an den OpenaAI Embeddings API-Endpunkt (text-embedding-ada-002). Die Antwort ist dann ein Vektor mit 1536 Dimensionen, der von dem text-embedding-ada-002 Modell erstellt wurde. Vergleicht man 2 dieser Vektoren von 2 unterschiedlichen Texten miteinander, entspricht der Abstand zwischen den Vektoren dem Unterschied/Abstand der Inhalte/Themen. So haben die Vektoren von 2 sehr ähnlichen Texten nur einen geringen Abstand voneinander, währen die Vektoren von 2 sehr unterschiedlichen Texten einen sehr großen Abstand haben.
Erstellen der Vektor-Datenbank
Das Erstellen der Vektor-Datenbank in Chroma ist in wenigen Zeilen Code implementiert.
1. Laden der beiden Dokumente mit Hilfe der LangChain UnstructuredPDFLoader Komponnente.
In dem beiden Variablen data1 und data2 sind nun die jeweiligen Inhalte der PDF gespeichert. Dieser Schritt ist gerade bei sehr großen Dokumenten etwas langsam daher sollte man hier bei großen Datenmengen etwas Zeit einplanen.
2. Aufsplitten der Dokumente in Chunks a 1000 Zeichen mit dem LangChain RecursiveCharacterTextSplitter.
In der Variable ‚texts‘ sind nun die Chunks beiden Dokumente gespeichert. Diese werden nun im nächsten Schritt mit der OpenAIEmbeddings API in Vektoren umgewandelt und in der Vektor-Datenbank Chroma persistiert.
Durch das Speichern der Embeddings (Vektoren) wird die Suche nach Dokumenten mit einer ähnlichen oder gleichen Bedeutung möglich. Im Gegensatz zu einer herkömmlichen Datenbank wird hier nicht nach Worten oder Teilstrings gesucht, sondern die Vektoren verwendet, die dem Inhalt/Thema der Chunks entsprechen. Hinweis: Die Verwendung von OpenAIEmbeddings führt dazu, dass alle Chunks aus dem Quelldokument an den OpenAI Embeddings API Endpunkt gesendet werden. Dokumente, die das Haus nicht verlassen dürfen (highly confidential), müssen auf jeden Fall ausgeschlossen werden.
Nun ist die Vektor-Datenbank erstellt und es ist nun möglich die relevanten Teile (Chunks) der Dokumente zu einer Frage oder einem anderen Text mit vergleichbarem Bezug zu identifizieren.
Relevante Chunks finden, Prompt erzeugen und GPT-Model aufrufen
Das Finden von relevanten Chunks zu einer Frage oder einer anderen Eingabe erfolgt in einer sog. Chain der LangChain Bibliothek, die aus folgenden Teilen besteht.
1. Die Frage bzw. Eingabe wird in einen Vektor umgewandelt. Dazu wird die Eingabe wieder an OpenAIEmbeddings übergeben und der resultierende Vektor ermittelt. (Bei diesem Schritt entstehen Kosten für den Aufruf der OpenAI Embeddings API)
2. Mit dem Vektor der Eingabe werden dann die 5 relevantesten Chunks aus der Vektor-Datenbank gelesen.
3. Aus der ursprünglichen Frage/Eingabe und den 5 ausgewählten Chunks wird ein Prompt erstellt
4. Der Prompt wird über die OpenAI API an das GPT-Modell übergeben und das Ergebnis angezeigt. (Bei diesem Schritt entstehen Kosten für den Aufruf der OpenAI API)
Das folgende Code-Beispiel ergänzt diese Schritte um einen Flask-Webserver, der die Eingabe als HTTP-Request entgegennimmt und die Antwort als JSON-Objekt zurückgibt. Hinweis: Zum Anzeigen des erstellten Prompts kann man z.B. den Parameter verbose=True beim Laden der QA-Chain setzen.
from flask import Flask, json, request
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
OPENAI_API_KEY = '...'
embedding = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
persist_directory = 'canabis'
docsearch = Chroma(persist_directory=persist_directory, embedding_function=embedding)
llm = OpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
api = Flask(__name__)
@api.route('/canabis', methods=['GET'])
def ask_bgb():
args = request.args
query=args.get("question")
docs = docsearch.similarity_search(query, k=5, include_metadata=True)
print (len(docs))
doc_list = []
for doc in docs:
doc_list.append(doc.page_content)
print ("######")
result = chain.run(input_documents=docs, question=query)
response = {"docs" : doc_list, "result": result}
# response = {"result": result}
return response
api.run()
Die UI besteht aus einem einfachen Bootstrap PHP Skript, das die JSON-Daten lädt und auf einer Webseite anzeigt.
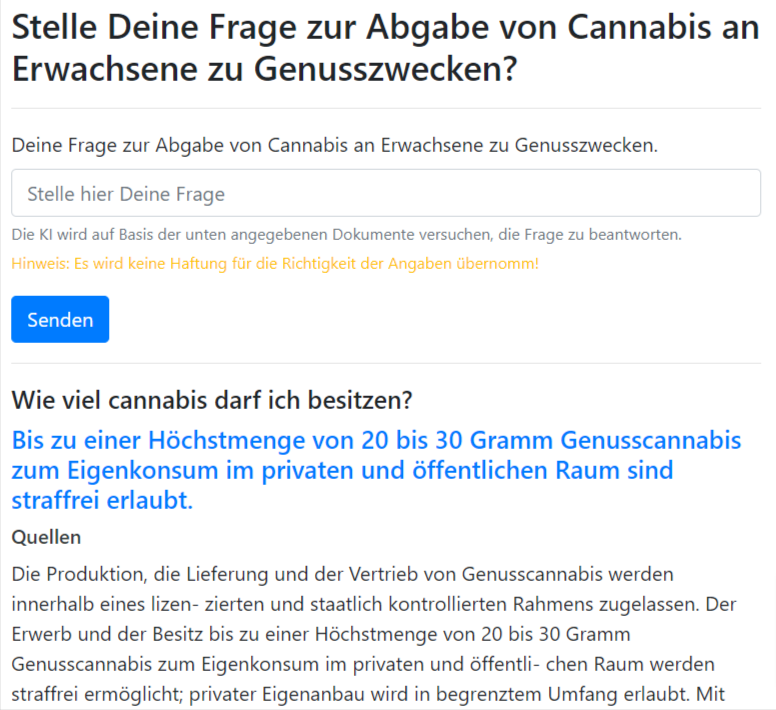
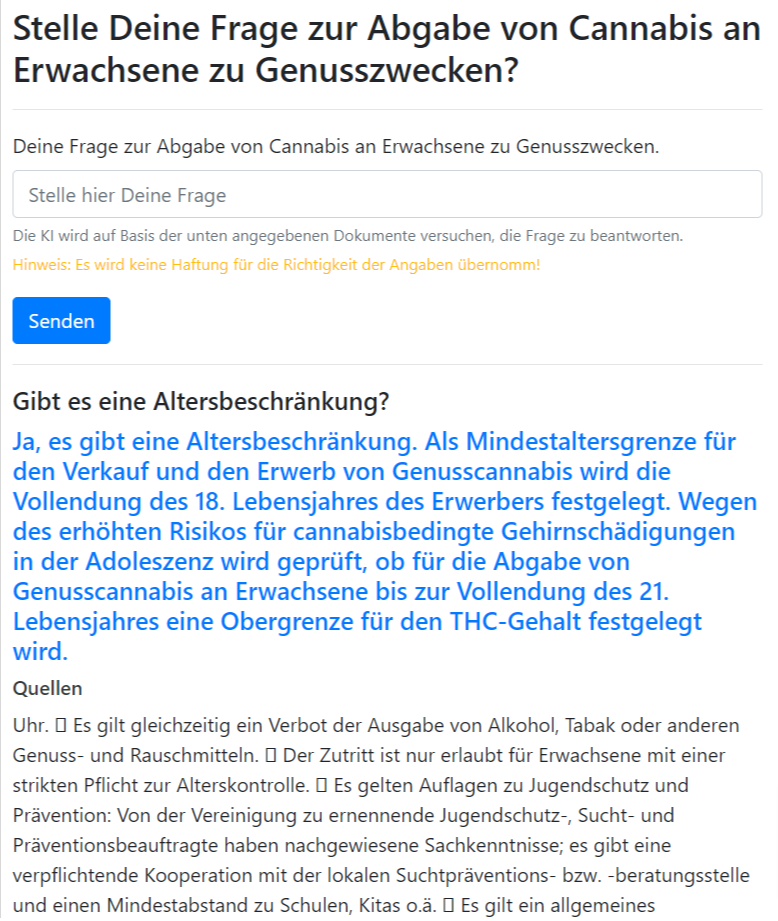
Das Ergebnis sieht dann wie folgt aus: Auf die Frage „Wie viel cannabis darf ich besitzen?“ antwortet das GPT-Modell nun mit „Bis zu einer Höchstmenge von 20 bis 30 Gramm Genusscannabis zum Eigenkonsum im privaten und öffentlichen Raum sind straffrei erlaubt.“
Neben der Antwort werden auch noch die Quellen (Chunks) angegeben, die für die Ermittlung der Informationen betrachtet wurden.
Stellt man Chat-GPT die gleiche Frage, erhält man eine ganz andere und viel allgemeinere Antwort, da Chat-GPT auf dem Stand von September 2021 trainiert wurde und die beiden verwendeten Dokumente
nicht kennt, da sie erst im April 2023 (Cannabis-Eckpunkte eines 2-Säulen-Modells) und im Oktober 2022 (Kabinettvorlage: Eckpunktepapier zur kontrollierten Abgabe von Cannabis) veröffentlicht wurden.
Ich: Wie viel Cannabis darf ich besitzen?
Chat-GPT: Die Antwort auf diese Frage hängt von Ihrem Standort und den örtlichen Gesetzen ab. In einigen Ländern und Bundesstaaten ist der Besitz und Konsum von Cannabis legalisiert, während es in anderen illegal bleibt. Selbst in Ländern und Staaten, in denen Cannabis legal ist, gibt es häufig Beschränkungen in Bezug auf die Menge, die eine Person besitzen oder konsumieren darf. Daher ist es wichtig, die Gesetze in Ihrer Region zu überprüfen, um sicherzustellen, dass Sie sich innerhalb der gesetzlichen Grenzen bewegen. In einigen Fällen kann der Besitz von Cannabis auch zu strafrechtlichen Konsequenzen führen, wenn bestimmte Mengen überschritten werden.
Konverstion mit Chat-GPT ohne zusätzlichen Kontext
Mit dem Schalter verbose=True kann man sich den Prompt, der von LangChain erstellt wurde, anzeigen lassen. Dieser Prompt sieht dann wie folgt aus:
Use the following pieces of context to answer the question at the end. If you don’t know the answer, just say that you don’t know, don’t try to make up an answer.
Die Produktion, die Lieferung und der Vertrieb von Genusscannabis werden innerhalb eines lizen- zierten und staatlich kontrollierten Rahmens zugelassen. Der Erwerb und der Besitz bis zu einer Höchstmenge von 20 bis 30 Gramm Genusscannabis zum Eigenkonsum im privaten und öffentli- chen Raum werden straffrei ermöglicht; privater Eigenanbau wird in begrenztem Umfang erlaubt. Mit Inkrafttreten der geplanten Neuregelung sollen laufende Ermittlungs- und Strafverfahren zu dann nicht mehr strafbaren Handlungen beendet werden.
dann nicht mehr strafbaren Handlungen beendet werden.
Für Genusscannabis werden Darreichungsformen zum Rauchen und Inhalieren sowie zur nasalen und oralen Aufnahme (Kapseln, Sprays, Tropfen) erlaubt. Es werden Vorgaben festgelegt, um die Qualität und Reinheit sicherzustellen. Synthetisch hergestellte Cannabinoide werden nicht zugelas- sen.
Sonderregelungen zu Nutzhanf und Cannabidiol (CBD)
lizenzierten Produktions-, Liefer- und Vertriebskette sind grundsätzlich straffrei. Der Erwerb und der Besitz bis zu einer Höchstmenge von 20 bis 30 Gramm Genusscannabis (getrocknete Pflanzen) zum Eigenkonsum im privaten und im öffentlichen Raum sind unabhängig vom konkreten THC- Gehalt und Herkunft straffrei. Denn in der Praxis kann der THC-Wert sowie die Herkunft des Ge- nusscannabis nur mit hohem labortechnischen Aufwand festgestellt werden. Dadurch ist eine Ent- lastung der Strafverfolgungsbehörden im Hinblick auf aufwändige und unverhältnismäßige labor- technische Untersuchungen bezüglich des THC-Gehalts bei Genusscannabis (getrockneten Pflan- zen) zu erwarten. Überdies wird geprüft, ob in einem Gesetzentwurf andere pauschale Gewichts- oder Mengengrenzen für Harz bzw. Flüssigkeiten zu berücksichtigen sind, die die ggf. unterschiedli-
gelten Strafvorschriften für darüber hinaus gehenden Besitz, für Handel und Abgabe an Nicht- Mitglieder sowie Kinder und Jugendliche sowie für die Abgabe von nicht in den Vereinigungen selbst angebautem Cannabis. Die Grenzwerte im Straßen-, Schiffs- und Luftverkehr werden unter Einbeziehung der ein- schlägigen Fachgremien überprüft. Regelungen über die Zulässigkeit von Fahrten unter Einfluss von Cannabis orientieren sich dabei ausschließlich an den Erfordernissen der Verkehrssicher- heit. Der straffreie private Eigenanbau umfasst max.
weibliche blühende Pflanzen und ist vor dem Zugriff durch Kinder und Jugendliche zu schützen. Es wird ermöglicht, Verurteilungen, die ausschließlich wegen Handlungen im Zusammenhang mit Cannabis eingetragen sind, für die das Gesetz künftig keine Strafe mehr vorsieht (Besitz bis
g/Eigenanbau bis max.
Die kontrollierte Abgabe von Cannabis zu Genusszwecken erfolgt in behördlich zugelassenen und überwachten Geschäften, ggf. auch in Apotheken. Die lizenzierten Geschäfte sind alleine auf den Verkauf und die Beratung im Hinblick auf Genusscannabis ausgerichtet; eine Verknüpfung mit dem Verkauf anderer Genussmittel wie Tabak und Alkohol findet nicht statt. Pro Erwerbsvorgang darf lediglich eine Höchsterwerbsmenge pro Person entsprechend der maximalen Eigenbesitzmenge ab- gegeben werden, wobei keine Abgabe für Dritte erfolgen darf. Die Betreiber und das Verkaufsperso- nal der lizenzierten Geschäfte sind verpflichtet, einen Sachkundenachweis zu erbringen sowie spezi- fische Beratungs- und Präventionskenntnisse nachzuweisen. Überdies wird pro Verkaufsstelle ein Ansprechpartner für den Jugendschutz benannt. Bei jedem Kauf wird ein Beratungsgespräch ange- boten. Darüber hinaus werden bei Verkauf von THC-haltigen Produkten aufklärende Informationen über Cannabis, einen risikoarmen Konsum sowie
Als Mindestaltersgrenze für den Verkauf und den Erwerb (vgl. Ziffer 9) von Genusscannabis wird die Vollendung des 18. Lebensjahres des Erwerbers festgelegt. Verstöße der Lizenznehmer gegen diese Vorgabe werden als Ordnungswidrigkeit verfolgt. Wegen des erhöhten Risikos für cannabisbedingte Gehirnschädigungen in der Adoleszenz wird geprüft, ob für die Abgabe von Genusscannabis an Er- wachsene bis zur Vollendung des 21. Lebensjahres eine Obergrenze für den THC-Gehalt festgelegt
Question: Wie viel cannabis darf ich besitzen? Helpful Answer:
Dass der Prompt hier mehrsprachig ist, liegt daran, dass LangChain einige Textbausteine verwendet, die in englischer Sprache vorliegen. Die eigentlichen Inhalte sind dann in deutscher Sprache (Kontext und Frage). Das scheint dem GPT-Modell aber nichts auszumachen.
Am Anfang des Prompt steht die Anweisung „Use the following pieces of context to answer the question at the end. If you don’t know the answer, just say that you don’t know, don’t try to make up an answer.“ (Deutsch: Beantworte die Frage am Ende des Textes anhand der folgenden Informationen. Wenn keine Antwort möglich ist, sage einfach, dass es nicht möglich ist die Frage zu beantworten, versuche nicht, eine Antwort zu erfinden.) Auf diese Anweisung folgen dann die relevanten Teile der Dokumente und zum Schluss die Frage mit dem Prefix „Question:“ und dem Hint „Helpful Answer:“.
Dieser sehr umfangreiche Prompt wird von der LangChain question_answering Chain erstellt und an über die OpenAI API an das GPT-Modell übergeben. Das GPT-Modell versucht dann, den Text der hier mit „Helpful Answer:“ endet zu vervollständigen und kann dank der Transformer Architektur des Modells auf den kompletten Prompt zugreifen und anhand der relevanten Informationen eine Antwort in natürlicher Sprache formulieren.
Fazit
Embeddings ermöglichen es, semantische Ähnlichkeiten zwischen Sätzen zu erfassen und auf dieser Grundlage Muster zu erkennen. Auf diese Weise kann das GPT-Modell in die Lage versetzt werden, kontextbezogene Aussagen zu treffen die ohne den Kontext unmöglich währen. OpenAI Embeddings, LangChain und Chroma sind nützliche Werkzeuge, wenn es darum geht, den individuellen Kontext zu selektieren und in der natürlichen Sprachverarbeitung zu nutzen.
Hinweis
Leider kann ich die Web-App nicht öffentlich zur Verfügung stellen, da jede Anfrage Kosten verursacht. Auch wenn es nur Bruchteile von Cent-Beträgen sind, so läppert es sich dann in Summe doch wieder. Auf Anfrage kann ich die Web-App aber für Test-Zwecke aktivieren. Bei Bedarf bitte einfach bei mir melden :-).
Weitere Tests
Hier noch ein paar Beispiele:
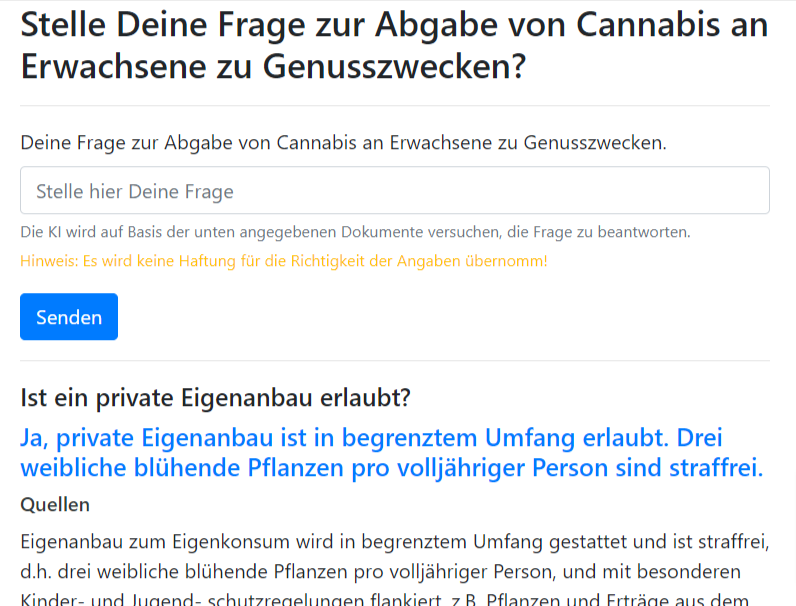
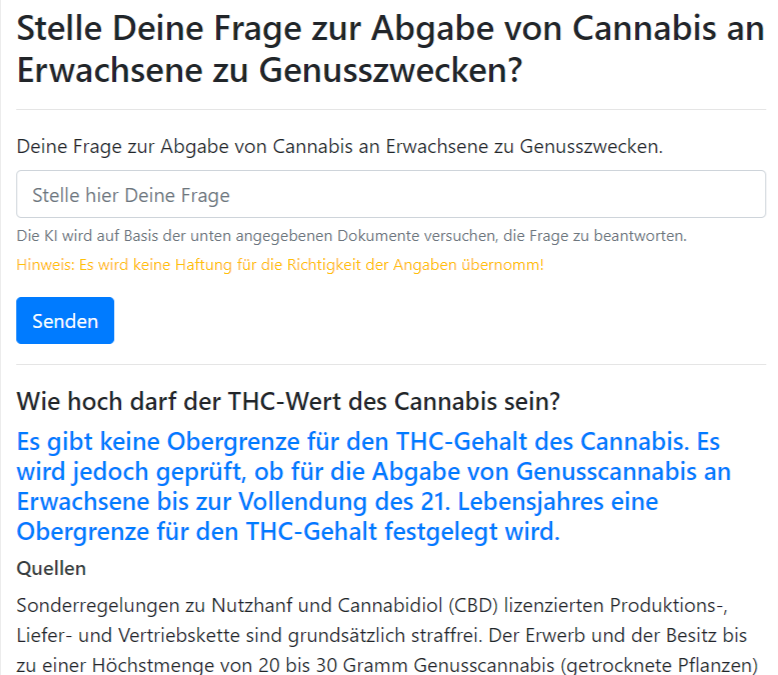
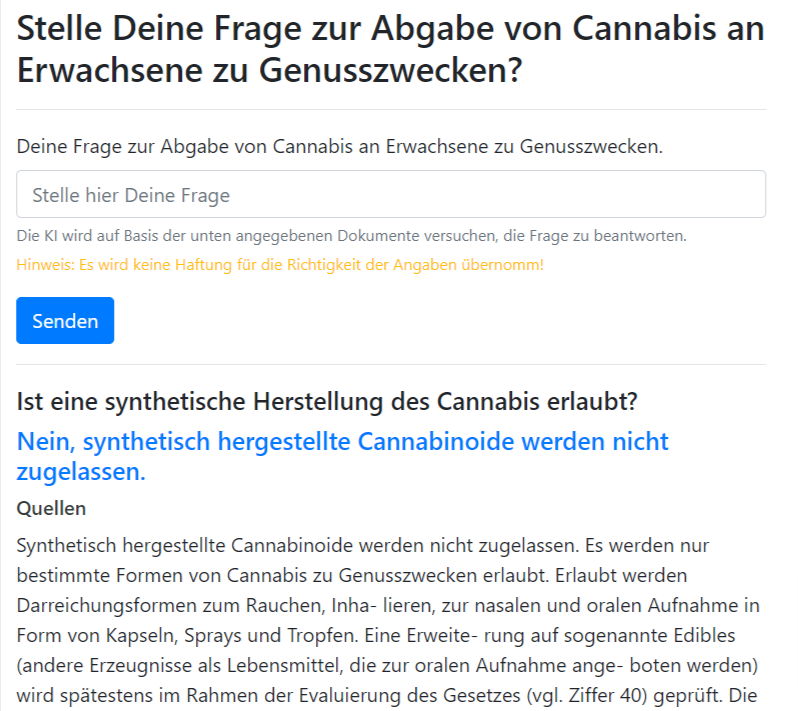
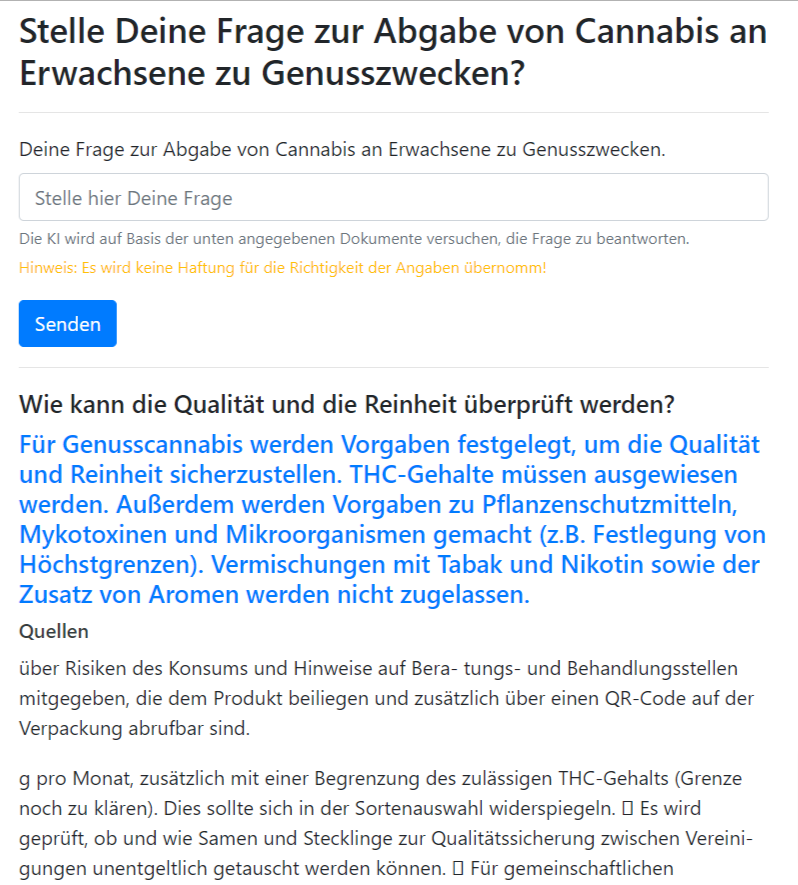
Ist ein private Eigenanbau erlaubt? Ja, private Eigenanbau ist in begrenztem Umfang erlaubt. Drei weibliche blühende Pflanzen pro volljähriger Person sind straffrei.Wie hoch darf der THC-Wert des Cannabis sein? Es gibt keine Obergrenze für den THC-Gehalt des Cannabis. Es wird jedoch geprüft, ob für die Abgabe von Genusscannabis an Erwachsene bis zur Vollendung des 21. Lebensjahres eine Obergrenze für den THC-Gehalt festgelegt wird.Ist eine synthetische Herstellung des Cannabis erlaubt? Nein, synthetisch hergestellte Cannabinoide werden nicht zugelassen.Wie kann die Qualität und die Reinheit überprüft werden? Für Genusscannabis werden Vorgaben festgelegt, um die Qualität und Reinheit sicherzustellen. THC-Gehalte müssen ausgewiesen werden. Außerdem werden Vorgaben zu Pflanzenschutzmitteln, Mykotoxinen und Mikroorganismen gemacht (z.B. Festlegung von Höchstgrenzen). Vermischungen mit Tabak und Nikotin sowie der Zusatz von Aromen werden nicht zugelassen.Gibt es eine Altersbeschränkung? Ja, es gibt eine Altersbeschränkung. Als Mindestaltersgrenze für den Verkauf und den Erwerb von Genusscannabis wird die Vollendung des 18. Lebensjahres des Erwerbers festgelegt. Wegen des erhöhten Risikos für cannabisbedingte Gehirnschädigungen in der Adoleszenz wird geprüft, ob für die Abgabe von Genusscannabis an Erwachsene bis zur Vollendung des 21. Lebensjahres eine Obergrenze für den THC-Gehalt festgelegt wird.
PS: Auch wenn es sehr viel Spaß macht, den Dokumenten Fragen zu stellen, ist es doch nicht wirklich relevant für mich, da ich Cannabis nicht so gut vertrage. ?