
CUDA out of memory. Tried to allocate 3.73 GiB. GPU 0 has a total capacty of 14.75 GiB of which 3.45 GiB is free. Process 9648 has 11.29 GiB memory in use. Of the allocated memory 11.18 GiB is allocated by PyTorch, and 1.91 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Die Fehlermeldung „CUDA out of memory“ hat vermutlich Jeder schon mal gesehen, der versucht hat, größere LLMs auf einer Consumer-GPU laufen zu lassen. Der Fehler besagt, dass der Speicher auf der Grafikkarte knapp wird und keine weiteren Ressourcen für die aktuelle Operation zur Verfügung stehen.
Moderne Grafikkarten von NVIDIA haben zwar schon einen großen Grafikkarten-Speicher, aber moderne LLM benötigen oft viel mehr VRAM als die Grafikkarte liefert. Ein effizientes Speichermanagement kann aber helfen die KI-Anwendungen trotz limitierter Ressourcen auf einer Consumer Grafikkarte ausführen zu können. So können Entwickler sicherstellen, dass die KI-Modelle trotz der limitierten Ressourcen reibungslos laufen und auch größere Datensätze oder komplexere Modelle erfolgreich laufen.
Im Folgenden werde ich anhand einiger Beispiele zeigen, wie man mit dem „CUDA out of memory“ umgeht und die Probleme analysiert und auch beheben kann. Alle Beispiele können in Google-Colab nachgestellt werden. Die zugehörigen Jupyter-Notebooks verlinke ich am Ende des Blog-Posts.
Ein einfaches Beispiel
Das folgende Beispiel demonstriert den Fehler, ohne ein KI-Model zu laden. Das Beispiel lädt nur eine Menge von Werten in den GPU-Speicher.
import torch # Importiere die PyTorch-Bibliothek
import gc # Importiere die garbage collection Bibliothek (zum manuellen
# Aufrufen des Garbage Collectors)
# Erstelle zwei Tensorobjekte (Nullen) auf der GPU mit einer Größe von
# 1.000.000.000 (entspricht etwa 3,8 GB pro Tensor),
# einem Datentyp von float32 und speichere sie in den Variablen 'a' und 'b'
a = torch.zeros(3000000000, dtype=torch.float32, device='cuda')
b = torch.zeros(1000000000, dtype=torch.float32, device='cuda')
# Gib die aktuelle allokierte GPU-Speichermenge in Megabyte (MB) aus, indem die
# Methode memory_allocated() auf der CUDA-Instanz von torch ausgeführt und durch
# 1024^2 (Mega) geteilt wird
print(torch.cuda.memory_allocated() / 1024**2)
# Gib die aktuelle reservierte GPU-Speichermenge in Megabyte (MB) aus, indem du
# die Methode memory_reserved() auf der CUDA-Instanz von torch ausgeführt und durch
# 1024^2 (Mega) geteilt wird
print(torch.cuda.memory_reserved()/ 1024**2)
# Gib eine Zusammenfassung der Speicherauslastung auf der GPU aus
print(torch.cuda.memory_summary())
Führt man den obigen Code aus, erhält man folgenden Fehler:
OutOfMemoryError Traceback (most recent call last)
<ipython-input-4-44850c09f51d> in <cell line: 2>()
1 a = torch.zeros(3000000000, dtype=torch.float32, device='cuda')
----> 2 b = torch.zeros(1000000000, dtype=torch.float32, device='cuda')
3 print(torch.cuda.memory_allocated() / 1024**2)
4 print(torch.cuda.memory_reserved()/ 1024**2)
5 print(torch.cuda.memory_summary())
OutOfMemoryError: CUDA out of memory. Tried to allocate 3.73 GiB. GPU 0 has a total capacty of 14.75 GiB of which 3.45 GiB is free. Process 105914 has 11.29 GiB memory in use. Of the allocated memory 11.18 GiB is allocated by PyTorch, and 1.91 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Der Tensor „a“ benötigt 11.29 GB VRAM des 14.75 GB verfügbaren VRAMs. Für den Tensor „b“ versucht Pytorch 3.73GB VRAM zu allokieren was dann zu der „OutOfMemoryError: CUDA out of memory.“ Fehlermeldung führt. Der folgende Screenshot der Google-Colab Resourcen zeigt, dass der GPU-RAM hier schon im gelben Bereich ist.
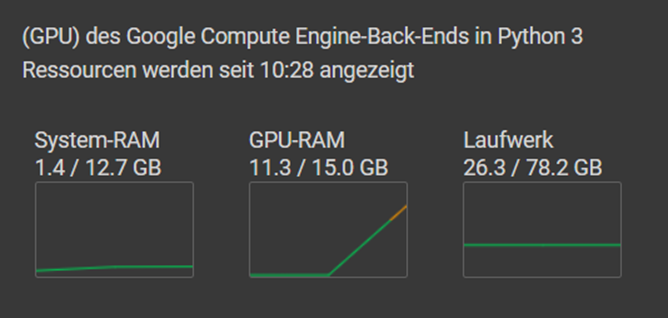
Den GPU-RAM freigeben kann man, indem man die Variable a löscht, den Garbage Collector aufruft und den Cache löscht.
a.detach()
del a
gc.collect()
torch.cuda.empty_cache()
Die Variable wird aus dem Speicher gelöscht, der Speicher wird sofort freigegeben und steht wieder zur Verfügung.
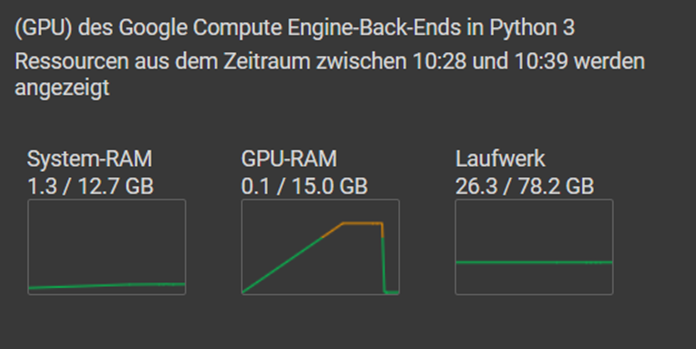
Optional kann auch noch die Methode torch.cuda.synchronize() aufgerufen werden. Die Methode wird in PyTorch genutzt, um sicherzustellen, dass alle auf der GPU ausgeführten Befehle bis zu dem Zeitpunkt, an dem diese Methode aufgerufen wird, abgeschlossen sind. Wenn Berechnungen auf der GPU asynchron ausgeführt werden, kann es vorkommen, dass Code weiter ausgeführt wird, bevor die GPU-Berechnungen vollständig abgeschlossen sind. Wenn dann die Variablen zu früh gelöscht werden, kann das zu Fehlern bzw. unerwarteten Ergebnissen führen. In den hier vorgestellten Beispielen ist das nicht der Fall, daher verzichte ich auf den torch.cuda.synchronize() Aufruf.
Um den Speicherbedarf zu reduzieren kann man nun beispielsweise den Datentyp von Float32 auf Float16 (auch als Half Precision bekannt) reduzieren. Dadurch wird zwar die Genauigkeit der Gleitkommazahlen reduziert, aber auch der Speicherbedarf halbiert und beide Variablen passen in den GPU-RAM.
a = torch.zeros(3000000000, dtype=torch.float16, device='cuda')
b = torch.zeros(1000000000, dtype=torch.float16, device='cuda')
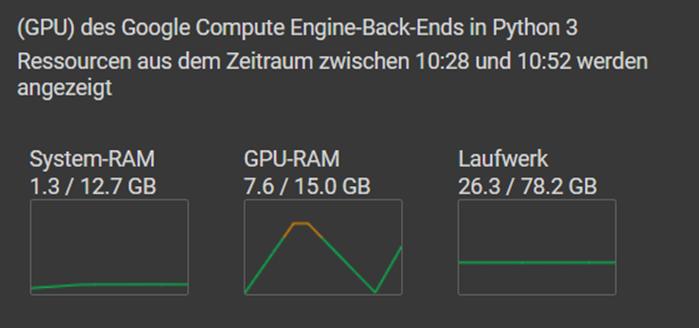
Diese Methode ist sehr weit verbreitet in der KI-Welt und wird gelegentlich auch bis auf die Spitze getrieben, so dass es z.B. LLMs als 4-Bit Variante gibt. Das führt dazu, dass man z.B. für ein „Llama-2-13B-chat-GPTQ (TODO https://huggingface.co/TheBloke/Llama-2-13B-chat-GPTQ)“ mit etwa 13 Milliarden Parametern statt der 52GB GPU-RAM für eine Float32 Variante nur ca. 7.5 GB GPU-RAM benötigt. Das führt zu einer stark reduzierten Genauigkeit der Parameter, was aber erstaunlicherweise keine signifikanten Auswirkungen auf die Leistung des Modells haben kann. Dies ist auf die Fähigkeit von Modellen wie dem „Llama-2-13B-chat-GPTQ“ zurückzuführen, mit geringerer Präzision zu arbeiten und dennoch qualitativ hochwertige Ergebnisse zu liefern. Bei vielen Anwendungen im Bereich des maschinellen Lernens hat sich gezeigt, dass eine Verringerung der Genauigkeit der Parameter oft nicht zu einem deutlichen Verlust an Modellleistung führt, insbesondere wenn das Modell groß genug ist und ausreichend Daten zum Trainieren hat. Diese Fähigkeit, ermöglicht es, Modelle auf Hardware mit begrenztem Speicher-Ressourcen auszuführen, was die Skalierbarkeit und Einsatzmöglichkeiten erheblich verbessert.
Speicher analysieren
Manchmal kann es vorkommen, dass man das LLM bereits im Speicher hat und schon damit arbeitet und irgendwann passiert es dann doch. CUDA out of memory. Solche oder ähnliche Beispiele findet man zuhauf im Netz. Hier eine kleine Auswahl.
How to free GPU memory in PyTorch
https://stackoverflow.com/questions/70508960/how-to-free-gpu-memory-in-pytorch%20How%20to%20free%20GPU%20memory%20in%20PyTorch
CLIP not releasing GPU memory after each inference batch
https://github.com/huggingface/transformers/issues/20636?utm_source=pocket_saves
How to delete a Tensor in GPU to free up memory
https://discuss.pytorch.org/t/how-to-delete-a-tensor-in-gpu-to-free-up-memory/48879?utm_source=pocket_saves
How to remove the model of transformers in GPU memory
https://stackoverflow.com/questions/69357881/how-to-remove-the-model-of-transformers-in-gpu-memory?utm_source=pocket_reader
CUDA Out Of Memory Error on consecutive inferences
https://github.com/voicepaw/so-vits-svc-fork/issues/476?utm_source=pocket_saves
CUDA out of memory while doing inference in a loop
https://discuss.huggingface.co/t/cuda-out-of-memory-while-doing-inference-in-a-loop/61401?utm_source=pocket_reader
GPU memory not being freed between batches
https://discuss.huggingface.co/t/gpu-memory-not-being-freed-between-batches/19567?utm_source=pocket_reader
Solche Fehler rühren oft daher, dass der GPU-RAM schon ziemlich voll ist und dann in einer Schliefe die forward Methode des Modelles ausgeführt wird. Das Ergebnis wird in einer Variable gespeichert und der nächste Loop wird gestartet, ohne die Variablen aus dem Speicher zu löschen. Pytorch versucht dann wieder ein Stück Speicher zu bekommen, aber der ist noch belegt und der Garbage Collector kann sie nicht aufräumen, da die Werte noch in der Variable aus dem letzten Loop stehen und schon ist es geschehen. Manchmal passiert es nach dem ersten Loop manchmal auch erst nach dem 200sten – je nachdem wie knapp der Speicher ist.
Mit den folgenden Methoden kann man sich in Pytorch einen groben Überblick über das Geschehen im GPU RAM verschaffen.
# Gibt den aktuell von Tensoren belegten GPU-Speicher in Bytes zurück.
torch.cuda.memory_allocated()
# Gibt den aktuellen, vom Caching Allocator verwalteten GPU-Speicher in Bytes zurück.
torch.cuda.memory_reserved()
# Gibt die aktuelle Speicherzuweisungsstatistik als Tabelle zurück
# Dies kann nützlich sein, um sie regelmäßig während des Trainings oder
# bei der Behandlung von "Out-of-Memory"-Ausnahmen anzuzeigen.
torch.cuda.memory_summary()
Die beiden Methoden memory_allocated und memory_reserved sehen auf den ersten Blick recht ähnlich aus und liefern meistens auch recht ähnliche Werte zurück, aber es gibt einige Unterschiede zwischen den beiden Funktionen. Diese Methode torch.cuda.memory_allocated() gibt die aktuelle Menge des von PyTorch allokierten Speichers auf der GPU zurück. Sie zeigt den exakten Speicherbedarf für alle von PyTorch verwalteten Tensoren an, die auf der GPU gehalten werden.
Im Gegensatz dazu gibt die Methode torch.cuda.memory_reserved() die Gesamtmenge des von PyTorch reservierten Speichers auf der GPU zurück. Sie zeigt an, wie viel Speicher PyTorch insgesamt für die Verwendung auf der GPU reserviert hat, einschließlich des Speichers, der möglicherweise noch nicht von Tensorobjekten belegt wurde. Dieser Wert umfasst den Speicher, der sowohl für Tensoren als auch für andere interne PyTorch-Operationen reserviert wurde.
Die Methode memory_summary gibt einen String zurück, der mit print ausgegeben werden kann und wir folgt aussieht:
|===========================================================================| | PyTorch CUDA memory summary, device ID 0 | |---------------------------------------------------------------------------| | CUDA OOMs: 1 | cudaMalloc retries: 1 | |===========================================================================| | Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed | |---------------------------------------------------------------------------| | Allocated memory | 7630 MiB | 11444 MiB | 19074 MiB | 11444 MiB | | from large pool | 7630 MiB | 11444 MiB | 19074 MiB | 11444 MiB | | from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB | |---------------------------------------------------------------------------| | Active memory | 7630 MiB | 11444 MiB | 19074 MiB | 11444 MiB | | from large pool | 7630 MiB | 11444 MiB | 19074 MiB | 11444 MiB | | from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB | |---------------------------------------------------------------------------| | Requested memory | 7629 MiB | 11444 MiB | 19073 MiB | 11444 MiB | | from large pool | 7629 MiB | 11444 MiB | 19073 MiB | 11444 MiB | | from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB | |---------------------------------------------------------------------------| | GPU reserved memory | 7632 MiB | 11446 MiB | 19078 MiB | 11446 MiB | | from large pool | 7632 MiB | 11446 MiB | 19078 MiB | 11446 MiB | | from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB | |---------------------------------------------------------------------------| | Non-releasable memory | 2001 KiB | 2001 KiB | 3955 KiB | 1954 KiB | | from large pool | 2001 KiB | 2001 KiB | 3955 KiB | 1954 KiB | | from small pool | 0 KiB | 0 KiB | 0 KiB | 0 KiB | |---------------------------------------------------------------------------| | Allocations | 2 | 2 | 3 | 1 | | from large pool | 2 | 2 | 3 | 1 | | from small pool | 0 | 0 | 0 | 0 | |---------------------------------------------------------------------------| | Active allocs | 2 | 2 | 3 | 1 | | from large pool | 2 | 2 | 3 | 1 | | from small pool | 0 | 0 | 0 | 0 | |---------------------------------------------------------------------------| | GPU reserved segments | 2 | 2 | 3 | 1 | | from large pool | 2 | 2 | 3 | 1 | | from small pool | 0 | 0 | 0 | 0 | |---------------------------------------------------------------------------| | Non-releasable allocs | 1 | 1 | 2 | 1 | | from large pool | 1 | 1 | 2 | 1 | | from small pool | 0 | 0 | 0 | 0 | |---------------------------------------------------------------------------| | Oversize allocations | 0 | 0 | 0 | 0 | |---------------------------------------------------------------------------| | Oversize GPU segments | 0 | 0 | 0 | 0 | |===========================================================================|
Diese detaillierte Zusammenfassung des Speichers auf der GPU enthält Informationen über die aktuelle Belegung des GPU-Speichers sowie Details zu den verschiedenen Speicherbereichen, die von PyTorch verwendet werden. Die genaue Struktur und der Inhalt der Ausgabe können je nach Version von PyTorch und der spezifischen Konfiguration des Systems variieren, aber typischerweise umfasst sie Informationen über die Gesamtmenge des verfügbaren GPU-Speichers sowie die aktuelle Belegung, eine Tabelle, die die Zuordnung von Speicherbereichen auf der GPU auflistet. Diese kann Details über verschiedene Speichertypen wie reservierten Speicher, belegten Speicher für Tensorobjekte etc. enthalten. Diese Tabelle gibt normalerweise die Belegung von Speicher in Byte, Kilobyte oder Megabyte an. Informationen darüber, wie viel Speicher von PyTorch insgesamt auf der GPU reserviert wurde. Eine Zusammenfassung der aktuellen Speicherbelegung durch Tensorobjekte und andere Ressourcen.
In den meisten Fällen werden zusätzliche Details oder Metriken über die Speicherbelegung und -nutzung aufgeführt, je nach Implementierung und Konfiguration.
Mit diesen Informationen kommt man meistens schon recht weit, wenn man mit Speicherproblemen in einer PyTorch Anwendung zu kämpfen hat. Aber man kann sich von PyTorch noch mehr Informationen zum GPU-Speicher ausgeben lassen.
Das PyTorch Memory Snapshot Tool
Das PyTorch Memory Snapshot Tool ist ein sehr nützliches Werkzeug, das Entwicklern beim Debuggen und Optimieren ihrer PyTorch-Anwendungen bei Problemen im Zusammenhang mit der Speichernutzung auf der GPU helfen kann. Es liefert Funktionen zum Aufzeichnen, Abspeichern und Analysieren des GPU-Speicherverbrauchs während der Ausführung von PyTorch-Programmen.
Die Funktionen zum Aufzeichnen des GPU-Speicherverbrauchs während der Ausführung ist recht einfach und in torch.cuda.memory verfügbar:
torch.cuda.memory._record_memory_history(max_entries=100000):Diese Funktion aktiviert die Aufzeichnung des Speicherverlaufs auf der GPU. Der Parameter max_entries gibt die maximale Anzahl von Einträgen im Speicherhistorie-Datensatz an, der standardmäßig auf 100.000 gesetzt ist. Durch das Aktivieren dieser Funktion zeichnet PyTorch den Verlauf der Speichernutzung auf der GPU auf, einschließlich aller Zuweisungen, Freigaben und Änderungen.
Mit der Funktion torch.cuda.memory._dump_snapshot(file_name) kann der Snapshot des aktuellen GPU-Speicherzustands in eine Datei geschrieben werden. Der file_name-Parameter gibt den Dateinamen an, in den der Speicher-Snapshot geschrieben werden soll. Mit dem Speicher-Snapshot kann man den genauen Zustand des GPU-Speichers zu einem bestimmten Zeitpunkt zu erfassen, was beim Debuggen und Analysieren von Speicherproblemen hilfreich ist. Einen so erstellten Snapshot kann man dann auf https://pytorch.org/memory_viz hochladen um sich die Aufzeichnung des Speicherverlaufs anzeigen zu lassen.
Mit der Funktion torch.cuda.memory._record_memory_history(enabled) aktiviert oder deaktiviert die Aufzeichnung des Speicherhistorie. Wird enabled auf True gesetzt ist, wird die Speicherhistorie aktiviert. Wird enabled auf False gesetzt ist, wird die Speicherhistorie deaktiviert. Mit dieser Funktion kann die Aufzeichnung des Speicherhistorie dynamisch während der Laufzeit gesteuert werden. Zusammen ermöglichen diese Funktionen des PyTorch Memory Snapshot Tools Entwicklern eine detaillierte Analyse des GPU-Speicherverbrauchs ihrer PyTorch-Anwendungen, was dabei helfen kann, Speicherlecks zu erkennen.
Beispiel
Das folgende Beispiel führt eine Schleife aus, in der Tensorobjekte auf der GPU erstellt werden, und erfasst dann einen Speicher-Snapshot nach Abschluss der Schleife.
torch.cuda.memory._record_memory_history(max_entries=100000)
for _ in range(200):
x = torch.zeros(100000, dtype=torch.float32, device='cuda')
try:
torch.cuda.memory._dump_snapshot("test.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
torch.cuda.memory._record_memory_history(enabled=False)
Die hier erstellte test.pickle sieht dann im PyTorch Memory Profiler Tool unter https://pytorch.org/memory_viz wie folgt aus:

Jede dieser Spitzen entspricht einem Pytorch Aufruf. In dem Beispiel ist das die Funktion „x = torch.zeros(100000, dtype=torch.float32, device=’cuda‘)“. Diese Funktion allokiert den Speicher für 100000 Float32 Werte im GPU-RAM. Das entspricht einem Speicherbedarf von 100.000 * 4 = 400.000 Bytes. Trotzdem werden hier bis zu 800.000 Byte GPU-RAM benötigt. Das liegt daran, dass der Speicher, den die Variable x benötigt erst freigegeben werden kann, wenn x wieder neu belegt wird.
Wandelt man das Beispiel ein wenig ab und räumt am Ende der Schleife die Variable x auf, reduziert sich der Speicherbedarf drastisch.
# Start recording memory snapshot history, initialized with a buffer
# capacity of 100,000 memory events, via the `max_entries` field.
torch.cuda.memory._record_memory_history(max_entries=100000)
# Run your PyTorch Model.
# At any point in time, save a snapshot to file for later.
for _ in range(200):
x = torch.zeros(100000, dtype=torch.float32, device='cuda')
x.detach()
del x
gc.collect()
torch.cuda.empty_cache()
try:
torch.cuda.memory._dump_snapshot("test2.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
torch.cuda.memory._record_memory_history(enabled=False)

Wie man sieht, benötigt das PyTorch Programm nun nur noch 400kB GPU RAM was den Speicherbedarf halbiert hat. Eine so kleine Änderung kann also schon dramatische Auswirkungen auf den Speicherbedarf von PyTorch Ausführungen haben. Natürlich ist eine Halbierung in einer echten PyTorch KI-Anwendung nicht möglich, da der Großteil des Speichers von dem Model benötigt wird und nur die Daten der letzten Inference in einer Schleife gelöscht werden können. Aber das kann auch schon eine Menge bringen, vor allem wenn man einen sehr großen Context verwendet oder mit einem hohen num_beams Parameter arbeitet.
Neben dieser grafisch aufbereiteten Anzeige der Daten kann das PyTorch Memory Profiler Tool aber noch mehr. So zeigt es detailliert alle Informationen zu jedem PyTorch Aufruf an, wenn man mit der Maus darüberfährt.
Beispiel:
0 Addr: b7a15a3200000_0, Size: 390.6KiB (400000 bytes) allocation, Total memory used after allocation: 390.6KiB (400000 bytes) CUDACachingAllocator.cpp:0:c10::cuda::CUDACachingAllocator::Native::DeviceCachingAllocator::malloc(int, unsigned long, CUstream_st*) :0:c10::cuda::CUDACachingAllocator::Native::NativeCachingAllocator::malloc(void**, int, unsigned long, CUstream_st*) :0:c10::cuda::CUDACachingAllocator::Native::NativeCachingAllocator::allocate(unsigned long) const :0:at::TensorBase at::detail::_empty_generic<long>(c10::ArrayRef<long>, c10::Allocator*, c10::DispatchKeySet, c10::ScalarType, c10::optional<c10::MemoryFormat>) ??:0:at::detail::empty_generic(c10::ArrayRef<long>, c10::Allocator*, c10::DispatchKeySet, c10::ScalarType, c10::optional<c10::MemoryFormat>) ??:0:at::detail::empty_cuda(c10::ArrayRef<long>, c10::ScalarType, c10::optional<c10::Device>, c10::optional<c10::MemoryFormat>) ??:0:at::detail::empty_cuda(c10::ArrayRef<long>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) ??:0:at::native::empty_cuda(c10::ArrayRef<long>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) RegisterCUDA.cpp:0:at::(anonymous namespace)::(anonymous namespace)::wrapper_CUDA_memory_format_empty(c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) RegisterCUDA.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>), &at::(anonymous namespace)::(anonymous namespace)::wrapper_CUDA_memory_format_empty>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) ??:0:at::_ops::empty_memory_format::redispatch(c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) RegisterBackendSelect.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>), &at::(anonymous namespace)::empty_memory_format>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) ??:0:at::_ops::empty_memory_format::call(c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) ??:0:at::native::zeros_symint(c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) RegisterCompositeExplicitAutograd.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>), &at::(anonymous namespace)::(anonymous namespace)::wrapper_CompositeExplicitAutograd__zeros>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ??:0:at::_ops::zeros::redispatch(c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) RegisterBackendSelect.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>), &at::(anonymous namespace)::zeros>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ??:0:at::_ops::zeros::call(c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) python_torch_functions_0.cpp:0:torch::autograd::THPVariable_zeros(_object*, _object*, _object*) <ipython-input-4-1edc878950a9>:8:<cell line: 7> ??:0:_PyArg_ParseTuple_SizeT ??:0:PyFrozenSet_New ??:0:PyCell_New /usr/local/lib/python3.10/dist-packages/IPython/core/interactiveshell.py:3553:run_code /usr/local/lib/python3.10/dist-packages/IPython/core/interactiveshell.py:3473:run_ast_nodes /usr/local/lib/python3.10/dist-packages/IPython/core/interactiveshell.py:3257:run_cell_async ??:0:_PyUnicode_IsWhitespace /usr/local/lib/python3.10/dist-packages/IPython/core/async_helpers.py:78:_pseudo_sync_runner /usr/local/lib/python3.10/dist-packages/IPython/core/interactiveshell.py:3030:_run_cell /usr/local/lib/python3.10/dist-packages/IPython/core/interactiveshell.py:2975:run_cell ??:0:PyMethod_New /usr/local/lib/python3.10/dist-packages/ipykernel/zmqshell.py:539:run_cell ??:0:PyMethod_New /usr/local/lib/python3.10/dist-packages/ipykernel/ipkernel.py:302:do_execute ??:0:_PyUnicode_ToDecimalDigit ??:0:PyCell_New ??:0:_PyDict_NewPresized /usr/local/lib/python3.10/dist-packages/tornado/gen.py:234:wrapper /usr/local/lib/python3.10/dist-packages/ipykernel/kernelbase.py:539:execute_request ??:0:_PyUnicode_ToDecimalDigit ??:0:PyCell_New ??:0:_PyDict_NewPresized /usr/local/lib/python3.10/dist-packages/tornado/gen.py:234:wrapper ??:0:PyMethod_New /usr/local/lib/python3.10/dist-packages/ipykernel/kernelbase.py:261:dispatch_shell ??:0:_PyUnicode_ToDecimalDigit ??:0:PyCell_New ??:0:_PyDict_NewPresized /usr/local/lib/python3.10/dist-packages/tornado/gen.py:234:wrapper ??:0:PyMethod_New /usr/local/lib/python3.10/dist-packages/ipykernel/kernelbase.py:361:process_one ??:0:_PyUnicode_IsWhitespace /usr/local/lib/python3.10/dist-packages/tornado/gen.py:786:run ??:0:PyMethod_New ??:0:_PyDict_NewPresized /usr/local/lib/python3.10/dist-packages/tornado/gen.py:825:inner ??:0:_PyType_LookupId /usr/local/lib/python3.10/dist-packages/tornado/ioloop.py:738:_run_callback /usr/local/lib/python3.10/dist-packages/tornado/ioloop.py:685:<lambda> ??:0:_PyDict_NewPresized /usr/lib/python3.10/asyncio/events.py:80:_run /usr/lib/python3.10/asyncio/base_events.py:1909:_run_once /usr/lib/python3.10/asyncio/base_events.py:603:run_forever /usr/local/lib/python3.10/dist-packages/tornado/platform/asyncio.py:195:start /usr/local/lib/python3.10/dist-packages/ipykernel/kernelapp.py:619:start /usr/local/lib/python3.10/dist-packages/traitlets/config/application.py:992:launch_instance ??:0:PyMethod_New /usr/local/lib/python3.10/dist-packages/colab_kernel_launcher.py:37:<module> ??:0:_PyArg_ParseTuple_SizeT ??:0:PyFrozenSet_New ??:0:PyCell_New /usr/lib/python3.10/runpy.py:86:_run_code /usr/lib/python3.10/runpy.py:196:_run_module_as_main ??:0:PyRun_StringFlags ??:0:Py_RunMain ??:0:Py_BytesMain ??:0:__libc_init_first
Normalerweise muss man nicht so weit ins Detail gehen, ausser man ist PyTorch Entwickler und sucht nach einem Bug. Ich habe dort jedenfalls noch nie etwas gefunden, was mir weitergeholfen hätte.
Weitere Details und Beispiele kann man unter https://pytorch.org/blog/understanding-gpu-memory-1/ finden. Dort wird das PyTorch Memory Profiler Tool detailliert beschrieben.
Weitere Tipps
Verwendet man die Huggingface Transformer Bibliothek, hat man noch eine andere Möglichkeiten, die Ausführung von Modellen weiter zu optimieren. Mit der Methode model.eval() kann der Trainingsmodus eines Modells Deaktiviert werden. Das bedeutet, dass alle Schichten im Modell auf Inferenz umgestellt werden. Im Trainingsmodus werden beispielsweise Dropout-Schichten aktiviert, um Overfitting zu verhindern. Auch andere Teile des Modells verhalten sich im Trainingsmodus anders als im Inferenz-Modus. Unter anderem werden auch Batch-Normalisierungs- und Layer-Normalisierungs-Layer anders behandelt. Im Trainingsmodus werden auch viele zusätzliche Informationen wie Gradienten und Aktivierungen für das Backpropagation-Verfahren berechnet und im GPU-RAM gespeichert. Im Inferenz-Modus werden diese nicht benötigt und der Speicher für die Variablen kann woanders besser verwendet werden. Das berechnen der Gradienten kann z.B. auch mit der PyTorch Methode torch.no_grad() verhindert werden.
torch.cuda.set_per_process_memory_fraction
Man kann die Methode torch.cuda.set_per_process_memory_fraction(0.5, 0) dazu nutzen, um GPU-RAM-Limitierungen zu testen. Die Funktion ermöglicht es, den Speicheranteil der GPU für einen Prozess zu limitieren. Die Methode hat 2 Parameter. Der erste Parameter gibt an, wie groß der Anteil des nutzbaren GPU-RAM ist und der zweite Parameter die Nummer der CUDA GPU. Mit dem ersten Parameter kann man den maximalen Speicher auf einem CUDA-Gerät begrenzen. Die erlaubte Speichermenge entspricht dem gesamten sichtbaren Speicher, multipliziert mit dem angegebenen Bruchteil. Der Wert muss zwischen 0 und 1 liegen und er erlaubte Speicher entspricht dann „total_memory * fraction“. Versucht das PyTorch Programm mehr Speicher als den erlaubten Wert in einem Prozess zuzuweisen, wird ein Out-of-Memory-Fehler im Allocator ausgelöst. Wenn man den Speicherbedarf eine PyTorch Anwendung unter bestimmten Bedingungen testen möchte, kann man die Methode torch.cuda.set_per_process_memory_fraction(0.5, 0) verwenden, um den Anteil des verfügbaren GPU-Speichers, der von einem PyTorch Thread verwendet werden kann um den „CUDA out of memory“ zu forcieren.
Der erste Parameter (0.5) gibt den Anteil des verfügbaren Speichers an, den der Prozess verwenden kann. In diesem Fall wird der Anteil auf 50% gesetzt. Der zweite Parameter (0) ist die ID des Geräts (GPU). Bei Systemen mit mehreren GPUs kann dieser Parameter verwendet werden, um das Speicherlimit für eine bestimmte GPU festzulegen.
model.get_memory_footprint
Die Funktion model.get_memory_footprint() ist eine praktische Methode, um den Speicherbedarf des Modells zu ermitteln. Diese Funktion wird verwendet, um Informationen darüber zu erhalten, wie viel Speicher das Modell während seiner Ausführung (Inference) benötigt. Das Ergebnis dieser Funktion ist eine Zahl, die den Speicherbedarf des Modells in Byte angibt.
Die Information, die durch model.get_memory_footprint() bereitgestellt wird, kann dazu verwendet werden, um zu prüfen, ob das Modell effizient auf verschiedenen Plattformen ausgeführt werden kann, insbesondere wenn es auf Ressourcenbeschränkten Systemen wie mobilen Geräten oder eingebetteten Systemen eingesetzt werden soll. Durch die Analyse des Speicherbedarfs können Optimierungen vorgenommen werden, um die Leistung und Effizienz des Modells zu verbessern.
Unter https://gist.github.com/msoftware/005f7303e1d1b94099403bed645844e9 habe ich ein Google Colab Notebook abgelegt, mit dem man die oben angesprochenen Beispiele ausführen und damit herumprobieren kann.

import torch
import gc
Die Funktion torch.cuda.set_per_process_memory_fraction() ist Teil des PyTorch-Frameworks und wird verwendet, um die Menge des auf einer CUDA-fähigen GPU verfügbaren Arbeitsspeichers anzupassen, der von einem einzelnen Prozess verwendet werden kann. Hier ist eine Beschreibung der Parameter und der Funktionsweise der Funktion:
set_per_process_memory_fraction(fraction, device_id): Diese Funktion ermöglicht es, den Anteil des verfügbaren GPU-Speichers anzugeben, der von einem einzelnen Prozess verwendet werden soll.
fraction: Dieser Parameter ist ein Fließkommawert zwischen 0 und 1, der den Anteil des verfügbaren GPU-Speichers darstellt, den der Prozess verwenden soll. Ein Wert von 1.0 würde bedeuten, dass der Prozess den gesamten verfügbaren GPU-Speicher verwenden kann, während ein Wert von 0.5 bedeuten würde, dass der Prozess die Hälfte des verfügbaren Speichers verwenden kann.
device_id: Dieser Parameter ist optional und gibt die ID der CUDA-GPU an, für die die Speicherzuweisung festgelegt werden soll. Wenn dieser Parameter nicht angegeben wird, wird die Standard-GPU verwendet.
Die Funktion ist hilfreich, um die Ressourcennutzung auf einer GPU zu steuern und sicherzustellen, dass verschiedene Prozesse den verfügbaren Speicher effizient nutzen können, insbesondere wenn mehrere Prozesse auf derselben GPU ausgeführt werden sollen. In dem oben genannten Beispiel wird der Prozess angewiesen, die gesamte verfügbare GPU-Speicherressource zu verwenden, da der fraction-Parameter auf 1.0 gesetzt ist und device_id auf 0 (Standard-GPU) gesetzt ist.
torch.cuda.set_per_process_memory_fraction(1.0, 0)
print(torch.cuda.memory_allocated() / 1024**2)
print(torch.cuda.memory_reserved()/ 1024**2)
print(torch.cuda.memory_summary())
0.0
0.0
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| Active memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| Requested memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| GPU reserved memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| Allocations | 0 | 0 | 0 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Active allocs | 0 | 0 | 0 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 0 | 0 | 0 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 0 | 0 | 0 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
a = torch.zeros(1000000000, dtype=torch.float16, device='cuda')
b = torch.zeros(1000000000, dtype=torch.float16, device='cuda')
print(torch.cuda.memory_allocated() / 1024**2)
print(torch.cuda.memory_reserved()/ 1024**2)
print(torch.cuda.memory_summary())
3816.0
3816.0
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from large pool | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| Active memory | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from large pool | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| Requested memory | 3814 MiB | 3814 MiB | 3814 MiB | 0 B |
| from large pool | 3814 MiB | 3814 MiB | 3814 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| GPU reserved memory | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from large pool | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| Allocations | 2 | 2 | 2 | 0 |
| from large pool | 2 | 2 | 2 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Active allocs | 2 | 2 | 2 | 0 |
| from large pool | 2 | 2 | 2 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 2 | 2 | 2 | 0 |
| from large pool | 2 | 2 | 2 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 0 | 0 | 0 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
a.detach()
del a
gc.collect()
torch.cuda.empty_cache()
torch.cuda.synchronize()
print(torch.cuda.memory_allocated() / 1024**2)
print(torch.cuda.memory_reserved()/ 1024**2)
print(torch.cuda.memory_summary())
3816.0
3816.0
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from large pool | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| Active memory | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from large pool | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| Requested memory | 3814 MiB | 3814 MiB | 3814 MiB | 0 B |
| from large pool | 3814 MiB | 3814 MiB | 3814 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| GPU reserved memory | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from large pool | 3816 MiB | 3816 MiB | 3816 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| Allocations | 2 | 2 | 2 | 0 |
| from large pool | 2 | 2 | 2 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Active allocs | 2 | 2 | 2 | 0 |
| from large pool | 2 | 2 | 2 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 2 | 2 | 2 | 0 |
| from large pool | 2 | 2 | 2 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 0 | 0 | 0 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
b.detach()
del b
gc.collect()
torch.cuda.empty_cache()
torch.cuda.synchronize()
print(torch.cuda.memory_allocated() / 1024**2)
print(torch.cuda.memory_reserved()/ 1024**2)
print(torch.cuda.memory_summary())
1908.0
1908.0
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 1908 MiB | 3816 MiB | 3816 MiB | 1908 MiB |
| from large pool | 1908 MiB | 3816 MiB | 3816 MiB | 1908 MiB |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB |
|---------------------------------------------------------------------------|
| Active memory | 1908 MiB | 3816 MiB | 3816 MiB | 1908 MiB |
| from large pool | 1908 MiB | 3816 MiB | 3816 MiB | 1908 MiB |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB |
|---------------------------------------------------------------------------|
| Requested memory | 1907 MiB | 3814 MiB | 3814 MiB | 1907 MiB |
| from large pool | 1907 MiB | 3814 MiB | 3814 MiB | 1907 MiB |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB |
|---------------------------------------------------------------------------|
| GPU reserved memory | 1908 MiB | 3816 MiB | 3816 MiB | 1908 MiB |
| from large pool | 1908 MiB | 3816 MiB | 3816 MiB | 1908 MiB |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 MiB |
|---------------------------------------------------------------------------|
| Non-releasable memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
| Allocations | 1 | 2 | 2 | 1 |
| from large pool | 1 | 2 | 2 | 1 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Active allocs | 1 | 2 | 2 | 1 |
| from large pool | 1 | 2 | 2 | 1 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 1 | 2 | 2 | 1 |
| from large pool | 1 | 2 | 2 | 1 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 0 | 0 | 0 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
# Start recording memory snapshot history, initialized with a buffer
# capacity of 100,000 memory events, via the `max_entries` field.
torch.cuda.memory._record_memory_history(max_entries=100000)
# Run your PyTorch Model.
# At any point in time, save a snapshot to file for later.
for _ in range(200):
x = torch.zeros(100000, dtype=torch.float32, device='cuda')
x.detach()
del x
gc.collect()
torch.cuda.empty_cache()
# x.detach()
# del x
# In this sample, we save the snapshot after running 5 iterations.
# - Save as many snapshots as you'd like.
# - Snapshots will save last `max_entries` number of memory events
# (100,000 in this example).
try:
torch.cuda.memory._dump_snapshot("test2.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
# Stop recording memory snapshot history.
torch.cuda.memory._record_memory_history(enabled=False)
print(torch.cuda.memory_allocated() / 1024**2)
print(torch.cuda.memory_reserved()/ 1024**2)
print(torch.cuda.memory_summary())
0.0
0.0
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 0 B | 3816 MiB | 3892 MiB | 3892 MiB |
| from large pool | 0 B | 3816 MiB | 3816 MiB | 3816 MiB |
| from small pool | 0 B | 0 MiB | 76 MiB | 76 MiB |
|---------------------------------------------------------------------------|
| Active memory | 0 B | 3816 MiB | 3892 MiB | 3892 MiB |
| from large pool | 0 B | 3816 MiB | 3816 MiB | 3816 MiB |
| from small pool | 0 B | 0 MiB | 76 MiB | 76 MiB |
|---------------------------------------------------------------------------|
| Requested memory | 0 B | 3814 MiB | 3890 MiB | 3890 MiB |
| from large pool | 0 B | 3814 MiB | 3814 MiB | 3814 MiB |
| from small pool | 0 B | 0 MiB | 76 MiB | 76 MiB |
|---------------------------------------------------------------------------|
| GPU reserved memory | 0 B | 3816 MiB | 4216 MiB | 4216 MiB |
| from large pool | 0 B | 3816 MiB | 3816 MiB | 3816 MiB |
| from small pool | 0 B | 2 MiB | 400 MiB | 400 MiB |
|---------------------------------------------------------------------------|
| Non-releasable memory | 0 B | 1657 KiB | 331400 KiB | 331400 KiB |
| from large pool | 0 B | 0 KiB | 0 KiB | 0 KiB |
| from small pool | 0 B | 1657 KiB | 331400 KiB | 331400 KiB |
|---------------------------------------------------------------------------|
| Allocations | 0 | 2 | 202 | 202 |
| from large pool | 0 | 2 | 2 | 2 |
| from small pool | 0 | 1 | 200 | 200 |
|---------------------------------------------------------------------------|
| Active allocs | 0 | 2 | 202 | 202 |
| from large pool | 0 | 2 | 2 | 2 |
| from small pool | 0 | 1 | 200 | 200 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 0 | 2 | 202 | 202 |
| from large pool | 0 | 2 | 2 | 2 |
| from small pool | 0 | 1 | 200 | 200 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 0 | 1 | 200 | 200 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 0 | 1 | 200 | 200 |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
from transformers import AutoModel
model = AutoModel.from_pretrained("VAGOsolutions/SauerkrautLM-Gemma-2b")
/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_token.py:88: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
config.json: 0%| | 0.00/685 [00:00<?, ?B/s]
model.safetensors.index.json: 0%| | 0.00/13.5k [00:00<?, ?B/s]
Downloading shards: 0%| | 0/2 [00:00<?, ?it/s]
model-00001-of-00002.safetensors: 0%| | 0.00/4.95G [00:00<?, ?B/s]
model-00002-of-00002.safetensors: 0%| | 0.00/67.1M [00:00<?, ?B/s]
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
print(f"Memory footprint: {model.get_memory_footprint() / 1e6:.2f} MB")
Memory footprint: 10091.80 MB