Die Transformer-Technologie dominiert aktuell den Bereichen des maschinellen Lernens bei der natürlichen Sprachverarbeitung. Eingeführt wurde der Transformer im Jahr 2017 durch in dem Papier „Attention is All You Need“. Die Transformer-Architektur hat das Konzept des Selbst-Attention-Mechanismus populär gemacht. Dieser ermöglicht es, Wichtigkeiten unterschiedlicher Teile eines Textes zu erkennen und darauf zu reagieren. Seit ihrer Einführung haben Transformer-Modelle die Grundlage für fortschrittliche Sprachmodelle wie z.B. GPT gebildet und sind zum Standard für viele Aufgaben im Bereich des NLP (Natural Language Processing) geworden. Damit ist es aber nun vorbei – wenn es nach Sepp Hochreiter und seinem neu vorgestellten xLSTM geht. Beim xLSTM, handelt es sich um eine erweiterte Form des LSTM, das laut Sepp Hochreiter ein neues Kapitel in der Entwicklung von Sprachmodellen aufgeschlagen wird.

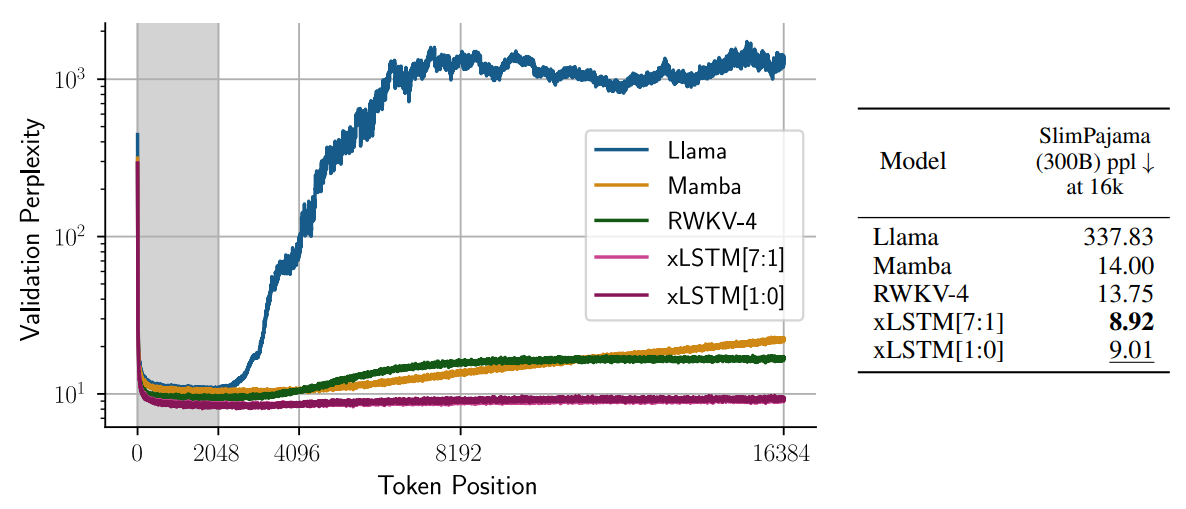
Die Abbildung illustriert deutlich, wie die Modifikationen am LSTM zu erheblichen Verbesserungen der Perplexity führt.
Was ist xLSTM?
xLSTM steht für Extended Long Short-Term Memory. Diese Technologie baut auf den traditionellen LSTM-Strukturen auf, erweitert diese jedoch um entscheidende Merkmale, die die Effizienz und Leistungsfähigkeit im Umgang mit großen Datenmengen und komplexen Sequenzmodellierungsaufgaben verbessern. Insbesondere führt xLSTM „exponential gating“ und modifizierte Speicherstrukturen ein, die es ermöglichen, die bekannten Limitierungen herkömmlicher LSTMs zu überwinden.
xLSTM Vorteile gegenüber dem Transformer
Der größte Vorteil des xLSTM im Vergleich zu Transformer-Modellen liegt in seiner Fähigkeit, Informationen effektiv über lange Zeiträume zu bewahren und zu verwalten, ohne dabei auf die Rechenintensität und Komplexität der Self-Attention-Mechanismen angewiesen zu sein, die in Transformer-Modellen verwendet werden.
Self-Attention erfordert es, dass jedes Element der Sequenz mit jedem anderen Element verglichen wird, um die Aufmerksamkeitsgewichte zu berechnen. Dies führt zu einer quadratischen Zunahme der Rechenanforderungen in Bezug auf die Länge der Sequenz, was sowohl die Speichernutzung als auch die Rechenzeit beträchtlich erhöht. Zudem wird die Effizienz der Self-Attention-Mechanismen durch die Verwässerung der Aufmerksamkeit über viele Token hinweg reduziert, was die Fähigkeit, relevante Informationen aus weit entfernten Positionen in der Sequenz zu extrahieren und zu nutzen, verringert. Dieses Skalierungsproblem schränkt die praktische Anwendbarkeit von Transformern bei Aufgaben mit sehr großen Texten (z.B. RAG) ein.
xLSTM adressiert dies durch seine erweiterten LSTM-Komponenten. Dank des Exponential-Gatings und der verbesserten Speicherstrukturen, wird es möglich, Informationen selektiv über lange Zeiträume zu speichern und zu aktualisieren. Diese Fähigkeit macht xLSTM besonders geeignet für Anwendungen, bei denen es auf eine langfristige Erinnerung über lange Sequenzen ankommt, wie etwa bei komplexen Zeitreihenanalysen oder detaillierten Sprachmodellierungsaufgaben, wo jedes Stück Information über längere Zeiträume hinweg von Bedeutung sein kann.
Eigenschaften des xLSTM
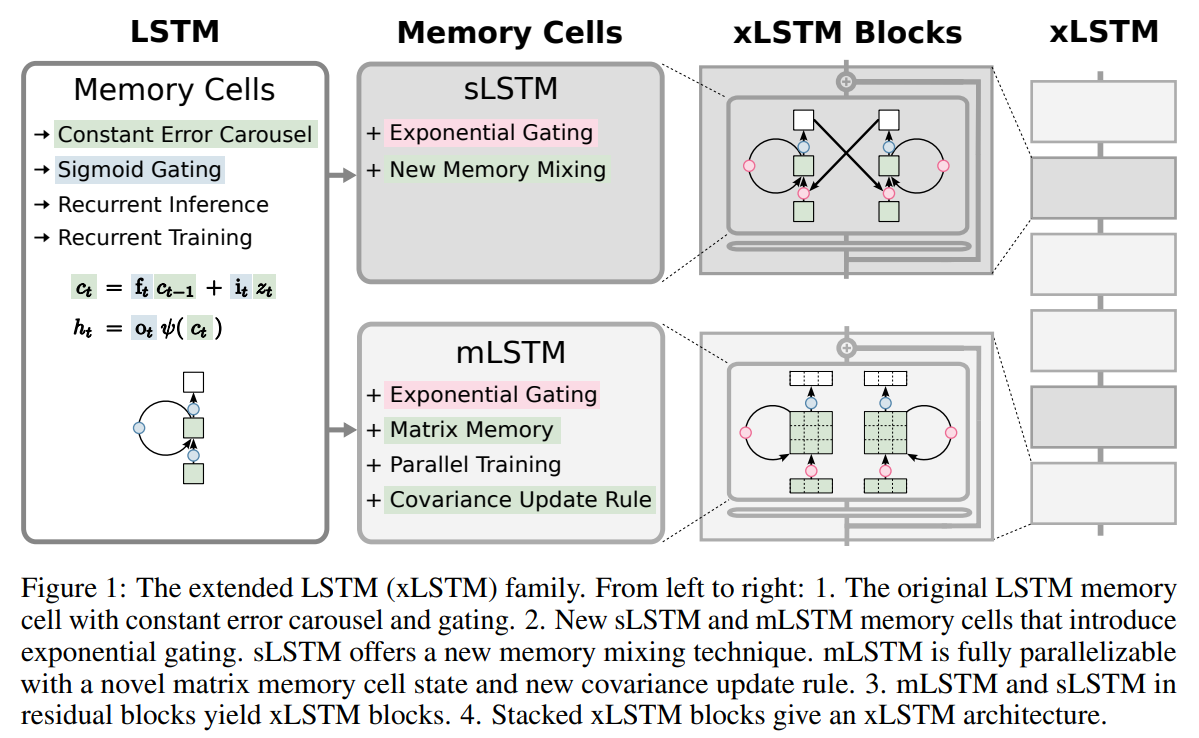
- Exponential Gating: Das Exponential Gating im xLSTM ist eine Weiterentwicklung der traditionellen Gating-Mechanismen in LSTM-Modellen. Diese Funktion ermöglicht es dem xLSTM, die Eingangsinformationen dynamischer und effektiver zu verarbeiten. Es hilft, wichtige Informationen über längere Zeiträume zu bewahren und weniger relevante Informationen effizienter zu verwerfen.
Im klassischen LSTM-Modell werden die Gating-Mechanismen durch Sigmoid-Funktionen gesteuert, die Werte zwischen 0 und 1 liefern. Diese Gating-Funktionen regulieren den Informationsfluss durch das Netzwerk, indem sie entscheiden, wie viel von der vorherigen Information vergessen und wie viel der neuen Information hinzugefügt wird. Im Gegensatz zu herkömmlichen LSTMs verwendet das xLSTM exponentielle Aktivierungsfunktionen für die Input- und Forget-Gates. Durch die Nutzung exponentieller Funktionen kann das xLSTM stärker variierende Skalierungen der Gate-Aktivierungen erreichen. - Matrixspeicher: Im Gegensatz zu traditionellen LSTMs, die einen skalaren Zellzustand verwenden, implementiert das mLSTM eine Matrix als Zellzustand. Diese Matrix ermöglicht es dem Modell, Informationen in einer strukturierteren Form zu speichern. Jeder Eintrag in der Matrix kann dabei eine unterschiedliche Information oder Beziehung innerhalb der verarbeiteten Daten repräsentieren. Ein weiterer Vorteil des mLSTM ist seine vollständige Parallelisierbarkeit. Durch die Matrixstruktur des Speichers können Operationen, die traditionell sequenziell ausgeführt werden müssten, parallel durchgeführt werden, was die Effizienz des Modells erheblich verbessert.
- Skalarer Speicher:
sLSTM sind skalare Speicher, die ähnlich wie bei herkömmlichen LSTMs aktualisiert werden, jedoch mit Unterschieden in der Implementierung. Der skalare Speicher macht das sLSTM effizienter im Umgang mit Aufgaben, die weniger komplexe Abhängigkeiten in den Daten aufweisen, aber eine höhere Rechenleistung erforderlich ist. Mit dem sLSTM wird auch das Konzept des Memory Mixing eingeführt, was wichtige Informationen über längere Zeiträume bewahren kann, indem es die relevanten Daten aus verschiedenen Zeitschritten im Netzwerk verteilt und nutzbar macht.
Anwendungen und Implikationen
Das xLSTM-Modell bietet erhebliche Vorteile für die Ausführung auf Consumer PCs, was es zu einer attraktiven Wahl für Entwickler und Endanwender macht. Das xLSTM muss nicht für jedes neu erstellte Token die gesamte Sequenz verarbeiten. Stattdessen verwendet das xLSTM Mechanismen, um relevante Informationen zu speichern und bei Bedarf wieder abzurufen. Dadurch wird der Berechnungsaufwand erheblich reduziert was insbesondere bei langen Sequenzen zu einer signifikanten Effizienzsteigerung führt, aber ein paralleles Training des xLSTM im Vergleich zum Transformer schwieriger machen dürfte.
Die Extrapolation der Sequenzlänge des xLSTM zeigt beeindruckende Ergebnisse im Vergleich zu anderen Modellen wie Llama, Mamba und RWKV-4. In einem Test, bei dem Modelle auf eine Kontextlänge von 2048 trainiert und anschließend auf Kontextlängen bis zu 16384 getestet wurden, demonstriert das xLSTM eine bemerkenswerte Fähigkeit, auch bei ausgedehnten Sequenzen eine niedrige Perplexität zu erhalten. Wie aus der Abbildung ersichtlich, steigt die Perplexität des Llama-Modells deutlich an, wenn die Token-Position 2048 überschreitet, während die xLSTM-Modelle durchgehend niedrige Perplexitätsniveaus beibehalten. Dies verdeutlicht die Robustheit des xLSTM bei der Verarbeitung langer Textsequenzen, was es besonders geeignet für Anwendungen macht, die eine präzise Sprachverarbeitung über große Sequenzen benötigen, wie zum Beispiel bei der Zusammenfassung langer Texte oder in anderen NLP-Aufgaben, die ein tiefes Verständnis des Kontextes erfordern.
Das xLSTM integriert erweiterte LSTM-Strukturen, die speziell dafür entwickelt wurden, Informationen über lange Zeiträume effektiv zu speichern und zu verarbeiten, und ist dabei wesentlich weniger abhängig von der Sequenzlänge der Trainingsdaten als ein Transformer.
Im Gegensatz zum Transformer, der auf dem Self-Attention basiert und jede Eingabe mit jeder anderen vergleicht, kann das xLSTM Informationen sequenziell verarbeiten und dabei relevante Informationen über längere Distanzen bewahren ohne bei zunehmender Sequenzlänge unter der Last der wachsenden Rechenanforderungen zu leiden da die Komplexität der Berechnungen beim xLSMT nicht quadratisch mit der Anzahl der Token steigt.
Der Nachteil des xLSTM im Vergleich zum Transformer ist, dass es beim Training vermutlich nicht das Parallelisierungsniveau von Transformern erreicht. Die sequenziellen Abhängigkeiten, begrenzen die Parallelisierungsfähigkeiten beim Training des xLSTM, was dazu führen kann, dass es möglicherweise nicht möglich ist, xLSTMs in großen Rechenzentren auf 100.000 und mehr GPUs gleichzeitig zu trainieren. Evtl. verstehe ich es auch noch nicht richtig oder ein xLSTM Training verläuft komplett anders als ein Transformer Training. Diesbezüglich habe ich bei Twitter noch mal bei Sepp Hochreiter nachgefragt und werde den Abschnitt hier korrigieren bzw. ergänzen sobald ich eine Antwort bekommen habe.
Fazit
Das xLSTM könnte sich als eine bemerkenswerte Weiterentwicklung des traditionellen LSTM erwiesen. Durch das Exponential Gating und neue Speicherstrukturen bietet das xLSTM eine starke Leistung bei NLP Aufgaben und zeigt einige Vorteile gegenüber den etablierten Methoden. Es deutet einiges darauf hin, dass größere xLSTM-Modelle ernsthafte Konkurrenten für die derzeitigen großen Sprachmodelle darstellen könnten falls ein paralleles Training mit großen Datenmengen möglich ist.
Das Potenzial von xLSTM erstreckt sich laut seiner Mitwirkenden über die NLP hinaus und könnte auch Auswirkungen auf das Reinforcement Learning, Time Series Prediction oder die Modellierung physikalischer Systeme haben. Ich bin schon sehr darauf gespannt, die ersten Open Source Implementierungen zu sehen und hoffe, dass es das xLSTM genauso viele Deep Learning Success-Stories erlebt wie das klassisch LSTM.
