
Ein Schlüsselaspekt bei der Nutzung von großen LLMs (Large Language Modellen) wie dem C4AI Command R+ ist die Quantisierung der Modellparameter, die es ermöglicht, die Größe der Modelle erheblich zu reduzieren, ohne dabei die Genauigkeit und Leistungsfähigkeit signifikant zu beeinträchtigen. Durch die Anwendung dieser Methode können die Modelle auch auf Hardware mit beschränkten Ressourcen eingesetzt werden.
Quantisierung von LLMs
Die Quantisierung von LLMs (Large Language Modellen) ist ein Verfahren, bei dem die Größe und Komplexität dieser Modelle reduziert werden, um sie effizienter zu machen. Hierbei hat in letzter Zeit vor allem die GGUF-Quantisierung dazu beigetragen, eine breitere Nutzung und Demokratisierung des Zugangs zu diesen leistungsstarken Modellen zu ermöglichen.
GGUF wurde speziell für das schnelle Laden und Speichern von Modellen entworfen. Es ist optimiert für effiziente Inferenz, was bedeutet, dass es besonders gut für Anwendungen geeignet ist, bei denen Geschwindigkeit und Effizienz entscheidend sind.
Quantisierungstypen
Die verschiedenen Methoden zur Reduzierung der Modellgröße und Komplexität für die Inferenz von LLMs (Large Language Modellen) führen zu unterschiedlichen Quantisierungstypen. Hier sind einige der gängigen Quantisierungstypen:
- F32
32-Bit Standard IEEE 754 Gleitkommazahl mit einfacher Genauigkeit. - F16
16-Bit Standard IEEE 754 Gleitkommazahl mit halber Genauigkeit. - Q8_0
8-Bit Quantisierung mit Rundung zur nächsten Zahl (q). Jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale. - Q8_1
8-Bit Quantisierung mit Rundung zur nächsten Zahl (q). Jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale + block_minimum. - Q8_K
8-Bit Quantisierung. Jeder Block hat 256 Gewichte. Nur verwendet für die Quantisierung von Zwischenergebnissen. Alle 2-6 Bit Punktprodukte sind für diesen Quantisierungstyp implementiert. Gewichtsformel: w = q * block_scale. - Q6_K
6-Bit Quantisierung. Superblöcke mit 16 Blöcken, jeder Block hat 16 Gewichte. Gewichtsformel: w = q * block_scale(8-Bit), resultierend in 6,5625 Bit pro Gewicht. - Q5_0
5-Bit Quantisierung mit Rundung zur nächsten Zahl (q). Jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale. - Q5_1
5-Bit Quantisierung mit Rundung zur nächsten Zahl (q). Jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale + block_minimum. - Q5_K
5-Bit Quantisierung. Superblöcke mit 8 Blöcken, jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale(6-Bit) + block_min(6-Bit), resultierend in 5,5 Bit pro Gewicht. - Q4_0
4-Bit Quantisierung mit Rundung zur nächsten Zahl (q). Jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale. - Q4_1
4-Bit Quantisierung mit Rundung zur nächsten Zahl (q). Jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale + block_minimum. - Q4_K
4-Bit Quantisierung (q). Superblöcke mit 8 Blöcken, jeder Block hat 32 Gewichte. Gewichtsformel: w = q * block_scale(6-Bit) + block_min(6-Bit), resultierend in 4,5 Bit pro Gewicht. - Q3_K
3-Bit Quantisierung. Superblöcke mit 16 Blöcken, jeder Block hat 16 Gewichte. Gewichtsformel: w = q * block_scale(6-Bit), resultierend in 3,4375 Bit pro Gewicht. - Q2_K
2-Bit Quantisierung. Superblöcke mit 16 Blöcken, jeder Block hat 16 Gewichte. Gewichtsformel: w = q * block_scale(4-Bit) + block_min(4-Bit), resultierend in 2,5625 Bit pro Gewicht. - IQ4_XS
4-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet, resultierend in 4,25 Bit pro Gewicht. - IQ3_S
3-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet, resultierend in 3,44 Bit pro Gewicht. - IQ3_XXS
3-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet, resultierend in 3,06 Bit pro Gewicht. - IQ2_XXS
2-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet, resultierend in 2,06 Bit pro Gewicht. - IQ2_S
2-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet, resultierend in 2,5 Bit pro Gewicht. - IQ2_XS 2-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet, resultierend in 2,31 Bit pro Gewicht.
- IQ1_S
1-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet, resultierend in 1,56 Bit pro Gewicht. - IQ4_NL
4-Bit Quantisierung. Superblöcke mit 256 Gewichten. Gewicht w wird mittels super_block_scale & Bedeutungsmatrix errechnet.
Quelle: https://huggingface.co/docs/hub/en/gguf
Perplexität
Die Perplexität ist ein Maß für die Unsicherheit eines Sprachmodells bei der Vorhersage des nächsten Wortes. Damit ist sie ein zentraler Indikator für die Leistungsfähigkeit eines LLMs (Large Language Model). Ein niedriger Wert zeigt an, dass das Modell die Sprache erfasst hat und mit hoher Sicherheit das nächste Wort in einer Sequenz vorhersagen kann. Umgekehrt deutet ein hoher Wert auf größere Unsicherheit und Schwierigkeiten des Modells hin, was zu weniger präzisen bzw. relevanten Textgenerierungen führen kann. Die Perplexität wird daher gerne genutzt, um unterschiedliche Modelle oder Modellversionen miteinander zu vergleichen. So lässt sich sehr einfach feststellen, wie gut ein Modell in der Lage ist, das nächste Wort in einer Sequenz vorherzusagen. Die GGUF-Quantisierung kann diese Metrik in vielfältiger Weise beeinflussen, da die Quantisierung die Modellkomplexität reduziert, was zu einer Erhöhung der Perplexität führt, da das Modell nicht mehr in der Lage ist, die feinen Nuancen der Sprache adäquat zu modellieren. Trotzdem ist es immer wieder erstaunlich, wie gering die Perplexitätsunterschiede bei Quantisierten Modellen im Vergleich zu F16/F32 Modellen ist.
Das C4AI Command R+ Modell bietet ein gutes Beispiel dafür, wie die GGUF-Quantisierung implementiert werden kann, ohne dass eine gravierende Steigerung der Perplexität zu verzeichnen ist, was zeigt, dass das Modell weiterhin effektiv arbeitet und gute Vorhersagen liefert, auch wenn die Parameter auf eine niedrigere Bitbreite reduziert werden. Dadurch wird der Speicherverbrauch gesenkt, ohne die Genauigkeit und die Fähigkeit zur Verarbeitung komplexer Anfragen zu stark zu beeinträchtigen.
C4AI Command R+ Quantisierungen
Die Huggingface-Webseite von TheBloke (Tom Jobbins) ist eine ausgezeichnete Anlaufstelle für GGUF-optimierte Modelle, da sie eine breite Palette an hochwertigen, vortrainierten Modellen bietet, die mit der neuesten Quantisierungstechnologie optimiert wurden. Zusätzlich zu dem Zugang zu diesen quantisierten Modellen bietet TheBloke auch Hinweise zur Nutzung (Use Case) und zum benötigten VRAM zu allen Quantisierungen. Hier z.B. am Beispiel von TheBloke/CodeLlama-70B-Python-GGUF
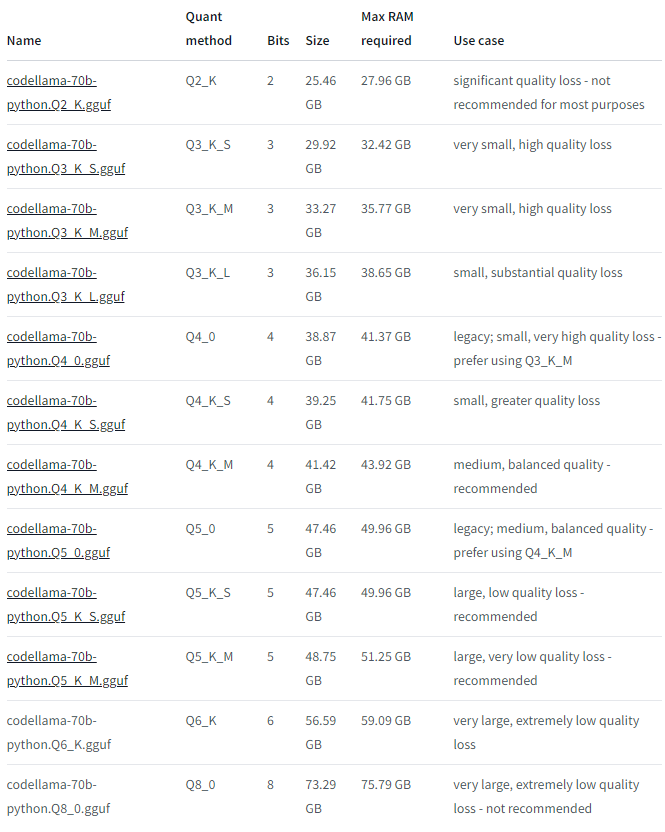
Quelle: https://huggingface.co/TheBloke/CodeLlama-70B-Python-GGUF
Das CohereForAI Command R+ Modell ist aber (noch) nicht von TheBloke verfügbar (was evtl. auch an der Lizenz liegt https://docs.cohere.com/docs/c4ai-acceptable-use-policy). Dafür gibt es aber eine GGUF Version von Command R+ unter https://huggingface.co/dranger003/c4ai-command-r-plus-iMat.GGUF von dranger003, der auch schon einige Modelle im GGUF Format bereitgestellt hat. Darunter z.B. auch dbrx-instruct-iMat.GGUF, Qwen1.5-72B-Chat-iMat.GGUF oder dolphincoder-starcoder2-15b-iMat.GGUF.
Im LMSYS Chatbot Arena Leaderboard ist Command R+ unter den Top 10 Modellen. Neben GPT4, Claude 3 und Gemini Pro ist es damit momentan noch das einzige offene Modell, dass unter der Creative Commons CC-BY-NC-4.0 Lizenz (Namensnennung-Nicht kommerziell 4.0) veröffentlicht wurde.
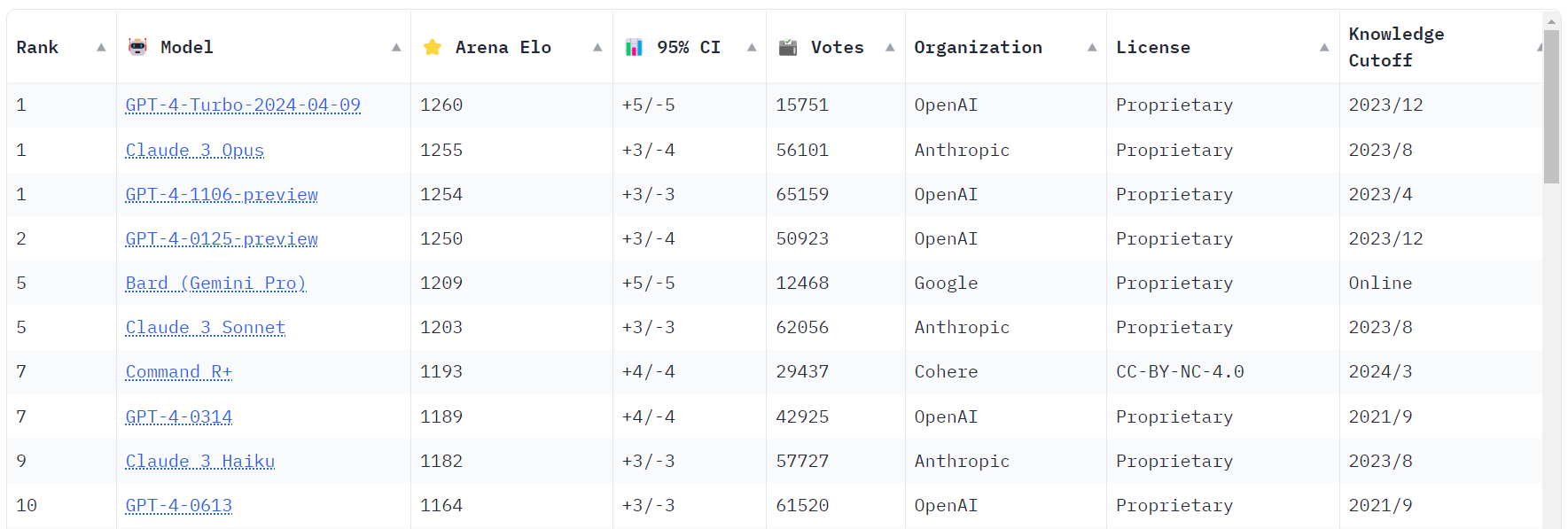
Quelle: https://chat.lmsys.org/?leaderboard
Die Quantisierungen von Command R+ werden unter dranger003/c4ai-command-r-plus-iMat.GGUF in den Quantisierungen F16, IQ1_MIQ, 1_SIQ, 2_MIQ, 2_SIQ, 2_XSIQ, 2_XXSIQ, 3_MIQ, 3_SIQ, 3_XSIQ, 3_XXSIQ, 4_XSQ, 3_K_LQ, 3_K_MQ, 5_K_SQ und 6_KQ8_0 zum Download angeboten. Netterweise hat dranger003 auf der Webseite auch eine Tabelle, in der die Perplexity der verschiedenen GGUF-Quantisierungen angegeben wird.
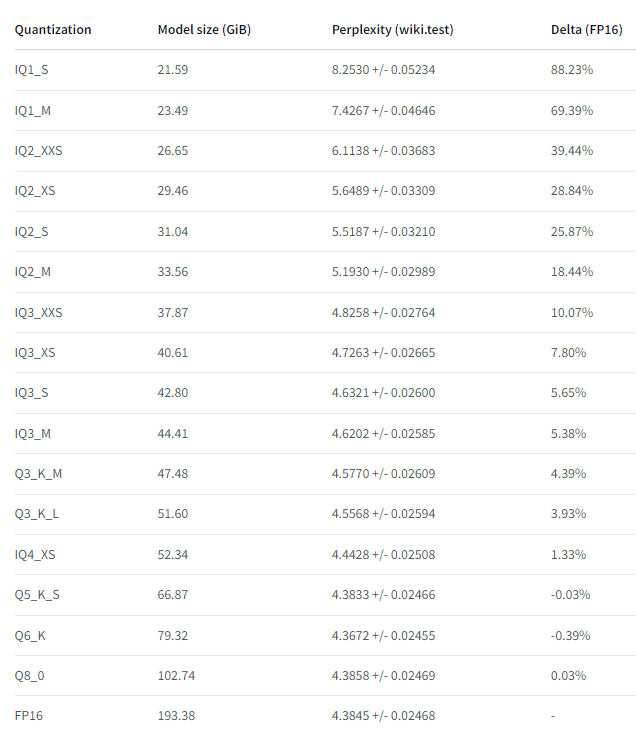
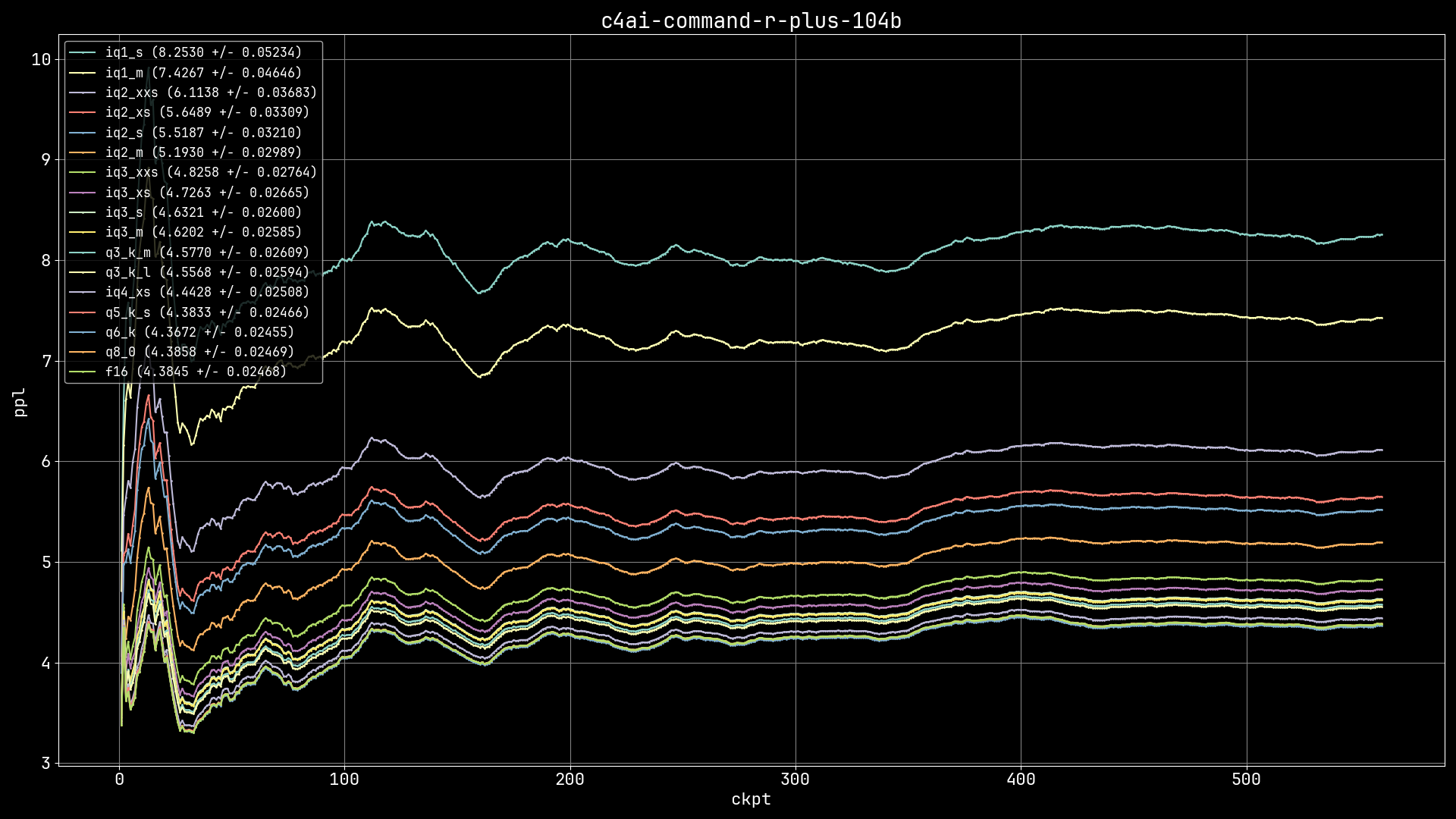
Quelle: https://huggingface.co/dranger003/c4ai-command-r-plus-iMat.GGUF
Das Bild zeigt ein Diagramm, das vermutlich Leistungsdaten aus einem Computerexperiment oder einer maschinellen Lernanwendung darstellt. Auf der y-Achse ist die Metrik „ppl“ abgetragen, was für „perplexity“ (Verwirrtheit) stehen könnte, eine häufige Metrik in der Modellierung von Sprache, die angibt, wie gut ein Wahrscheinlichkeitsmodell Daten vorhersagen kann. Je niedriger die Perplexität, desto besser die Vorhersagequalität des Modells. Auf der x-Achse ist „ckpt“ zu sehen, was für „checkpoint“ stehen könnte, was darauf hinweist, dass es sich um verschiedene Zeitpunkte oder Phasen im Prozess handelt.Mehrere Linien verschiedener Farben zeigen den Verlauf der Perplexität über die Zeit oder über die Checkpoints hinweg. Jede Linie ist mit einer Bezeichnung versehen, wie „iq1_s“, „iq1_m“, „iq2_xs“, und so weiter, gefolgt von Werten in Klammern. Diese Bezeichnungen könnten für unterschiedliche Modelle oder Konfigurationen stehen, wobei die Werte in Klammern möglicherweise den Mittelwert und die Standardabweichung der Perplexität für jedes Modell angeben.
Nach einem initialen Anstieg und anschließenden starken Abfall konvergieren alle Linien und zeigen über die Zeit eine relativ stabile Perplexität, was darauf hindeuten könnte, dass die Modelle nach anfänglicher Anpassung eine konsistente Leistung erbringen. Der Titel oben rechts, „c4ai-command-r-plus-104b“, könnte der Name des Experiments oder des verwendeten Modells sein.
Dieser Text wird von CahtGPT4 erzeugt, wenn man das obige Bild im Chat hochlädt und den Prompt „Beschreibe den Inhalt des Bildes“ eingibt. Wow – sehr beeindruckend, auch wenn es nichts mit dem Artikel zu tun hat 🙂
Wie man oben sehen kann, ist selbst die IQ4_XS Variante mit einer Perplexity von 4,4428 gar nicht mal so schlecht, wenn man bedenkt, die Modellgröße von ca. 193GB auf ca. 52GB reduziert wird. Zum Test habe ich mal die IQ4_XS Version heruntergeladen, die sich aus den folgenden 2 Dateien zusammensetzt und nur ein Delta von 1.33% zu FP16 haben soll.
ls -altrh ggml-c4ai-command-r-plus*
-rw-r--r-- 1 root root 46G Apr 7 15:30 ggml-c4ai-command-r-plus-104b-iq4_xs-00001-of-00002.gguf
-rw-r--r-- 1 root root 7.1G Apr 7 15:58 ggml-c4ai-command-r-plus-104b-iq4_xs-00002-of-00002.gguf
C4AI Command R+ IQ4_XS GGUF angespielt
Das folgende Video zeigt, einen Test des C4AI Command R+ IQ4_XS GGUF auf dem Jetson Orin Developer Board mit 64GB mit lama.cpp.
Llama.cpp ist ein Open-Source-Projekt, das darauf abzielt, Large Language Model (LLM) Inferenz mit minimaler Einrichtung und Spitzenleistung auf einer Vielzahl von Hardware, sowohl lokal als auch in der Cloud, zu ermöglichen. Das Projekt hat sich durch zahlreiche Beiträge aus der Community signifikant weiterentwickelt und dient als Laufzeitumgebung für Funktionen der GGML-Bibliothek. Llama.cpp ist ein zentraler Bestandteil der KI-Entwicklung.
Um lama.cpp auf dem Jetson Nano mit CUDA-Support zu installieren kann man folgenden Befehl verwenden. Dadurch wird auch direkt die python Bibliothek installiert, so dass man llama.cpp auch aus Python heraus nutzen kann
https://github.com/ggerganov/llama.cppCMAKE_ARGS="-DLLAMA_CUDA=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
Mit folgendem Befehl kann man llama.cpp main direkt auf der Konsole aufrufen.
#!/bin/sh
main -m gguf/ggml-c4ai-command-r-plus-104b-iq4_xs-00001-of-00002.gguf -p "<BOS_TOKEN><|START_OF_TURN_TOKEN|><|SYSTEM_TOKEN|>Du bist ein KI-Programmierassistent und beantwortest nur Fragen aus dem Bereich der Java Programmierung.<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Schreibe eine Java Methode, welche entscheidet, ob es sich bei der übergebenen Jahreszahl um ein Schaltjahr handelt, oder nicht. Die Jahreszahl könnte man als Integer (int) übergeben, der Rückgabewert der Methode sollte ein Wahrheitswert (boolean) sein.<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>"-n 400 -e --n-gpu-layers 65
Ich verwende den Prompt „Schreibe eine Java Methode, welche entscheidet, ob es sich bei der übergebenen Jahreszahl um ein Schaltjahr handelt, oder nicht. Die Jahreszahl könnte man als Integer (int) übergeben, der Rückgabewert der Methode sollte ein Wahrheitswert (boolean) sein.„, da mich auch die Programmierkenntnisse von Command R+ interessieren. Der Aufruf sieht dann wie folgt aus:
Die IQ4_XS GGUF Variante verwendet nur 4,25 Bit pro Gewicht und liefert in meinen Tests trotzdem gute Ergebnisse, die natürlich auf dem Jetson Nano Developer Board mit den ca. 275 TOPS nicht für Aufgaben geeignet ist, bei denen es darauf ankommt, schnelle Ergebnisse zu erhalten (Siehe Bild).

Leider habe ich nicht die Möglichkeit, das Ergebnis mit dem Original FP32 bzw. FP16 Modell zu vergleichen, so dass ich das Delta von 1.33% zu FP16 aus der Model-Card überprüfen kann. Immerhin konnte ich zeigen, dass es möglich ist, ein 108B Modell auch auf einer sehr kleinen Hardware laufen lassen kann, die sich auch für Privatpersonen leisten können. Allerdings hat das Model den VRAM des Jetson Nano schon an seine Grenzen gebracht und 54,4 der 61,1 GB benutzt. Daher ist es nicht möglich, die Context-Länge von 131072 Token des C4AI Command R+ auszunutzen. Sobald ich die Context-Länge mit dem Parameter „–ctx-size“ auf 12288 setze stürzt das ganze System ab und ich darf (mal wieder) den Reset Knopf drücken.
Fazit
Die GGUF-Quantisierung ermöglicht es, dass Modelle wie das Command R+ trotz starker Quantisierung die Leistungsfähigkeit weitgehend beibehalten können. Was zu einer effizienteren Nutzung der Ressourcen führt und große Open Source LLMs einer breiteren Nutzerbasis zugänglich macht. Selbst bei einer Reduktion der Modellgröße auf 4-Bit wird die die Perplexität nur minimal beeinflusst. Das zeigt, dass die GGUF-Quantisierung die Aufrechterhaltung der Genauigkeit und Relevanz der Modellvorhersagen ermöglicht.
Die Verwendung des C4AI Command R+ Modells und seiner Implementierung auf den Jetson Orin Developer Board zeigt, dass fortschrittliche LLM-Anwendungen auf Hardware mit begrenzten Ressourcen möglich sind, wodurch die Möglichkeiten für mobile und energieeffiziente KI-Anwendungen erweitert werden.
Abschließend lässt sich sagen, dass die Weiterentwicklung und Anwendung der Quantisierungstechnologien nicht nur die Zugänglichkeit und Wirtschaftlichkeit von KI-Systemen verbessern, sondern auch dazu beitragen, die Grenzen der Technologie auf innovative Weise zu erweitern.
Ausblick
Vor ein paar Tagen bin ich über https://github.com/mobiusml/hqq gestolpert. Das Repository enthält die Implementierung von HQQ (Half-Quadratic Quantization), eine Methode zur Quantisierung von Modellen, die eine schnelle und genaue Quantisierung ohne Kalibrierungsdaten ermöglicht. Das werde ich wohl mal ausprobieren und in einem anderen Blog Post darüber berichten.
