
Im „INDUSTRIAL AI PODCAST“ #230 vom 05.02.2024 war Sepp Hochreiter zusammen mir Johannes Brandstetter zu Gast, um von einer neuen LLM-Alternative „xLSTM“ zu berichten an der Sepp Hochreiter mit seinem Team gerade arbeitet und das laut Sepp Hochreiter das Potential hat, OpenAI aus dem Markt zu werfen.
Noch ist nicht viel bekannt, da die Intellectual Property Rights noch in der Luft hängen, Sepp Hochreiter die Rechte am xLSTM in Europa/Österreich halten möchte und die Technologie noch nicht patentiert ist. Trotzdem habe ich mal versucht, die vorhandenen Informationen und Spekulationen zusammenzutragen. Nehmt es mir also nicht übel, wenn hier etwas nicht ganz korrekt ist bzw. sich noch ändert. Vieles davon sind Halbwahrheiten bzw. Gerüchte.
Aber was genau ist xLSTM?
Das neue europäische Large Language Model solle eine Alternative zu den gängigen Transformer-Modellen darstellen. Im Gegensatz zu den extrem rechenintensiven Berechnungen der Transformer-Architekturen, die quadratisch mit der Textlänge ansteigen, arbeitet xLSTM effizienter, schneller und genauer. Die Berechnungen der xLSTM Architektur wird linear mit der Textlänge ansteigen was besonders bei längeren Sequenzen ein sehr großer Vorteil ist. Zudem soll es die Semantik von Texten besser verstehen und komplizierte Texte sowohl auffassen als auch generieren können.
Sepp Hochreiter, der bereits vor über 25 Jahren zusammen mit Jürgen Schmidhuber die LSTM (Long Short Term Memory) -Technologie entwickelte, ebnete den Weg für die heutige Künstliche Intelligenz. Seine LSTM-Technologie wird heute von großen Firmen wie Amazon, Alphabet, Apple und vielen anderen genutzt, da das LSTM nicht durch ein Patent geschützt ist, während der Transformer von Google patentiert ist.
Grundlegende Aspekte des klassischen LSTM
- LSTM-Architektur: Das LSTM ist eine spezielle Art von rekurrentem neuronalen Netzwerk (RNN). Im Gegensatz zu herkömmlichen RNNs, die Schwierigkeiten mit dem Verschwinden oder Explodieren von Gradienten haben, löst das LSTM diese Probleme durch seine spezielle Architektur. Es besteht aus sogenannten “Gates”, die den Informationsfluss innerhalb des Netzwerks steuern.
- Forget Gate (Vergessens-Gate): Dieses Gate entscheidet, welche Informationen aus dem vorherigen Zustand vergessen werden sollen. Es hilft, unnötige Informationen zu verwerfen und relevante Informationen zu behalten.
- Input Gate (Eingabe-Gate): Das Eingabe-Gate bestimmt, welche neuen Informationen in den aktuellen Zustand einfließen sollen. Es reguliert den Informationsfluss und ermöglicht das Hinzufügen neuer Informationen.
- Output Gate (Ausgabe-Gate): Das Ausgabe-Gate bestimmt, welche Informationen aus dem aktuellen Zustand an den nächsten Zustand weitergegeben werden. Es beeinflusst die Ausgabe des LSTM.
- Cell State (Zellzustand): Der Zellzustand speichert Informationen über längere Zeiträume hinweg. Er wird durch die Forget-, Input- und Output-Gates gesteuert.
- Anwendungen: LSTMs werden häufig für Aufgaben wie maschinelles Übersetzen, Spracherkennung, Zeitreihenanalyse und Textgenerierung verwendet. Sie sind besonders gut geeignet, um lange Abhängigkeiten in Sequenzen zu modellieren.
Das klassische LSTM hat die Grundlage für viele weitere Entwicklungen im Bereich der rekurrenten neuronalen Netzwerke gelegt. Es ist ein leistungsstarkes Werkzeug für die Verarbeitung von Sequenzdaten und hat die KI-Forschung und -Anwendung nachhaltig beeinflusst. Es ist in der Lage, Sequenzen von Daten zu verarbeiten und zu lernen. Wenn man sagt, dass ein LSTM „autoregressiv“ ist, bedeutet es, dass es in der Lage ist, eine Vorhersage über die nächste Zeitstufe in einer Sequenz zu treffen, basierend auf den vorherigen Zeitstufen.
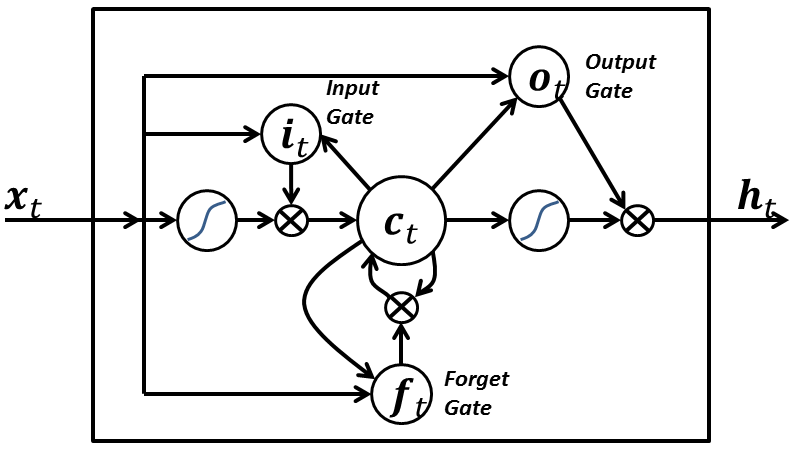
Grober Aufbau eines LSTM-Moduls mit der inneren Zelle im Zentrum. Die großen Kreise mit S-artiger Kurve sind die Sigmoidfunktionen. Die Pfeile, die von der Zelle jeweils zu den Gates zeigen, sind die Gucklochinformationen vom letzten Durchlauf.
Quelle: https://de.wikipedia.org/wiki/Long_short-term_memory
In einfachen Worten bedeutet das, dass das LSTM aus vergangenen Daten lernt und diese verwendet, um vorherzusagen, was als nächstes kommen könnte. Es schaut auf die Vergangenheit, um die Zukunft vorherzusagen.
xLSTM Spekulationen
Mit xLSTM gelingt hoffentlich ein weiterer Durchbruch. Leider sind bisher aber nur sehr wenige Details bekannt und daher kann man nur spekulieren, was das Besondere am xLSTM ist.
Das LSTM hat gegenüber der Transformer Architektur einige Nachteile, die hoffentlich mit dem xLSTM gelöst werden können.
- LSTMs verarbeiten Sequenzen schrittweise, wobei sie Schritt für Schritt vorgehen. Dies kann zu langsameren Berechnungen führen, insbesondere bei langen Sequenzen. Transformer verarbeiten die gesamte Sequenz gleichzeitig, das ermöglicht parallele Berechnungen und beschleunigt den Trainingsprozess.
- Obwohl LSTMs in der Lage sind, bestimmte langfristige Abhängigkeiten zu erfassen, haben sie Schwierigkeiten mit sehr langen Abhängigkeiten. Dies liegt daran, dass sie auf vergangene versteckte Zustände angewiesen sind, um Zusammenhänge zu erfassen. Transformer verwenden den Self-Attention-Mechanismen wie im „Attention is all you need“ Paper Beschrieben, um Abhängigkeiten zwischen „Wörtern“ zu modellieren. Sie sind besser darin, lange Abhängigkeiten zu erfassen, da sie die gesamte Sequenz auf einmal betrachten und keine Informationen verlieren.
- LSTMs haben viele versteckte Zustände, die für das Verarbeiten der Sequenzen benötigt werden, was zu einer höheren Komplexität führt. Transformer haben keine rekurrenten Verbindungen. Dadurch wird das Training und die Skalierung erleichtert.
- LSTMs verwenden keine expliziten Positionsinformationen. Sie sind auf die Reihenfolge der Elemente der Sequenz angewiesen. Transformer verwenden Positional Embeddings, um die Position jedes Tokens einer Sequenz zu kodieren. Dadurch können sie auch ohne Rekursion lange Abhängigkeiten modellieren.
- LSTMs können Informationen über lange Sequenzen hinweg verlieren, da sie auf vergangene Zustände angewiesen sind. Transformer verlieren keine Informationen, da sie die komplette Sequenz auf einmal verarbeiten.
Im neuen xLSTM soll die existierende LSTM-Architektur z.B. durch Exponential Gating verbessert werden. In LSTMs werden Gates verwendet, um zu steuern, wie Informationen durch das Netzwerk fließen. Diese Gates regeln, welche Informationen behalten, und welche vergessen werden sollen. Das Konzept des Exponential Gating bezieht sich darauf, wie diese Gates Informationen filtern. im xLSTM werden hier vermutlich Exponentialfunktionen verwendet, um zu entscheiden, wie stark bestimmte Informationen betont oder unterdrückt werden sollen. Dadurch ist es evtl. möglich eine feinere Abstufung der Priorisierung vornehmen zu können. Außerdem sollen im xLSTM mehr Informationen gespeichert werden können. Sepp Hochreiter spricht im Industrial AP Podcast vom „Vectorized LSTM“. Das könne darauf hinweisen, dass die neue xLSTM-Architektur in einer Weise implementiert wird, das hier Vektoren für die Gates verwendet werden. Dies könnte zu einer Verbesserung der gespeicherten Informationen führen. Die Funktionsweise der Gates bleibt vermutlich die gleiche wie bei herkömmlichen LSTMs. Sie kontrollieren weiterhin den Fluss von Informationen innerhalb des Netzwerks, indem sie entscheiden, welche Informationen beibehalten, und welche verworfen werden sollen. Die Vectorization ändert nicht das grundlegende Konzept der Gate-Funktionen, sondern verbessert vermutlich nur die Menge bzw. Qualität der gespeicherten Informationen und die Effizienz der Berechnungen.
Fazit
Vermutlich wird es im xLSTM einige Verbesserungen gegenüber dem ursprünglichen LSTM geben. Ob die dann reichen, um OpenAI aus dem Markt zu werfen wird sich zeigen.
Quellen
https://www.youtube.com/watch?v=hwIt7ezy6t8
https://github.com/AI-Guru/xlstm-resources
https://www.hannovermesse.de/en/news/news-articles/millions-for-xlstm