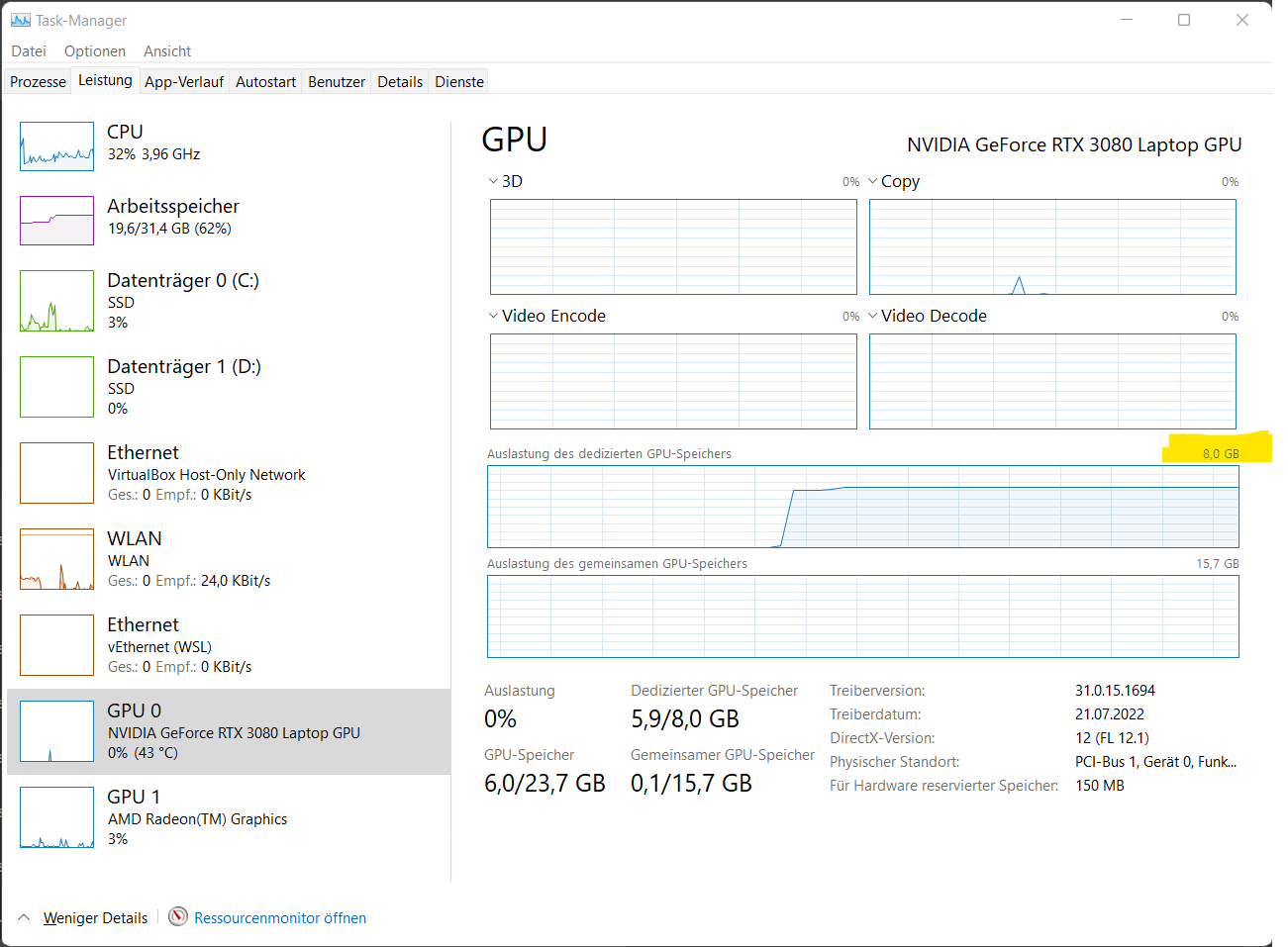
Nachdem ich gestern bei meinem Test von Whisper Mic von meiner Grafikkarte so enttäuscht wurde, habe ich gedacht, ich check das mal unter Windows und trainiere mal ein relativ aufwändiges Tensorflow Modell. Evtl. habe ich die Treiber falsch installiert oder irgendetwas anderes ist schief gelaufen – aber wie es scheint ist das nicht der Fall, denn der Windows Taskmanager bestätigt, was ich unter Linux gesehen habe.
Es gibt also auf der Grafikkarte einen „Dedizierten GPU-Speicher“ und einen „Gemeinsamen GPU Speicher“, der von CUDA nicht genutzt werden kann.
Unter https://en.wikipedia.org/wiki/Shared_graphics_memory kann man dann nachlesen, dass sich der Begriff „gemeinsam genutzter Grafikspeicher“ auf ein Design, bei dem der Grafikchip nicht über einen eigenen Speicher verfügt, sondern den Hauptspeicher des Systems mit der CPU und anderen Komponenten teilt.
Dieses Design wird bei vielen integrierten Grafiklösungen verwendet, um die Kosten und die Komplexität des Motherboard-Designs zu reduzieren, da keine zusätzlichen Speicherchips auf dem Board erforderlich sind. In der Regel gibt es einen Mechanismus (über das BIOS oder eine Jumper-Einstellung), mit dem die Menge des für die Grafik zu verwendenden Systemspeichers ausgewählt werden kann, was bedeutet, dass das Grafiksystem so angepasst werden kann, dass es nur so viel Arbeitsspeicher verwendet, wie tatsächlich benötigt wird, und der Rest für Anwendungen frei bleibt. Ein Nebeneffekt ist, dass ein Teil des Arbeitsspeichers, der für die Grafik zugewiesen wird, für andere Anwendungen nicht mehr zur Verfügung steht. Ein Computer mit 512 MiB RAM und 64 MiB Grafik-RAM erscheint dem Betriebssystem und dem Benutzer so, als ob nur 448 MiB RAM installiert wären.
Der Nachteil dieses Konzepts ist die geringere Leistung, da der System-RAM in der Regel langsamer läuft als der dedizierte Grafik-RAM und es zu mehr Konflikten kommt, da der Speicherbus mit dem Rest des Systems geteilt werden muss. Außerdem kann es zu Leistungsproblemen mit dem übrigen System kommen, wenn nicht berücksichtigt wird, dass ein Teil des Arbeitsspeichers von der Grafikkarte „weggenommen“ wird.
Unter https://stackoverflow.com/questions/47859924/use-shared-gpu-memory-with-tensorflow steht dann auch noch etwas, dass ich beim Kauf des Acer Nitro 5 nicht gewusst habe.
Der gemeinsam genutzter Grafikspeicher ist nicht auf der NVIDIA GPU, und CUDA kann den Speicher nicht verwenden. Tensorflow kann ihn nicht nutzen, wenn das Model auf der GPU läuft, weil CUDA es nicht nutzen kann….
Unter https://github.com/IBM/tensorflow-large-model-support habe ich dann noch eine interessante Lösung gefunden.
TensorFlow Large Model Support (TFLMS) ist eine Funktion in TensorFlow, die von IBM Watson Machine Learning Community Edition (WML CE) bereitgestellt wird und das erfolgreiche Training von Deep-Learning-Modellen ermöglicht, die andernfalls den GPU-Speicher auslasten und mit „Out-of-Memory“-Fehlern abbrechen würden. LMS verwaltet diese Überbelegung des GPU-Speichers, indem Tensoren vorübergehend in den Host-Speicher ausgelagert werden, wenn sie nicht benötigt werden.
Klingt spannend und muss auf jeden Fall mal ausprobiert werden. Vermutlich geht die Performance eines Modells in den Keller, aber das muss erst mal getestet werden.
Unter https://www.ibm.com/docs/en/wmlce/1.7.0?topic=installing-mldl-frameworks steht auch eine Liste von Frameworks, die enthalten sind und LMS unterstützen. Darunter ist auch Pytorch was ja von Whisper genutzt wird.

Das werde ich dann wohl bei Gelegenheit auch mal testen müssen 🙂