
In diesem Blogpost teste ich, wie man den neuen VECTOR-Datentyp in MariaDB 11 verwendet. Wie wird er definiert? Wie speichert MariaDB die Daten? Welche Abfragen sind möglich – und wo liegen die aktuellen Grenzen? Ziel ist es, ein Bild davon zu bekommen, ob sich MariaDB mit VECTOR als Backend für moderne KI- und RAG-Szenarien eignet oder ob man weiterhin auf spezialisierte Vektordatenbanken setzen sollte. In der Vergangenheit habe ich meistens Qdrant oder ChromaDB verwendet und musste dann immer 2 Datenbank-Verbindungen in der App managen. Eine SQL Datenbank und eine Vector-Datenbank. Mit dem Datentyp VECTOR in MariaDB könnte das ein Ende haben.
Datenbank erstellen und Benutzerrechte vergeben
Der erste Schritt ist die Erstellung der Datenbank selbst. In meinem Test nenne ich sie test_database. Man kann aber einen beliebigen Namen wählen, der zu deinem Projekt passt.
Dazu melde ich mich zunächst als Root-Benutzer bei MariaDB an:
mysql -u root -pNach Eingabe des Passworts befindet man sich in MariaDB. Dort kann man mit dem folgenden Befehl eine neue Datenbank anlegen:
CREATE DATABASE test_database;Es ist eine bewährte Sicherheitspraxis, nicht den Root-Benutzer für alltägliche Datenbankoperationen zu verwenden. Stattdessen verwende ich den Benutzer user und gewähren ihm die notwendigen Rechte für die neue Datenbank.
GRANT ALL PRIVILEGES ON test_database.* TO 'user'@'localhost';Damit MariaDB die neuen Berechtigungen anwendet muss die Privilegien-Tabelle neu geladen werden. Dies geschieht mit dem Befehl:
FLUSH PRIVILEGES;Damit ist die Datenbank angelegt und der Benutzer „user“ hat alle Rechte und man kann sich aus MariaDB ausloggen.
EXIT;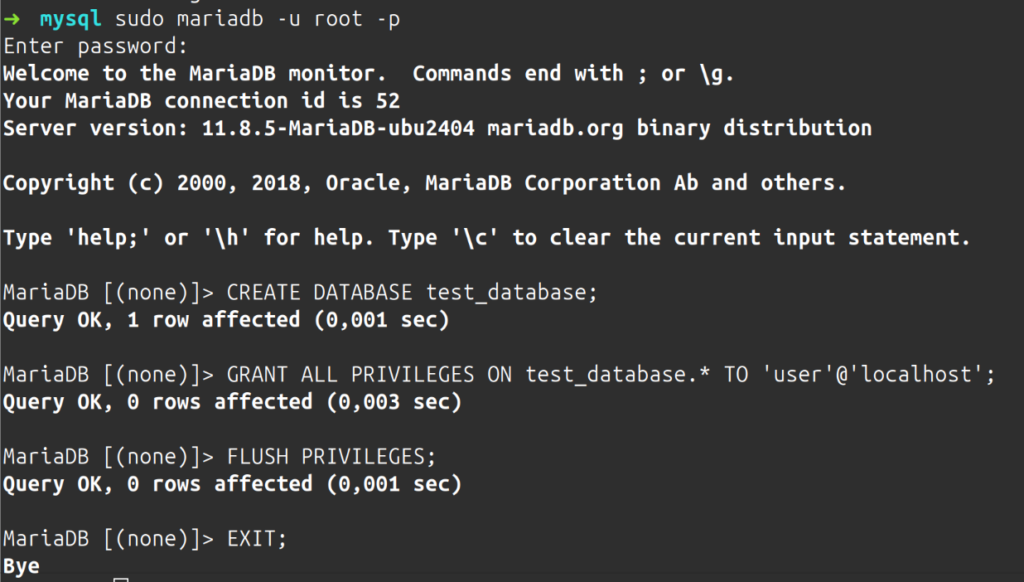
Embedding-Tabelle erstellen
Der VECTOR-Datentyp in MariaDB ist gut für Anwendungen, die auf künstlicher Intelligenz und maschinellem Lernen basieren, geeignet. Traditionelle relationale Datenbanken sind nicht optimal dafür ausgelegt, hochdimensionale Vektoren effizient zu speichern und vor allem schnell nach Ähnlichkeit zu durchsuchen (Vektorähnlichkeitssuche). Die native Unterstützung des VECTOR-Datentyps bringt viele Vorteile. Vektoren werden in einem optimierten Format gespeichert. MariaDB kann spezielle Indizes verwenden, um Vektoren zu finden, die einem gegebenen Abfragevektor am ähnlichsten sind. Die Möglichkeit, Vektoren nativ und effizient in einer relationalen Datenbank zu verwalten, vereinfacht die Architektur vieler KI-gestützter Anwendungen erheblich und integriert die Vektordaten nahtlos in bestehende Datenmodelle.
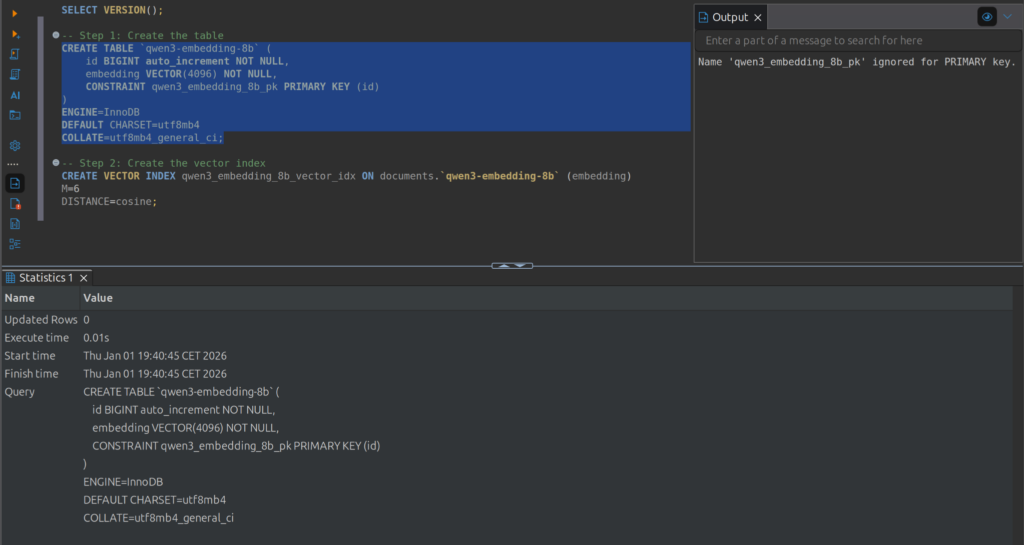
Nachdem die Datenbank (test_database) angelegt und der Benutzer die notwendigen Rechten hat, ist der nächste Schritt die Erstellung der Tabelle, in der die Daten gespeichert werden. Ich erstelle eine Tabelle mit dem Namen qwen3-embedding-8b, um die Embeddings zu speichern, die von einem entsprechenden Modell erzeugt werden. Hier ist der SQL-Befehl:
CREATE TABLE `qwen3-embedding-8b` (
id BIGINT auto_increment NOT NULL,
embedding VECTOR(4096) NOT NULL,
CONSTRAINT qwen3_embedding_8b_pk PRIMARY KEY (id)
)
ENGINE=InnoDB
DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_general_ci;Nachdem der Befehl ausgeführt wurde, erhält man eine Bestätigung, dass die Tabelle erfolgreich erstellt wurde.
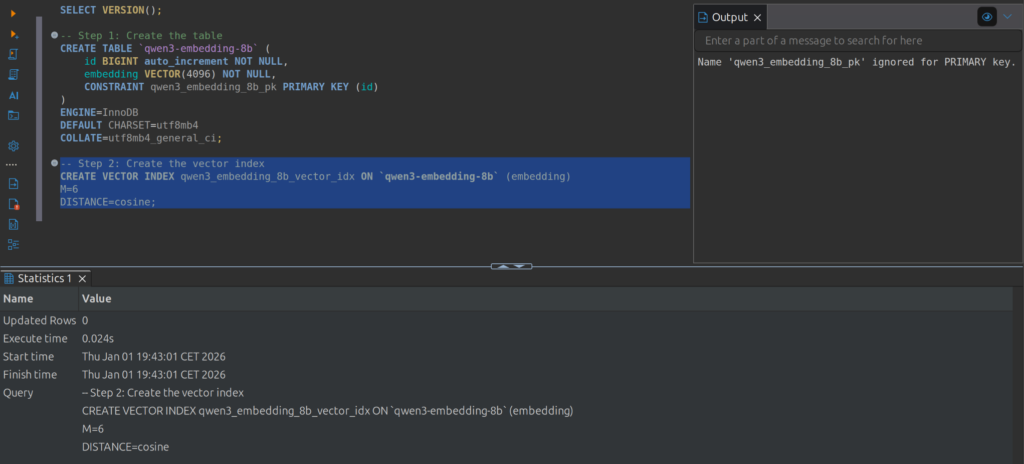
Der Vektor-Index zur effizienten Ähnlichkeitssuche
Nachdem die Tabelle qwen3-embedding-8b mit der VECTOR-Spalte angelegt wurde wird ein spezieller Index für die effiziente Suche in diesen hochdimensionalen Vektoren erstellt. Ohne einen solchen Index ist die Suche nach ähnlichen Vektoren eine langwierige Angelegenheit, da MariaDB jeden Vektor einzeln vergleichen müsste. Hier kommt der VECTOR INDEX ins Spiel, der die Vektorähnlichkeitssuche dramatisch beschleunigt.
CREATE VECTOR INDEX qwen3_embedding_8b_vector_idx ON `qwen3-embedding-8b` (embedding)
M=6
DISTANCE=cosine;Dies ist der Befehl zur Erstellung des Vektor-Index. qwen3_embedding_8b_vector_idx ist der Name des Index. ON qwen3-embedding-8b (embedding) spezifiziert, dass der Index auf der Tabelle qwen3-embedding-8b und speziell auf der embedding-Spalte erstellt werden soll. Es ist wichtig, den Index auf der Spalte zu erstellen, die die Vektordaten enthält, die später abgefragt werden soll.
M=6 ist der Parameter, der die Struktur des Vektor-Index beeinflusst. M steht für die maximale Anzahl von Verbindungen, die von jedem Knoten gehalten werden soll. Ein höherer Wert für M führt in der Regel zu einer höheren Suchgenauigkeit, da mehr Pfade im Graphen erkundet werden können. Gleichzeitig erhöht dies den Speicherverbrauch und die Zeit, die für den Aufbau des Index benötigt wird.
DISTANCE=cosine: Dieser Parameter definiert die Abstandsmetrik, die MariaDB verwenden soll, um die Ähnlichkeit zwischen Vektoren zu berechnen. Die Kosinus-Ähnlichkeit (cosine) ist eine der gebräuchlichsten Metriken für Vektoren, insbesondere wenn es um Text-Embeddings geht. Die Kosinus-Ähnlichkeit misst den Kosinus des Winkels zwischen zwei Vektoren. Ein Wert nahe 1 bedeutet, dass die Vektoren in dieselbe Richtung zeigen (sehr ähnlich), während ein Wert nahe 0 bedeutet, dass sie orthogonal sind (unähnlich). Für Text-Embeddings ist dies oft die bevorzugte Metrik, da sie gut erfasst, ob zwei Dokumente oder Sätze thematisch verwandt sind, unabhängig von ihrer Länge.
Mit diesem Vektor-Index ist MariaDB nun in der Lage, die ähnlichsten Embeddings zu einem gegebenen Abfragevektor zu finden. Dies ist die Grundlage für KI-Anwendungen, die auf Ähnlichkeitssuchen basieren, von semantischen Suchmaschinen bis hin zu Empfehlungssystemen. Der Index wird im Hintergrund verwaltet und aktualisiert, sobald neue Embeddings in die Tabelle eingefügt werden, sodass man sich auf die Interaktion mit deinen Vektordaten konzentrieren kann, ohne sich um die darunter liegende Komplexität kümmern zu müssen.
Visuelle Überprüfung der Embedding-Spalte in DBeaver
Nachdem wir die Datenbank, die Tabelle und den speziellen Vektor-Index erstellt haben, ist es immer eine gute Praxis, das Ergebnis zu überprüfen, um sicherzustellen, dass alles korrekt eingerichtet wurde. Ein leistungsstarkes Tool dafür ist der Datenbank-Client DBeaver, der eine praktische grafische Oberfläche für die Verwaltung verschiedenster Datenbanken bietet.
Wenn man DBeaver mit deiner MariaDB-Instanz verbunden hat und zur test_database navigiert, wirst man unter dem Knoten „Tables“ die eben erstellte Tabelle qwen3-embedding-8b finden. Wenn man diese Tabelle aufklappt und den Unterknoten „Columns“ öffnet, sollte man die beiden definierten Spalten sehen: id vom Typ bigint(20) und, was am wichtigsten ist, die embedding-Spalte vom Typ vector(4096).
Diese visuelle Bestätigung zeigt auf einen Blick, dass MariaDB den VECTOR-Datentyp korrekt erkannt und mit der angegebenen Dimension von 4096 eingerichtet hat. Dies ist ein Indikator dafür, dass die zugrunde liegende MariaDB-Instanz Vektordaten nativ unterstützt und die Tabelle bereit ist, die vom qwen3-embedding-8b-Modell erzeugten Embeddings aufzunehmen.

Embeddings einfügen und Integration testen
Nachdem die MariaDB-Datenbank, die qwen3-embedding-8b-Tabelle und den Vektor-Index erfolgreich eingerichtet ist, ist es an der Zeit, die Tabelle in Aktion zu sehen.
Die Python-Vorbereitungen
Zunächst muss sichergestellt werden, dass alle notwendigen Python-Bibliotheken installiert sind. Das Skript nutzt ollama für die Embedding-Generierung und mariadb für die Datenbankinteraktion.
import os
import time
import json
import ollama
import base64
import mariadb
import sysAls Nächstes werden die Verbindungsparameter für die MariaDB-Datenbank konfiguriert. Diese sollten mit den Details des zuvor erstellten Benutzers übereinstimmen. Mit mariadb.connect stellt man die Datenbank Verbindung her.
host = 'localhost'
port = 3306
user = 'user'
password = 'password'
database = 'test_database'
conn = mariadb.connect(user=user, password=password, host=host, port=port, database=database)Es ist wichtig, dass diese Verbindung erfolgreich hergestellt wird.
Embedding-Generierung mit Ollama
Der Kern des Skripts ist die Funktion get_embeddings, die Ollama-Dienst nutzt, um Text in einen Vektor umzuwandeln. Ich verwende das qwen3-embedding:8b-Modell, das auch der Namensgeber der Tabelle ist und Vektoren mit 4096 Dimensionen erzeugt.
def get_embeddings(text_to_embed, model_name="qwen3-embedding:8b"):
try:
response = ollama.embeddings(
model=model_name,
prompt=text_to_embed
)
return response['embedding']
except Exception as e:
print(f"Error generating embeddings: {e}")
return NoneDiese Funktion nimmt einen Text entgegen und gibt bei Erfolg eine Liste von Gleitkommazahlen zurück, die das semantische Embedding repräsentieren.
Embeddings in MariaDB einfügen
Die Funktion insert_embedding_into_mariadb ist verantwortlich für das Speichern der generierten Vektoren in die Datenbank. Hier gibt es einen wichtigen Aspekt zu beachten: MariaDB erwartet den VECTOR-Datentyp als JSON-String.
def insert_embedding_into_mariadb(embedding_vector):
if not embedding_vector:
print("No embedding vector provided to insert.")
return
cursor = None
try:
cursor = conn.cursor()
rounded_embedding = [round(float(x), 4) for x in embedding_vector] # Rundung für Konsistenz und Lesbarkeit
embedding_json_string = json.dumps(rounded_embedding)
print(f"DEBUG: JSON string being sent: {embedding_json_string[:200]}...")
sql = "INSERT INTO `qwen3-embedding-8b` (embedding) VALUES (VEC_FromText(?))"
cursor.execute(sql, (embedding_json_string,))
conn.commit()
print(f"Successfully inserted embedding with ID: {cursor.lastrowid}")
except mariadb.Error as e:
print(f"Error inserting into MariaDB: {e}")
if conn:
conn.rollback()
finally:
if cursor:
cursor.close()Beachte hierbei die Zeile rounded_embedding = [round(float(x), 4) for x in embedding_vector]. Obwohl MariaDB interne Optimierungen vornimmt, kann das explizite Runden der Gleitkommazahlen vor dem Speichern die Konsistenz und Debugging-Fähigkeit verbessern, ohne die für die Ähnlichkeitssuche notwendige Präzision wesentlich zu beeinträchtigen. Die entscheidende Transformation erfolgt durch json.dumps(rounded_embedding), die den Vektor in einen JSON-String umwandelt. Die MariaDB VEC_FromText(?)-Funktion ist dann in der Lage, diesen JSON-String zu interpretieren und in das native VECTOR(4096)-Format umzuwandeln.
Testlauf und Ergebnisse
Schließlich durchlaufe ich eine Liste von Beispieltexten, generiere für jeden Eintrag ein Embedding Vektor und fügen dieses in die Datenbank ein:
texts_to_process = [
"The cat sat on the mat.",
"Dogs love to chase balls in the park.",
"Artificial intelligence is transforming many industries.",
"A quantum computer can solve certain problems much faster."
]
for i, text in enumerate(texts_to_process):
print(f"\nProcessing text {i+1}: '{text}'")
embedding = get_embeddings(text)
if embedding:
print(f"Generated embedding (first 5 elements): {embedding[:5]}...")
print(f"Embedding length: {len(embedding)}")
if len(embedding) != 4096:
print(f"Warning: Embedding length {len(embedding)} does not match table's VECTOR(4096). This might cause issues or be truncated.")
insert_embedding_into_mariadb(embedding)
else:
print(f"Could not generate embedding for text: '{text}'")
print("\nInsertion process complete.")Nach dem Ausführen des Skripts bestätigt die Ausgaben, dass die Embeddings generiert und mit eindeutigen IDs in die Datenbank eingefügt wurden. Die Debug-Ausgabe des JSON-Strings zeigt auch, wie die Daten an MariaDB gesendet werden.
Processing text 1: 'The cat sat on the mat.'
Generated embedding (first 5 elements): [-0.0026666224002838135, 0.013000323437154293, 0.002823619171977043, -0.03171399608254433, -0.010299142450094223]...
Embedding length: 4096
DEBUG: JSON string being sent: [-0.0027, 0.013, 0.0028, -0.0317, -0.0103, -0.0205, 0.0077, -0.0095, -0.0049, 0.0147, 0.0032, 0.0119, -0.0104, -0.0235, 0.0286, -0.0097, 0.0095, 0.0209, 0.0259, 0.0389, -0.0148, 0.0202, 0.0151, -0.039...
Successfully inserted embedding with ID: 1
Processing text 2: 'Dogs love to chase balls in the park.'
Generated embedding (first 5 elements): [-0.014950787648558617, 0.0052628363482654095, -0.006423640064895153, -0.038704320788383484, 0.003801250597462058]...
Embedding length: 4096
DEBUG: JSON string being sent: [-0.015, 0.0053, -0.0064, -0.0387, 0.0038, 0.0355, -0.0064, -0.0069, 0.0098, 0.0521, -0.0112, -0.0127, -0.0026, -0.0042, 0.0051, 0.0235, 0.0172, 0.0338, 0.0282, 0.0305, 0.0117, -0.0134, -0.0045, -0.02...
Successfully inserted embedding with ID: 2
Processing text 3: 'Artificial intelligence is transforming many industries.'
Generated embedding (first 5 elements): [0.012756548821926117, 0.03550448268651962, -0.016718043014407158, -0.024982227012515068, 0.07379638403654099]...
Embedding length: 4096
DEBUG: JSON string being sent: [0.0128, 0.0355, -0.0167, -0.025, 0.0738, -0.0007, -0.0172, -0.0006, 0.0161, 0.0276, -0.0306, 0.0278, 0.0406, 0.0143, 0.051, 0.009, 0.0084, -0.0144, -0.0012, -0.0082, -0.0137, 0.0227, 0.0034, 0.0038, ...
Successfully inserted embedding with ID: 3
Processing text 4: 'A quantum computer can solve certain problems much faster.'
Generated embedding (first 5 elements): [0.0023580908309668303, 0.01199082937091589, 0.021898211911320686, 0.00322919525206089, 0.04967232048511505]...
Embedding length: 4096
DEBUG: JSON string being sent: [0.0024, 0.012, 0.0219, 0.0032, 0.0497, -0.0074, -0.0221, -0.0398, 0.0328, 0.0069, -0.0609, 0.032, 0.0097, 0.0115, 0.0484, -0.0092, 0.0177, -0.0069, 0.0132, -0.0035, -0.0012, 0.0353, 0.0107, 0.0, -0.0...
Successfully inserted embedding with ID: 4
Insertion process complete.
Mit DBeaver kann man dann prüfen, ob die Daten in der Tabelle gespeichert wurden. Da die Vektoren in MariaDB als ‚blob‘ gespeichert werden, ist es leider nicht ohne weiteres möglich, die Daten anzeigen zu lassen.
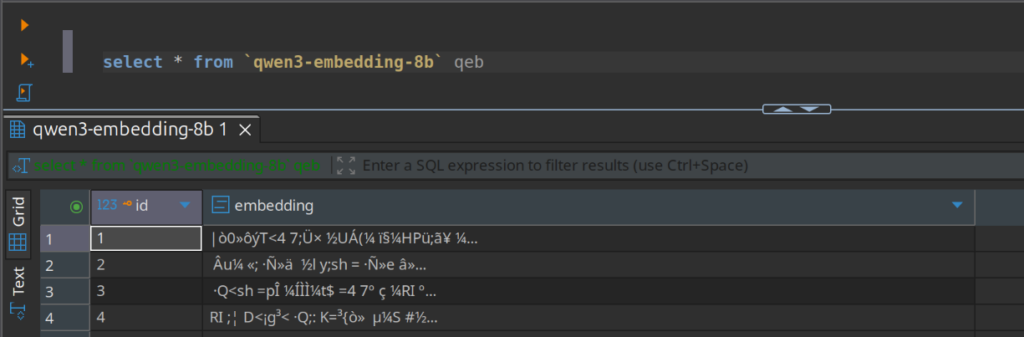
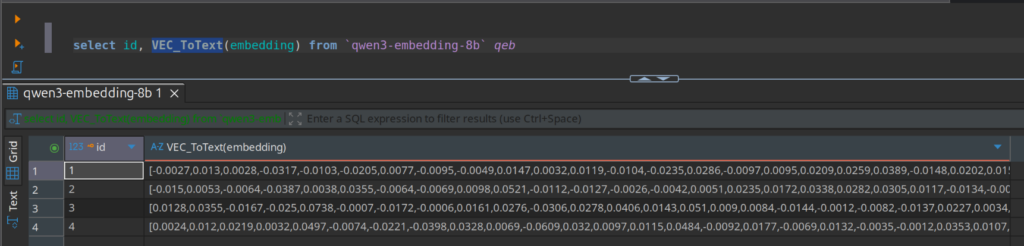
Erst mit der Funktion VEC_ToText kann man sie die ursprünglichen Daten anzeigen lassen,
MariaDB Vektor-Funktionen – Dein Werkzeugkasten für die Vektormanipulation
Nachdem die Vektor-Embeddings in der MariaDB-Datenbank gespeichert sind, ist der nächste logische Schritt, zu verstehen, wie diese Daten abgefragt und geändert werden können. MariaDB bietet eine Reihe von speziellen SQL-Funktionen, die genau für diesen Zweck entwickelt wurden. Diese Funktionen sind wichtig um eine Ähnlichkeitssuchen und die Integration in KI/ML-Anwendungen direkt in der Datenbank zu ermöglichen.
VEC_DISTANCE(vector1, vector2, metric_name)
Die Funktion VEC_DISTANCE ist das Herzstück der Ähnlichkeitssuche. Sie berechnet den Abstand oder die Ähnlichkeit zwischen zwei Vektor-Spalten oder einem Vektor und einem Literal (einem direkten Vektorwert, den du in die Abfrage eingibst). Der dritte Parameter metric_name ist dabei entscheidend, da er die verwendete Abstandsmetrik bestimmt.
Beispiel:
SELECT
id,
VEC_DISTANCE(embedding, VEC_FromText('[0.01, 0.02, ..., 0.05]'), 'cosine') AS cosine_similarity
FROM
`qwen3-embedding-8b`
ORDER BY
cosine_similarity DESC
LIMIT 10;Dieses Beispiel würde die Top 10 der ähnlichsten Vektoren basierend auf der Kosinus-Ähnlichkeit zu einem gegebenen Abfragevektor zurückgeben. Die Metrik muss nicht unbedingt cosine sein; sie kann auch euclidean (für die Euklidische Distanz) oder andere unterstützte Metriken sein.
VEC_DISTANCE_COSINE(vector1, vector2)
VEC_DISTANCE_COSINE ist eine spezialisierte Version von VEC_DISTANCE, die explizit die Kosinus-Ähnlichkeit zwischen zwei Vektoren berechnet. Für viele Text-Embedding-Anwendungen ist dies die bevorzugte Metrik, da sie den Winkel zwischen Vektoren misst und somit deren thematische Nähe gut erfasst, unabhängig von der Vektorlänge.
Beispiel:
SELECT
id,
VEC_DISTANCE_COSINE(embedding, VEC_FromText('[0.01, 0.02, ..., 0.05]')) AS similarity_score
FROM
`qwen3-embedding-8b`
ORDER BY
similarity_score DESC
LIMIT 10;Ein höherer Wert bei der Kosinus-Ähnlichkeit (näher an 1) bedeutet eine höhere Ähnlichkeit.
VEC_DISTANCE_EUCLIDEAN(vector1, vector2)
Ähnlich wie VEC_DISTANCE_COSINE ist VEC_DISTANCE_EUCLIDEAN eine dedizierte Funktion zur Berechnung der Euklidischen Distanz (auch als L2-Norm bekannt) zwischen zwei Vektoren. Die Euklidische Distanz misst die „geradlinige“ Entfernung zwischen zwei Punkten im Vektorraum. Sie ist oft nützlich, wenn die absolute Größe der Differenzen zwischen den Vektorkomponenten von Bedeutung ist, beispielsweise bei bestimmten Bild-Features oder geometrischen Daten.
Beispiel:
SELECT
id,
VEC_DISTANCE_EUCLIDEAN(embedding, VEC_FromText('[0.01, 0.02, ..., 0.05]')) AS distance_score
FROM
`qwen3-embedding-8b`
ORDER BY
distance_score ASC
LIMIT 10;Bei der Euklidischen Distanz bedeutet ein kleinerer Wert eine höhere Ähnlichkeit (geringere Entfernung), daher die Sortierung ASC.
VEC_FromText(text_string)
Diese Funktion ist für das Einfügen von Vektordaten von entscheidender Bedeutung, wie ich in dem Python-Skript gezeigt habe. VEC_FromText konvertiert einen JSON-formatierten String, der eine Liste von Gleitkommazahlen darstellt, in das native VECTOR-Datentypformat, das MariaDB intern verwendet. Dies ermöglicht es, Vektoren aus externen Quellen, die typischerweise als JSON-Arrays vorliegen, korrekt in die Datenbank zu importieren.
Beispiel (direkt in SQL):
INSERT INTO `qwen3-embedding-8b` (embedding)
VALUES (VEC_FromText('[0.001, 0.002, -0.003, ..., 0.040]'));Hierbei muss der JSON-String exakt die Dimension des Vektors in der Tabelle (in meinem Fall 4096) aufweisen.
VEC_ToText(vector_column)
VEC_ToText ist das Gegenstück zu VEC_FromText. Diese Funktion konvertiert eine Vektor-Spalte zurück in einen JSON-formatierten String. Dies ist nützlich, wenn man Vektordaten aus MariaDB extrahieren und in einer Anwendung weiterverarbeiten möchte, die JSON-Arrays besser handhaben kann, oder einfach nur, um den Inhalt einer Vektor-Spalte zu inspizieren.
Beispiel:
SELECT
id,
VEC_ToText(embedding) AS embedding_json
FROM
`qwen3-embedding-8b`
WHERE
id = 1;Diese Abfrage würde die id und den Vektor als JSON-String für den Eintrag mit der ID 1 zurückgeben.
Zusammengenommen bilden diese Vektor-Funktionen einen Satz von Werkzeugen, die es ermöglichen, mit hochdimensionalen Vektor direkt in MariaDB zu arbeiten. Die Integration dieser Funktionen in vorhandene SQL-Abfragen ermöglicht eine einfacheren Integration von Vektor-Daten und Relationalen-Daten.
Die Dokumentation der MariaDB Vektor Funktionen kann man unter https://mariadb.com/docs/server/reference/sql-functions/vector-functions nachlesen.
Das Python Jupyter Notebook für den Test kann man unter https://gist.github.com/msoftware/25c0d206d6d1b8eb38cb0c234201f8b3 finden.